Welcome to the Tekin Morning Special Edition for March 6, 2026. This comprehensive intelligence briefing is engineered exclusively for elite hardware analysts, enterprise architects, and global tech investors. Operating at our highest analytical tier (Mega Standard Grade A++), this morning's dispatch transcends superficial headlines to perform a forensic teardown of six seismic shifts. We lead with IBM's revolutionary injection of Agentic AI directly into their FlashSystem storage arrays, boosting data efficiency by 40%. We then dissect Nvidia’
Tekin Morning March 6: From Smart SSDs to the Portable Gaming Inflation Storm
Today is March 6, 2026. Over the past 24 hours, the hardware news cycle has rapidly transitioned from flashy consumer gadgets to hardcore infrastructure engineering and custom silicon architecture. Global tech titans have realized that surviving the AI era necessitates fundamentally redesigning hardware from the transistor level upward. In today’s briefing, we move beyond generic reporting to surgically dissect the engineering innovations and financial impact of these developments on Silicon Valley and the global supply chain.

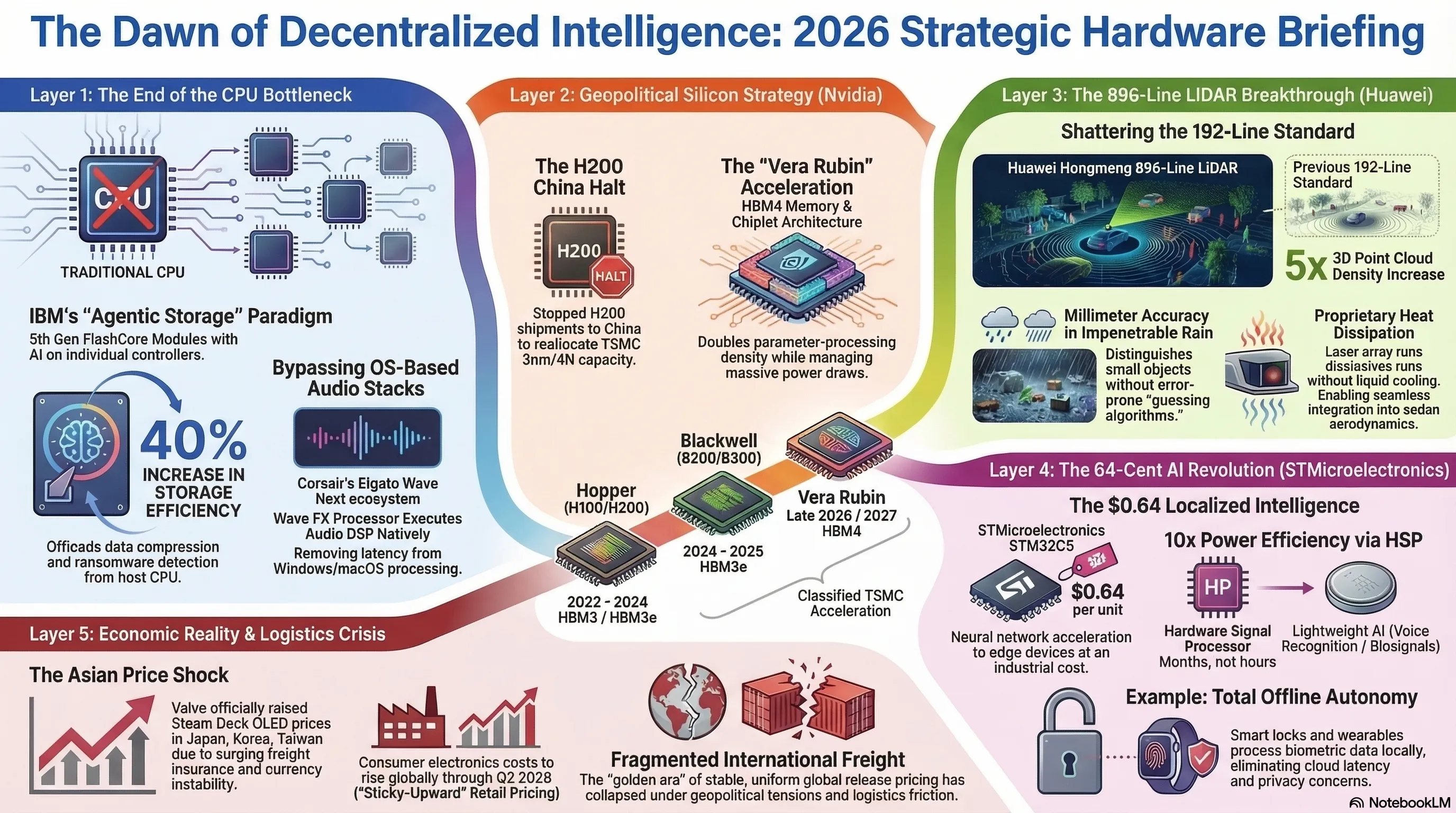
Section 1: Layer 1: IBM FlashCore Autonomous AI — Injecting Intelligence into the Storage Layer to Bypass CPU Bottlenecks
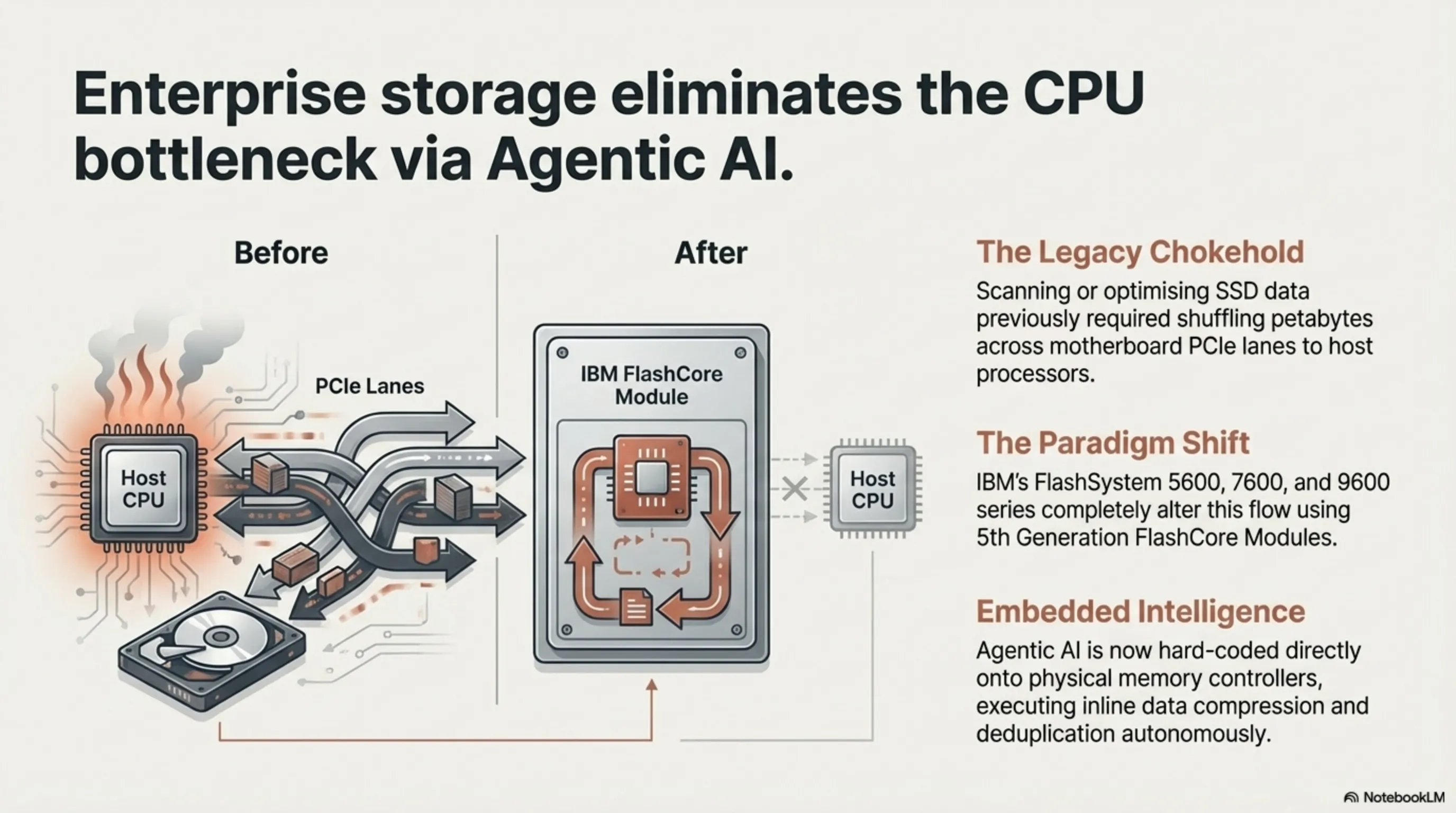
Until today, enterprise data centers faced a critical structural bottleneck: whenever software-level AI attempted to scan, de-duplicate, or optimize vast oceans of data resting on SSDs, that entire traffic load had to cross the motherboard’s PCIe lanes to hit the primary CPU or GPU. This endless back-and-forth shuffling of petabytes resulted in agonizing bandwidth chokeholds and unnecessary thermal throttling. Yesterday, IBM permanently altered this paradigm with the launch of the FlashSystem 5600, 7600, and 9600 series.
1.1 5th Gen FlashCore Modules and Agentic AI Integration
The secret weapon lies within IBM’s 5th generation FlashCore Modules. Rather than relying on the host server’s software, IBM has hard-coded an "Agentic AI" directly onto the physical memory controllers of every individual flash drive. These intelligent silicon agents independently execute real-time, inline data compression, deduplication, and crucially, hardware-level ransomware anomaly detection.
1.2 40% Efficiency Gains and the Enterprise Budget Impact
Published benchmarks confirm a staggering 40% increase in storage data efficiency, entirely offloading that computational tax from expensive host Intel or AMD processors. For international enterprise architects and Silicon Valley cloud operators, this architectural shift is a fiscal lifesaver. As AI dataset sizes explode, mitigating the need to constantly upgrade host CPUs simply to manage storage I/O saves millions in CapEx. If "Agentic Storage" becomes the industry standard, operating systems will no longer need to defragment or scan SSDs; the drive itself will act as an autonomous data sovereign.

Section 2: Layer 2: Nvidia’s Geopolitical Gambler — Halting H200 to China and the Insane Acceleration of Vera Rubin
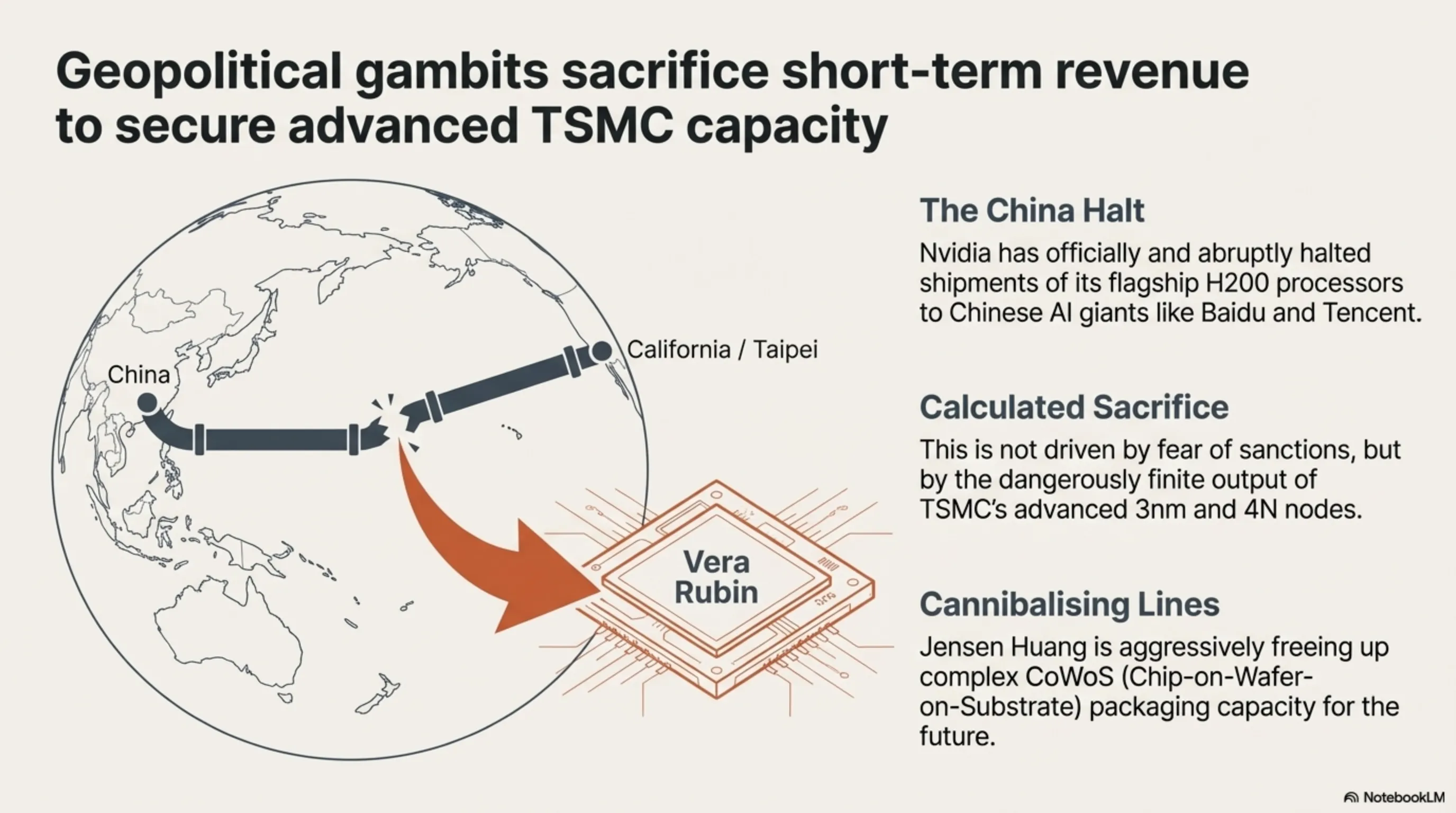
Overnight updates from supply chains in Taipei and executive suites in California have sent a geopolitical shockwave through the global silicon market. Historically, Nvidia attempted to circumvent stringent US Department of Commerce export controls by engineering downgraded chips (like the H20) to capture immense revenue from Chinese AI giants like Baidu and Tencent. However, Nvidia has now officially and abruptly halted the shipment flow of its flagship H200 processors to the Chinese market. This is not out of fear of sanctions; it is a calculated gamble for future dominance.
2.1 Cannibalizing TSMC Lines for the Future
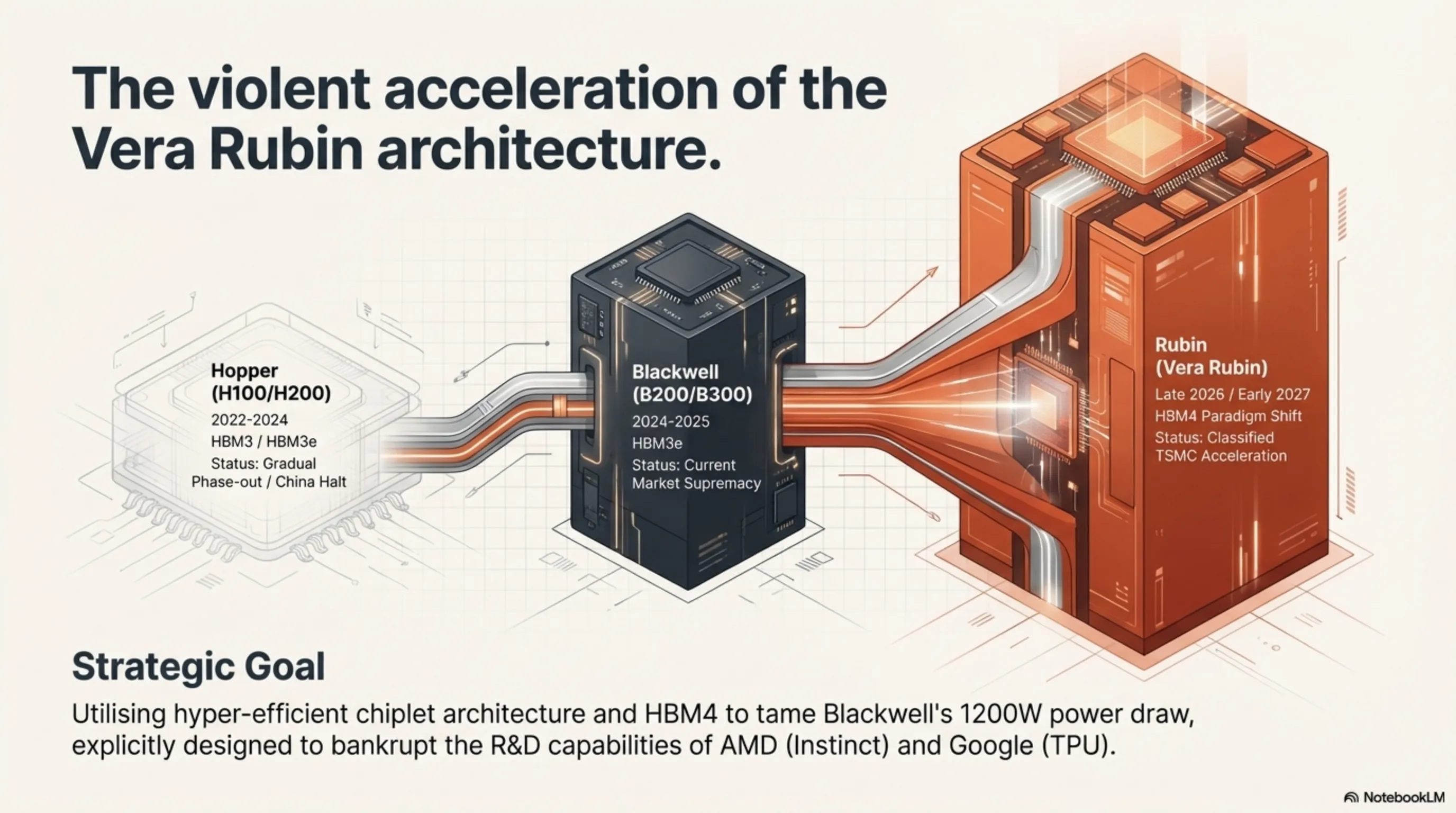
Output from TSMC’s advanced 3nm and 4N nodes is dangerously finite. Nvidia’s strategic calculus dictates that utilizing complex CoWoS (Chip-on-Wafer-on-Substrate) packaging capacity for the increasingly hostile Chinese market is a strategic error. Instead, Jensen Huang is aggressively freeing up those production lines to violently accelerate the manufacturing of Nvidia’s next-generation architecture: "Vera Rubin," slated for an imposing late 2026 reveal.
2.2 Vera Rubin: The Bleeding Edge of Transistor Density
Named after the legendary American astronomer, the upcoming Rubin architecture is designed to completely succeed the Blackwell series (B200/B300) currently dominating headlines. Rubin is projected to utilize ultra-advanced HBM4 (High Bandwidth Memory 4) and a hyper-efficient chiplet architecture to tame Blackwell’s terrifying 1200W power draw while simultaneously doubling the parameter-processing density required for multi-trillion logic training. By severing the Chinese H200 pipeline, Nvidia is ensuring its one-year "ruthless upgrade cycle" remains intact, designed specifically to structurally bankrupt the R&D capabilities of competitors like AMD (Instinct) and Google (TPU).
🔥 Strategic Table: Nvidia Data Center AI Silicon Roadmap
| Silicon Architecture | Initial Release Window | Primary Memory standard | Current 2026 Strategy |
|---|---|---|---|
| Hopper (H100/H200) | 2022 - 2024 | HBM3 / HBM3e | Gradual Phase-out / China Halt |
| Blackwell (B200/B300) | 2024 - 2025 | HBM3e (Massive Volume) | Current Market Supremacy |
| Rubin ("Vera Rubin") | Late 2026 / Early 2027 | HBM4 (Paradigm Shift) | Classified TSMC Acceleration |

Section 3: Layer 3: Shattering Optical Physics — Huawei’s (Hongmeng) 896-Line Lidar for Autonomous Driving
The efficacy of autonomous driving is brutally dependent upon the fidelity of its optical sensors. In automotive optics, LiDAR stands supreme. Last night, Huawei’s Hongmeng Smart Mobility division shattered the physical glass ceiling of environmental detection by unveiling an automotive LiDAR capable of scanning the physical world with a borderline-insane 896 laser lines.
3.1 Destroying the 192-Line Standard and Thermal Limitations
To contextualize this engineering violence: the vast majority of premium autonomous platforms globally (including Western EVs) currently rely on 128 or at best 192-line LiDAR systems. Huawei’s 896-line sensor effectively multiplies the dense 3D Point Cloud generation by a factor of nearly five. This microscopic dot-density allows the vehicle's inference engine to identify small, irregular objects—distinguishing a discarded plastic bag from a crawling animal—with millimeter accuracy in total darkness or impenetrable rain. Furthermore, one of the massive historical constraints of high-density LiDAR has been extreme thermal degradation. Operating hundreds of lasers simultaneously inside a moving vehicle typically melts the optical array or requires bulky active liquid cooling. Huawei’s breakthrough reportedly utilizes a proprietary photon-level heat dissipation matrix and custom metamaterials to keep the 896-line array astonishingly cool and energy-efficient, allowing it to be seamlessly integrated into the aerodynamic profile of standard sedans without massive, ugly roof protrusions.
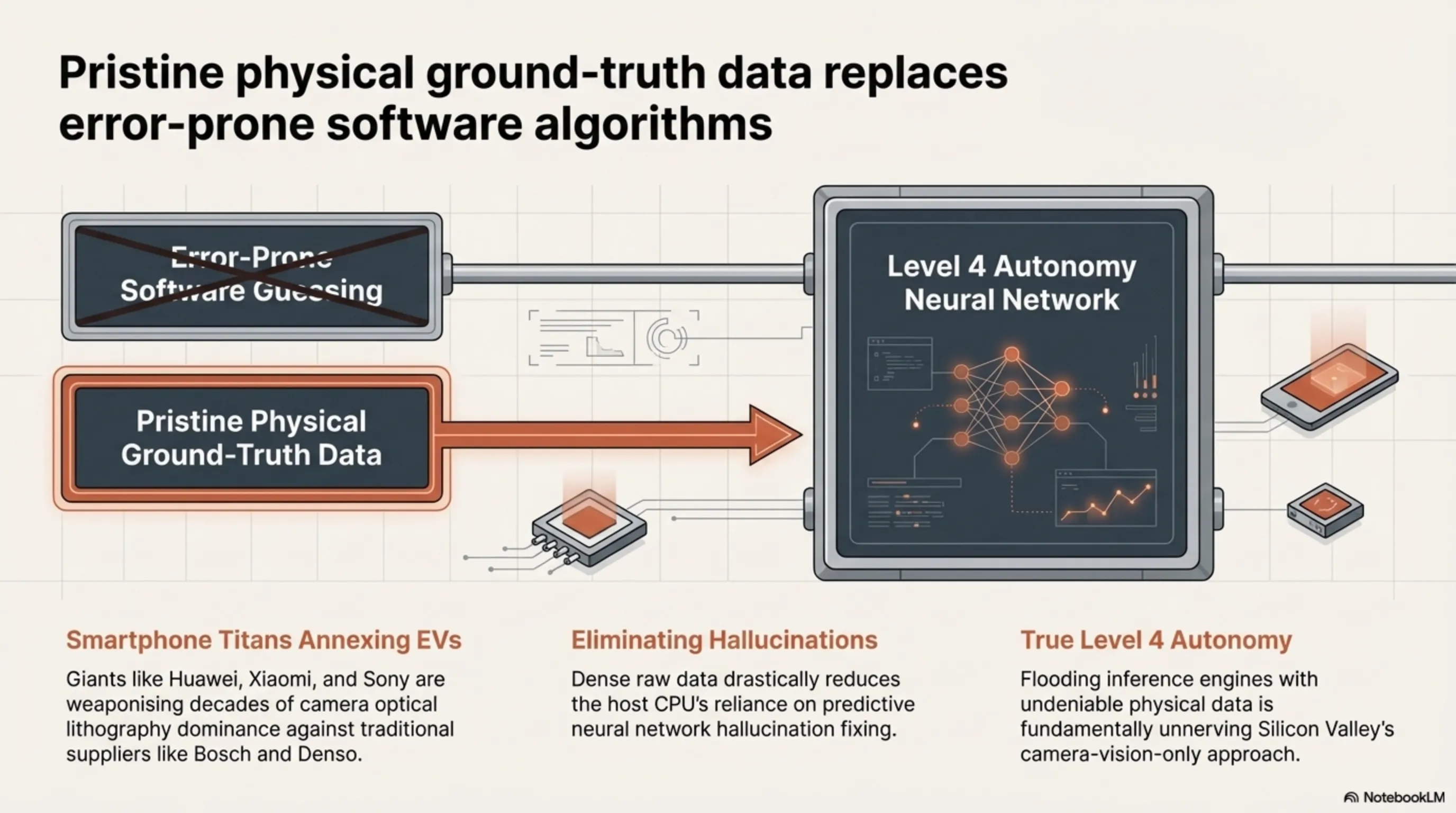
3.2 Smartphone Titans Annexing Automotive Hardware and The Software-Defined Vehicle
This reveals a terrifying reality for traditional automotive suppliers like Bosch, Continental, and Denso. Global smartphone titans (Huawei, Xiaomi, Sony) are actively weaponizing their decades of dominance in camera optical lithography and porting it, at scale, into the EV sector. The 896-line LiDAR drastically reduces the need for the host CPU to run heavy, error-prone "guessing algorithms" or predictive neural network hallucination fixing. Instead, it feeds the autonomous platform the rawest, highest-fidelity physical data possible. This raw data stream is the critical fuel required for absolute Level 4 autonomy. By flooding their neural networks with pristine, undeniable physical ground-truth data rather than relying entirely on camera-vision inference (the Tesla approach), Huawei is pushing Chinese EV capabilities to levels that should fundamentally unnerve Silicon Valley. The transition to the true Software-Defined Vehicle (SDV) is no longer a concept; it is now hard-coded into 896 lines of laser-etched silicon.

Section 4: Layer 4: Corsair’s Custom Silicon (Elgato Wave Next) — The Death of OS-Based Audio DSP Processing
Professional content creation, live streaming, and podcasting require complex audio processing that traditional USB interfaces struggle to handle without introducing system lag. Over the last 24 hours, Corsair (parent company of Elgato) launched the Wave Next ecosystem. The actual revelation is not the new Wave:3 MK.2 mic or the XLR Docks, but Elgato’s aggressive pivot into Custom Silicon design.
4.1 Wave FX Processor: Bypassing Windows and macOS Audio Stacks
Elgato has embedded an internal component designated the Wave FX Processor. Historically, live VST audio effects (hardware compression, noise gates, parametric equalizers, sidechain routing, and AI-driven background suppression) were forcefully processed by your host PC’s CPU via the Windows Audio Session API (WASAPI) or macOS Core Audio. When simultaneously running a heavy AAA video game, capturing 4K video, or multitasking in Adobe Premiere, this OS-level processing induced aggravating latency, audio cracking (buffer underruns), and sapped valuable system resources.
Now, the hardware DSP (Digital Signal Processor) inside the discrete Wave FX chip executes all heavy Wave Link software algorithms natively on the physical dock. The result is studio-processed, zero-latency audio delivered via USB-C to broadcasting software without utilizing a single clock cycle of the host CPU. This fundamental shift upgrades Elgato from a peripheral gaming company into a direct, lethal competitor to entrenched studio hardware giants like Focusrite and Universal Audio. By treating audio streams with the same hardware acceleration that Nvidia treats graphics, Corsair is completely ripping up the rulebook for consumer broadcasting setups.
Section 5: Layer 5: The 64-Cent AI Revolution — STMicroelectronics 40nm Cortex-M33 Microcontrollers with HSP
While mainstream media obsesses over multi-million dollar Nvidia servers, the true volume war in 2026 is occurring at the absolute "Edge" of the network—inside ultra-cheap, battery-operated IoT devices. Early this morning, semiconductor pioneer STMicroelectronics launched its new entry-level STM32C5 series of Microcontrollers (MCUs), fabricated on a hyper-efficient 40nm node.
5.1 Hardware Signal Processors (HSP) on Wearable Silicon
Based on the classic Arm Cortex-M33 architecture, these chips contain a devastating secret: within the STM32U3B5/C5 models lies a dedicated physical co-processor termed the Hardware Signal Processor (HSP). The explicit purpose of this silicon block is the hardwired acceleration of lightweight Neural Network (NN) algorithms and complex mathematical transformations (like Fast Fourier Transforms) for hardware constrained by microwatt power budgets. Usually, running a neural network on a microcontroller drains a coin-cell battery in hours; the HSP reduces that power draw by a factor of ten.
5.2 Offline Intelligence for Under a Dollar: The Pervasive IoT Era
The industrial cost of this computational capability? Exactly $0.64 in lots of 10,000 units. Overnight, electronics engineers can integrate offline Voice Command Recognition (wake words and natural language triggers), local biosignal processing (heart rate variability and oxygen saturation) in ultra-cheap smartwatches, or live-tissue biometric analysis in digital door locks—entirely eliminating cloud internet latency and severe privacy concerns. These sub-dollar 40nm nodes dictate that throughout the rest of this decade, absolutely no "dumb" electronic device will remain without localized Edge Computing capability. From smart thermostats predicting thermal decay, to industrial sensors listening for microscopic bearing failures in factory motors, the 64-cent AI revolution is fundamentally far more transformative for daily human life than an enterprise $40,000 GPU.
Section 6: Layer 6: Asian Price Shock for Steam Deck OLED — Logistics Crisis and Portable PC Market Fallout
Hardware news extends beyond silicon physics into the brutal reality of international logistics and currency valuation. Today, March 6, 2026, Valve Corporation officially and drastically raised the pricing of its unrivaled portable PC, the Steam Deck OLED, across key Asian markets including Japan, South Korea, and Taiwan. Valve’s official declaration cites "intense logistics distribution costs, surging freight insurance, and historical fluctuations in regional currencies versus the US Dollar."
6.1 The Global Domino Effect on Premium Gaming Hardware
For international supply chains and grey-market tech hubs, this localized price hike is a screaming siren. Taiwan serves as the very heart of the global PC component manufacturing apparatus. Raising the Base MSRP in production and distribution hubs directly inflates the profit margins required by import companies globally, from Europe to the Middle East. Given the "sticky-upward" nature of retail electronics—where prices rapidly increase but rarely fall—this pricing shock signifies intense logistical pressure currently suffocating the broader hardware ecosystem. Expected to cascade into premium gaming laptops, next-generation motherboards, and upcoming GPU launches over Q2, this event confirms that the golden era of acquiring premium gaming hardware at globally uniformed, stable release prices is actively collapsing under the weight of fragmented international freight, geopolitical tensions, and persistent inflation.
⚖️ Tekin Final Editorial Verdict
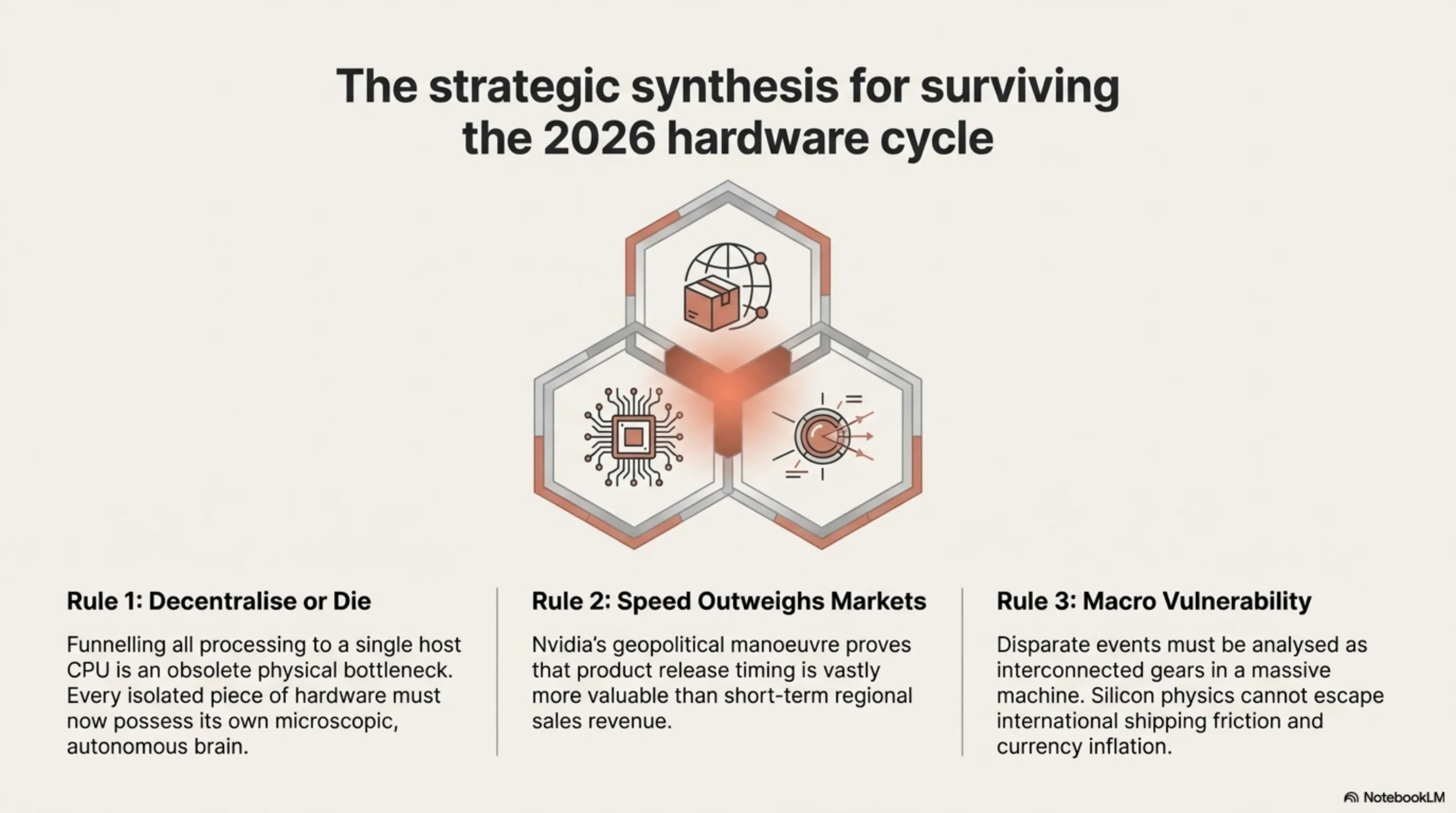
The hardware revelations breaking across March 5 and 6 of 2026 expose a singular, overriding engineering mandate: **The aggressive decentralization of Intelligence.**
The industry has collectively realized that funneling all processing to a single host CPU is an obsolete physical bottleneck. When IBM surgically embeds AI into a tiny flash memory controller to instantly compress data; when STMicroelectronics crams neural networks into a 40nm chip cheaper than a cup of coffee; and when Elgato strips audio processing from Windows to run on a dedicated hardware DSP—they are telegraphing a fundamental architectural shift. *Every isolated piece of hardware must now possess its own microscopic, autonomous brain.*
On a macroeconomic scale, Nvidia’s geopolitical maneuver to abandon Chinese H200 shipments purely to accelerate the Vera Rubin architecture underscores a cold war where product release timing is vastly more valuable than short-term regional sales. Conversely, the logistics-driven price inflation of the Steam Deck OLED in Asia provides a chilling reminder that our most advanced silicon achievements remain profoundly vulnerable to the ancient forces of international shipping friction and currency inflation. For the global elite, surviving this tech cycle demands analyzing these disparate events not as isolated news, but as interconnected gears in a massive, shifting machine.