An in-depth architectural analysis of the 2026 battle for desktop AI supremacy between Intel Core Ultra 200K+ and AMD Ryzen AI PRO 400. We explore how Intel's 3D-stacked L4 cache and AMD's 60 TOPS NPU are fundamentally reshaping personal computing. The article dissects the death of cloud-dependent enterprise AI, the 3nm manufacturing challenges at TSMC, and the arrival of the "AI PC" era where data sovereignty and local inference speed define the new hardware standard.
Part 1: Introduction — Why 2026 Is the Tipping Point for Local Desktop AI
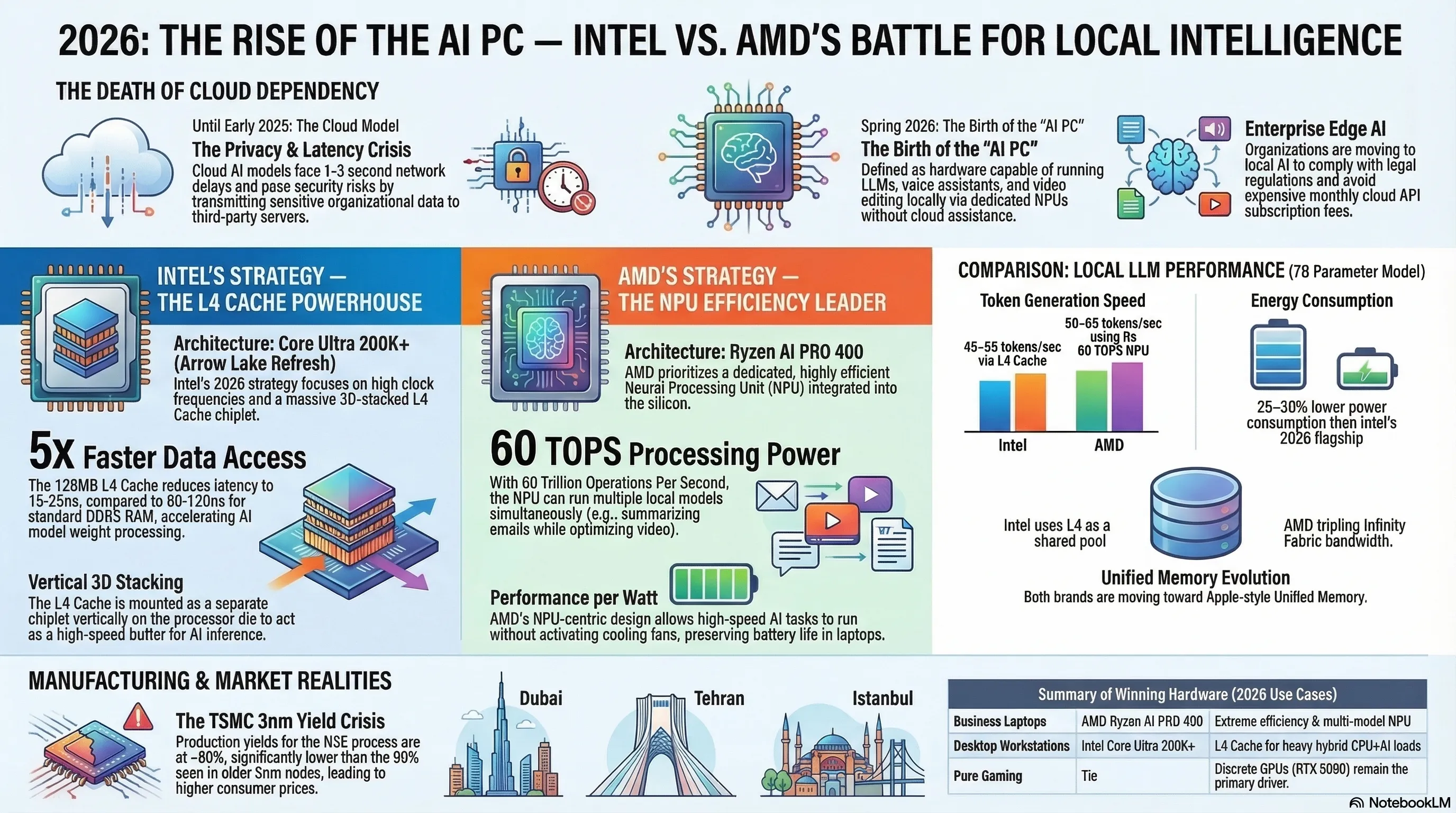
Until the early months of 2025, the concept of "Artificial Intelligence" for the overwhelming majority of desktop and laptop users fundamentally translated into the simple act of dispatching a text query to a remote Cloud server operated by corporations such as OpenAI, Google, or Microsoft. The user would physically type a question, their sensitive data packet would be violently launched across the public internet to a distant datacenter farm, the query would be massively processed by racks of expensive GPUs consuming megawatts of power, and the generated response would eventually trickle back to the user's screen after a perceptible network delay. This deeply entrenched, entirely cloud-dependent workflow suffered from two massive, commercially devastating limitations: Firstly, significant and highly variable Network Latency frequently delaying responses by one to five seconds—a near-eternity in productivity workflows. Secondly, profoundly severe, legally catastrophic data privacy and security vulnerabilities, since every single atomic particle of sensitive corporate, medical, or governmental data was forced to traverse the highly exposed public internet infrastructure and land on the servers of a completely third-party organization.
In the technologically pivotal Spring of 2026, for the absolute first time in the entire history of personal computing, both dominant global chipmaking titans—Intel and AMD simultaneously—aggressively released desktop and laptop processor families fundamentally equipped with massively powerful, deeply integrated Neural Processing Units (NPUs). This monumental hardware event directly implies that commonly used AI models—including intelligent voice assistants, generative image creation engines, automated video editing pipelines, and even moderately sized conversational language chatbots—can now be completely, flawlessly, and entirely executed directly on the user's personal laptop or desktop workstation, demanding absolutely zero internet connectivity and entirely bypassing any cloud server dependency whatsoever. This radical, paradigm-shattering transformation is formally designated "On-device AI" or commercially marketed as the "AI PC" era.
Part 2: Intel Arrow Lake Refresh — The 3D V-Cache L4 Architecture
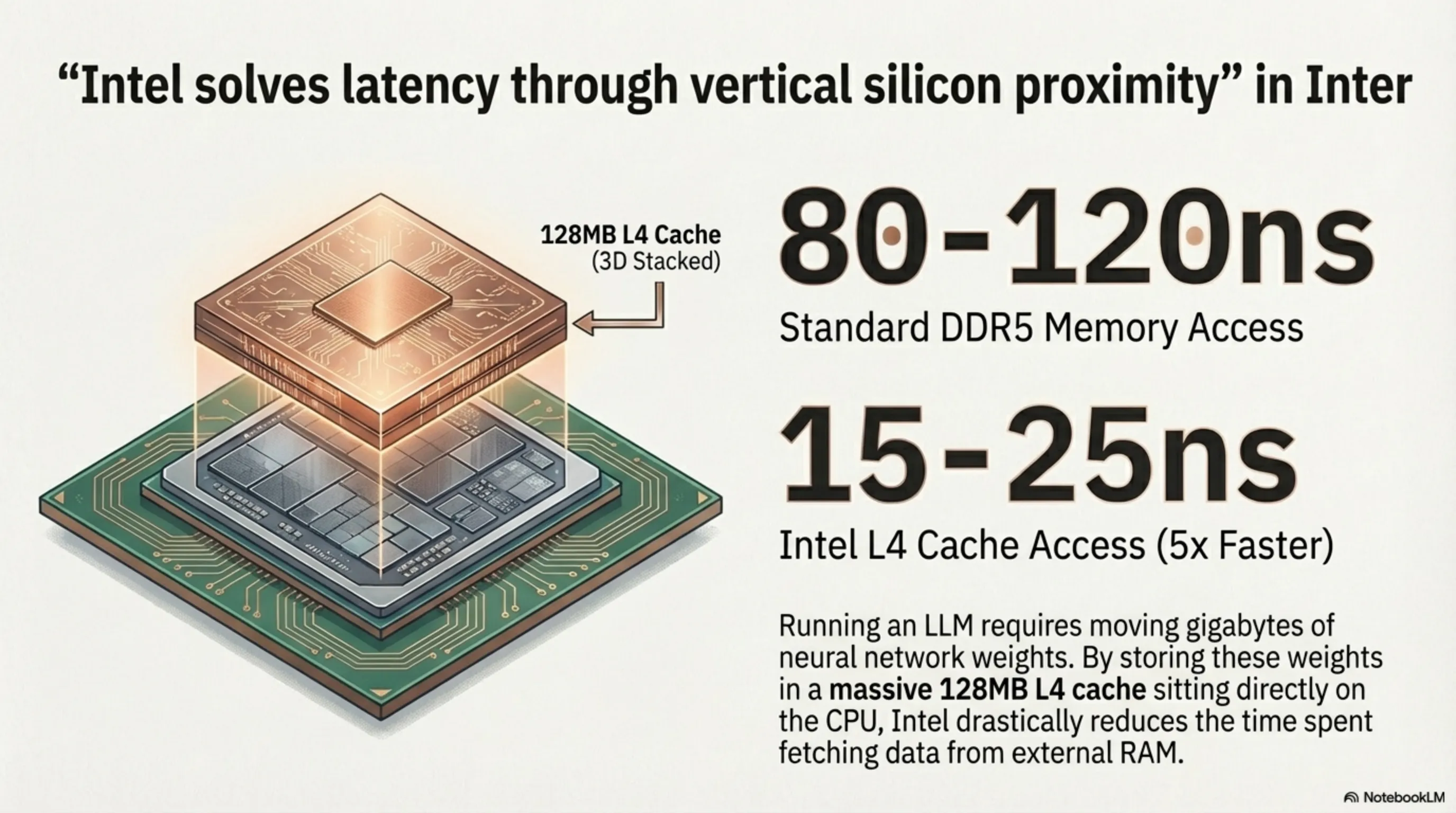
Intel's deeply strategic, aggressively calculated response to the 2026 desktop AI competition is the Core Ultra 200K+ processor family (internally codenamed Arrow Lake Refresh), officially unveiled during Spring 2026. Beyond the expected incremental frequency boosts across the high-performance cores (P-Cores), Intel's genuinely massive, flagship innovation in this generation resides in the unprecedented integration of a colossal Layer-4 Cache (L4 Cache) physically constructed using advanced 3D Vertical Stacking technology (3D V-Cache). This massive cache memory is fabricated as a completely separate silicon chiplet, then physically mounted vertically directly atop the primary processor die using advanced Through-Silicon Vias (TSVs).
The L4 Cache fundamentally operates as a wildly fast intermediate memory buffer sitting aggressively between the processor's compute cores and the system's main DDR5 RAM. While standard DDR5 access latency typically punishes the CPU with delays ranging from 80 to 120 nanoseconds per read operation, Intel's vertically stacked L4 Cache brutally crushes this delay down to approximately 15 to 25 nanoseconds—representing a staggering, near-five-fold performance multiplier. This latency annihilation carries a profoundly devastating impact specifically upon the execution performance of local AI models: When a Large Language Model (LLM) is actively performing real-time inference directly on the processor, the neural network's model weights—which can easily consume several gigabytes of dense numerical data—must be continuously, aggressively shuttled back and forth between the main system RAM and the processor's internal compute units billions of times per second. With 128 megabytes of ultra-fast L4 cache physically bolted adjacent to the cores, a massive, vital portion of these quantized model weights remains permanently cached and instantaneously accessible, radically reducing the catastrophic bandwidth penalty of continuous RAM fetches.
Part 3: AMD's Counter-Offensive — Ryzen AI PRO 400 and Its 60 TOPS Integrated NPU
AMD's strategic philosophical approach to winning the 2026 Desktop AI War is fundamentally, radically divergent from Intel's cache-centric methodology. While Intel concentrated its colossal engineering resources on maximizing the raw L4 cache volume and sustaining aggressive clock frequencies across its general-purpose cores, AMD's Ryzen AI PRO 400 series deposited practically every single one of its architectural eggs into the singular, incredibly dense basket of a dedicated, hyper-specialized Neural Processing Unit (NPU) directly embedded within the monolithic silicon die. The integrated NPU physically fused onto these processors boasts an unprecedented, frankly staggering computational throughput of 60 Trillion Operations Per Second (TOPS) exclusively dedicated to AI matrix operations.

What does 60 TOPS practically translate into for the end user? To locally execute a moderately sized quantized language model (e.g., a 7-billion parameter LLM quantized to INT4 precision), the system typically demands approximately 10 to 15 TOPS of sustained NPU throughput. With a terrifying ceiling of 60 TOPS readily available, the AMD processor is fundamentally capable of simultaneously, concurrently running multiple independent AI models in perfect parallel across entirely different application contexts: one intelligent assistant silently summarizing incoming email threads in the background, a second agent actively analyzing complex financial spreadsheets in real-time, and a third dedicated pipeline continuously processing and enhancing the webcam video feed for a professional conference call—all executing simultaneously without the laptop's cooling fans even registering a discernible increase in RPM speed.
The core decryption of AMD's philosophical approach resides here: Instead of anxiously obsessing over the raw cache hierarchy latency and desperately preventing memory bottlenecks through brute-force silicon stacking, the dedicated 60 TOPS NPU fundamentally operates its own entirely segregated, meticulously optimized computational datapath specifically engineered for dense matrix operations (Matrix Multiply-Accumulate) and high-throughput tensor multiplications. AMD aggressively asserts that this specialized hardware approach delivers massively superior energy efficiency (measured critically as Performance-per-Watt) when stacked directly against the competing alternative of relying entirely on general-purpose CPU cores supplemented merely by massive caches. The NPU was purpose-built from the first transistor for AI mathematics, and its silicon layout inherently consumes optimally balanced electrical power.
Part 4: The TSMC 3nm Factor — Yield Crisis and Silicon Cost Dynamics
Both Intel and AMD are heavily, critically dependent on the advanced 3-nanometer (N3E process node) fabrication lines operated by TSMC (Taiwan Semiconductor Manufacturing Company) in Taiwan for the construction of their most critical chiplets. The vital, commercially devastating issue confronting both corporations is this: The production yield rate of TSMC's 3nm fabrication lines through late 2025 had not yet reached idealized commercial maturity. "Yield Rate" precisely quantifies the percentage of transistors across each extremely expensive monocrystalline silicon wafer that emerge from the intense lithographic process without crippling physical defects. At the brutally unforgiving 3nm scale, a single stray atomic dust particle routinely destroys an entire functioning chip worth thousands of dollars.
When yield rates remain comparatively depressed, the effective manufacturing cost per healthy, sellable chip aggressively skyrockets. Deeply sourced supply chain intelligence aggressively surfacing from DigiTimes during Spring 2026 indicates that N3E yields have stabilized at approximately 80 percent (compared against the considerably more comfortable 85 to 90 percent yields typically achieved on the older, more mature 5nm nodes). This seemingly minor 10-percentage-point differential injects billions of additional manufacturing costs across the global silicon supply chain, directly and unavoidably impacting the final retail pricing strategy of both the Core Ultra 200K+ and the Ryzen AI PRO 400 for the end consumer, effectively keeping their launch pricing notably elevated above initial market expectations.
Part 5: The Death of Cloud-Dependent Enterprise AI
One of the absolute most potent commercial drivers fueling this intense hardware arms race is the massive, growing, near-desperate pressure exerted by the global Enterprise sector to violently liberate itself from its total, crippling dependency on remote cloud-based AI processing services. Large law firms handling privileged attorney-client cases, investment banks processing classified merger negotiations, hospitals managing intensely sensitive patient health records governed by HIPAA, and national governmental agencies processing classified citizen data physically and legally cannot transmit their confidential datasets to the servers of Microsoft, Google, Amazon, or any other third-party cloud operator.
The dramatic entrance of brutally powerful NPU-equipped processors such as the Core Ultra 200K+ and the Ryzen AI PRO 400 into the commercial market fundamentally enables the complete, end-to-end local execution of language models, data analysis pipelines, and automated document processing directly on the employee's own laptop or high-performance workstation. The sensitive data never leaves the physical chassis of the machine. This revolutionary model, formally designated as "Edge AI," is in the active, aggressive process of functionally annihilating the multi-billion-dollar industry previously built entirely around selling monthly cloud API subscription access. Enterprises no longer require paying the staggering, continuously escalating monthly server fees. This alone constitutes a fundamental, violent economic restructuring of the entire enterprise software market, and both Intel and AMD are investing billions to capture the largest possible share of this seismic commercial transition.

Part 6: Unified Memory Architecture on x86 — Lessons from Apple Silicon
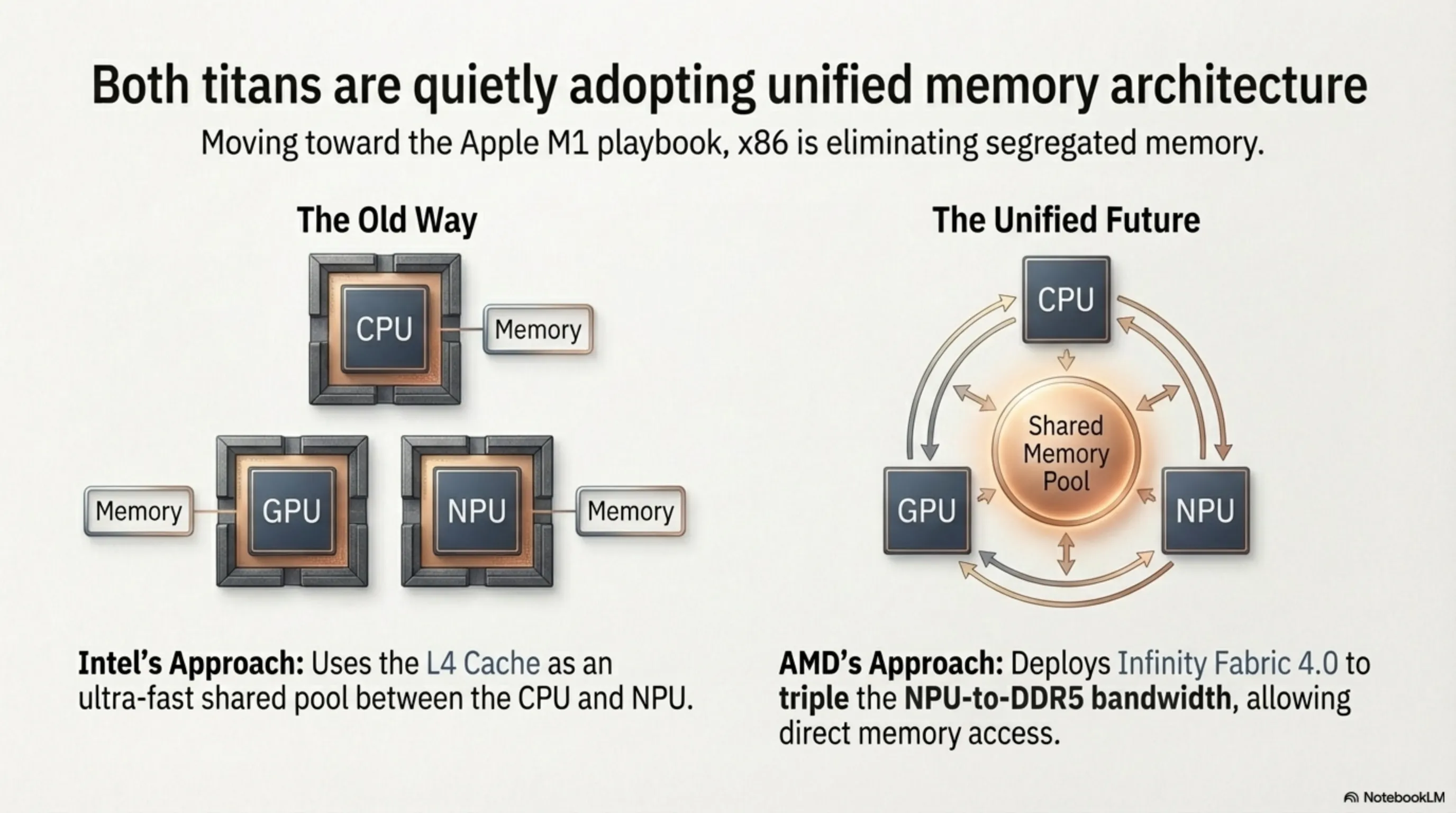
One of the most consequential yet vastly underreported architectural shifts in the 2026 processor generation is the slow, deliberate migration toward a Unified Memory Architecture (UMA). This paradigm was fiercely popularized by Apple's M1 silicon back in 2020, where the CPU, GPU, and NPU abandoned their isolated memory pools to share a single, incredibly high-bandwidth monolithic memory block. This structural convergence radically eliminates the crippling latency of constantly duplicating datasets between different chips.
In their 2026 flagship architectures, both Intel and AMD have adopted aggressive, albeit cautious, steps toward this x86 holy grail. Intel's massive L4 Cache functionally serves as an ultra-fast shared memory pool specifically bridging the CPU cores and the dedicated NPU. Simultaneously, AMD revamped its Infinity Fabric interconnect (IF 4.0), successfully tripling the bidirectional bandwidth between the NPU and the DDR5 memory controller. While neither has fully achieved Apple's absolute monolithic integration, the trajectory is unmistakable: the future of x86 is the total convergence of CPU, GPU, and NPU over a unified, blistering-fast memory substrate.
Part 7: Cache Latency Mechanics and Local LLM Token Generation Speed
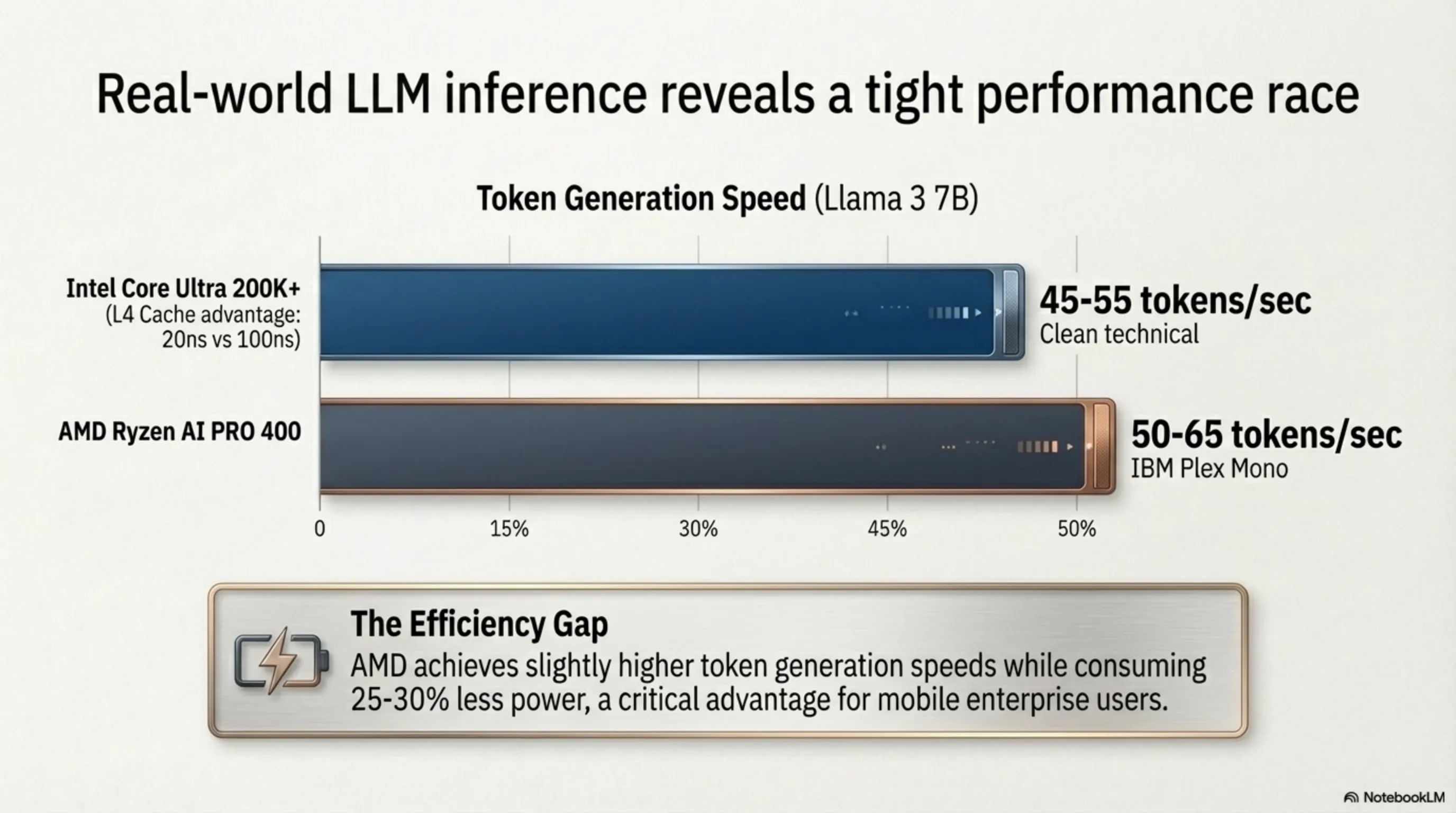
For technically inclined readers, let us precisely explain why cache speed matters this dramatically for desktop AI execution. When a quantized Large Language Model (for example, a Llama 3 7-billion-parameter model compressed to INT4) is actively running inference on your local processor, every single generated token (each word or word fragment produced by the model) mandates the aggressive sequential reading of hundreds of megabytes of neural network weight data from memory. If these weights reside in standard DDR5 system RAM, each individual fetch operation is penalized by approximately 100 nanoseconds of latency. However, if these identical weights are cached within Intel's L4 tier, this access delay plummets to merely 20 nanoseconds.
This 80-nanosecond differential, when brutally multiplied across billions of mandatory matrix multiplication operations executed per second during active inference, transforms into a profoundly critical, commercially meaningful difference in end-user-visible Token Generation Speed (measured in tokens per second or tok/s). Early benchmark data cautiously surfacing from multiple independent hardware reviewers in Spring 2026 indicates that the Core Ultra 200K+ armed with its L4 cache can execute a standard 7B parameter quantized model at approximately 45 to 55 tokens per second, while AMD's Ryzen AI PRO 400 with its 60 TOPS NPU executes the identical model at approximately 50 to 65 tokens per second. Critically however, the AMD processor achieves this slight raw speed advantage while simultaneously consuming 25 to 30 percent less total system power—a difference of astronomically vital importance for battery-powered laptop deployment, where every single milliwatt of efficiency directly translates into additional minutes of productive, untethered mobile runtime.
Part 8: Software Ecosystem — Windows Copilot+ vs. Open ONNX Runtime
Hardware without optimized software is merely an expensive, inert silicon paperweight. The definitive, commercially decisive battleground of the 2026 Desktop AI War will ultimately be decided not purely by raw TOPS specifications or cache sizes, but by the depth, maturity, and developer adoption of the supporting AI software ecosystem. Microsoft's Windows Copilot+ initiative—deeply, structurally tied to Intel's NPU architecture—provides a tightly integrated, heavily curated set of system-level AI capabilities (live captions, intelligent search, image generation assistants) directly baked into the Windows 12 operating system.
Conversely, AMD has aggressively championed the entirely open-source ONNX Runtime pipeline coupled with the ROCm software stack, enabling developers to deploy practically any custom AI model architecture directly onto the Ryzen NPU without vendor lock-in. This open-versus-closed software ecosystem war mirrors the historical Android-versus-iOS philosophical conflict. For enterprise buyers, the open ONNX approach typically wins because it allows internal engineering teams to deploy custom, proprietary AI models trained exclusively on their own data. For consumer users who simply want "AI features to work out of the box," Microsoft's Copilot+ integration delivers a frictionless, plug-and-play experience.
Part 9: Wall Street's Perspective — Which Architecture Drives Future Stock Value?
The financial markets and institutional investors have been ruthlessly analyzing this architectural divergence through the cold lens of long-term profitability. Wall Street analysts recognize that the desktop AI processor market is not merely about consumer benchmarks, but fundamentally about dictating the technological standards that will eventually filter up to the explosive multi-trillion-dollar datacenter server racks.
Investors currently view AMD's hyper-focus on NPU efficiency as a direct, aggressive defensive maneuver against ARM-based competitors like Qualcomm, securing a massive moat in the lucrative enterprise notebook sector. Conversely, Intel's massively expensive gamble on 3D vertically stacked L4 caches is perceived by the market as a high-risk, high-reward strategy engineered to maintain absolute supremacy in high-margin desktop workstations and gaming rigs. Whoever successfully standardizes their localized AI software ecosystem among global developers within the next 24 months will ultimately capture the lion's share of future x86 market capitalization.
Part 10: Structural Conclusion — Who Wins the 2026 Desktop AI War?
The honest, brutally transparent final verdict from our engineering desk does not declare either combatant a universal champion. Instead, the 2026 Desktop AI War has cleaved the market into two drastically distinct hardware philosophies, each commanding overwhelming supremacy within its own specific operational domain. For enterprise-class laptops prioritizing energy efficiency, sustained multi-model concurrent execution, and long battery life, AMD's Ryzen AI PRO 400 with its massively specialized 60 TOPS NPU represents the definitively superior hardware platform. For high-performance desktop workstations demanding raw computational horsepower, heavily mixed CPU+AI workloads, and maximum single-thread performance for creative professionals, Intel's Core Ultra 200K+ with its revolutionary 3D-stacked L4 Cache delivers unmatched, devastating throughput.
For pure gaming enthusiasts, neither platform's NPU capabilities provide measurable uplift—discrete GPUs such as the RTX 5090 continue to exclusively dictate gaming performance. The profoundly transformative macro-conclusion embedded within this war extends far beyond silicon specifications: The year 2026 permanently marks the historical moment when artificial intelligence officially migrated out of the distant cloud and landed physically beneath the user's fingertips. The aggressive competition between Intel and AMD will not only systematically drive prices downward and NPU capabilities exponentially upward, but it will violently overthrow the entire commercial model of the enterprise software industry—an industry that until recently was entirely and hopelessly addicted to billing corporations massive monthly cloud API subscription fees. The AI PC era has officially, irreversibly arrived.

Final Editorial Verdict: Who Wins the 2026 Desktop AI Championship?
Enterprise Laptop Champion: AMD Ryzen AI PRO 400 (60 TOPS NPU with exceptional power efficiency makes it ideal for sustained local AI workloads on battery.)
Desktop Workstation Champion: Intel Core Ultra 200K+ (3D L4 Cache + high clock frequencies deliver devastating performance in heavy mixed CPU+AI workloads.)
Pure Gaming Champion: Neither — Draw (Local NPU and on-device AI currently provide zero measurable uplift for pure gaming; discrete GPUs like the RTX 5090 continue to exclusively dominate.)
Final Tekin Analysis: 2026 is the year AI officially exited the cloud and landed directly under the user's fingertips. The fierce Intel-AMD rivalry will drive prices down while pushing NPU power exponentially upward, violently overthrowing the multi-billion-dollar enterprise cloud API subscription industry. The AI PC era has irreversibly arrived.
Special AI PC Revolution Gallery