A deep-dive analysis of the 2026 industrial migration to PCIe 6.0 and CXL 3.2 architectures. We examine how PAM4 signaling and Forward Error Correction (FEC) overcome the physical limitations of copper to deliver 128 GB/s bandwidth. The article explores the CXL-driven revolution in memory disaggregation, the critical role of 3nm Retimer silicon, and the massive infrastructural shift toward liquid cooling and active optical cables (AOC) in modern AI super-clusters.
Part 1: Introduction and the Abrupt, Violent End of the PCIe Gen 5 Reign
Throughout the deeply formative years of late 2024 and bleeding into 2025, the grand unveiling and subsequent massive deployment of enterprise server processor architectures fundamentally equipped with brutal PCIe 5.0 bus routing was almost universally heralded as a definitive, generation-defining hardware milestone. The sheer physical doubling of raw interconnect bandwidth from the aging strictures of PCIe 4.0 logically, mathematically appeared to generously satisfy the insatiable data-transfer demands of modern hyper-scale servers for at least the remainder of the decade.
However, driven brutally by the unprecedented, shockingly violent explosion in the commercial training of hyper-massive Large Language Models (LLMs)—frequently eclipsing the staggering one-trillion parameter threshold—and the absolute consequent necessity for incomprehensible, continuously sustained ultra-heavy graphical processing (GPU) throughout 2025 and directly into 2026, the elite silicon architects entrenched within titans such as Nvidia, AMD, and Broadcom violently collided head-first with a terrifying, immutable engineering reality. It became immediately, mathematically apparent that even possessing a bus speed of 32 GigaTransfers per second (GT/s) was rapidly, terrifyingly mutating into a catastrophic, fatal physical bottleneck (Bottleneck Constraint) actively choking the life out of multi-million dollar AI training clusters.
Immensely powerful, modern flagship graphical processing units—most notably Nvidia’s monstrous Blackwell lineage (an architecture whose heavily restricted export dynamics aggressively destabilized specific Asian tech sectors recently)—ferociously consume and exhaust localized tensor data at a pace previously considered physically impossible. These specific, elite AI processors are fundamentally so unbelievably potent that, during the intensive, sustained loading and executing stages of multi-billion parameter foundation models, they possess the capacity to definitively, violently saturate the absolute entirety of a server motherboard's available PCIe 5.0 lanes, plunging them into a sustained state of 100% capacity gridlock in a mere fraction of a solitary second.
Therefore, in the pivotal Spring of 2026, the official localized response heavily mounted by the global enterprise server industry to aggressively combat this severe physical crisis is the coordinated, absolutely massive operational migration toward the radically advanced PCIe Gen 6.0 standard. This entirely unyielding new standard does not merely superficially double the raw transfer speed to an agonizingly fast 64 GigaTransfers per second; far more fundamentally, it introduces an entirely divergent, violently different base architecture for encoding and physically transmitting vital bit-streams directly across printed circuit boards and dense fiber networks.
Part 2: The Architecture of PAM4 Signaling: Decimating Physical RF Limitations
From the absolute foundational inception of the very first iteration of the PCIe standard over roughly two decades ago, continuing uninterruptedly all the way up until the deployment of the Gen 5 specification, absolutely every single iteration loyally, unquestioningly relied upon a highly distinct, classical digital signal encoding methodology strictly known as NRZ (Non-Return-to-Zero). Fundamentally, within the rigid NRZ architecture, the system solely recognizes and relies upon merely two drastically polarized voltage levels: a distinctively High Voltage pulse (which the processor actively interprets and calculates as a binary Bit 1), and a distinctively Low Voltage pulse (calculated mathematically as a binary Bit 0).
The brutal, insurmountable engineering wall obstructing this specific methodology was that the fundamental, unyielding laws of quantum physics and electromagnetism flatly refuse to allow engineers to simply accelerate and inflate the underlying physical Carrier Frequency over standard copper wirings and fragile PCB traces up to infinite levels. Aggressively expanding and increasing the physical voltage frequency beyond strict mathematical tipping points inevitably triggers the highly destructive phenomenon known technically as "Insertion Loss" and causes massive "Signal Degradation", where the frequency wave itself violently destructs and dissolves while traveling the physical length of the cable or across the motherboard.
To ruthlessly circumvent and effectively annihilate this severe physical limitation without abandoning copper entirety, the brilliant elite engineers composing the global PCI-SIG consortium executed a remarkably violent architectural pivot during the fundamental drafting of the PCIe 6.0 baseline. They made the definitive, unyielding decision to completely discard the archaic NRZ methodology directly into the dustbin of computing history, and alternatively mandated the wildly advanced Pulse Amplitude Modulation 4-level (PAM4) architecture to be implemented aggressively across all core server communication lanes.
Instead of utilizing a mere two basic voltage levels, the sophisticated PAM4 topology actively weaponizes four completely distinct, meticulously separated physical voltage levels (interpreted sequentially as 00, 01, 10, 11). This incredibly profound physical alteration definitively implies that during absolutely every single solitary fluctuation of the internal signal wave (each individual Clock Cycle), the hardware simultaneously, synchronously transmits two entirely independent bits of data per lane, directly replacing the previous limitation of merely one.
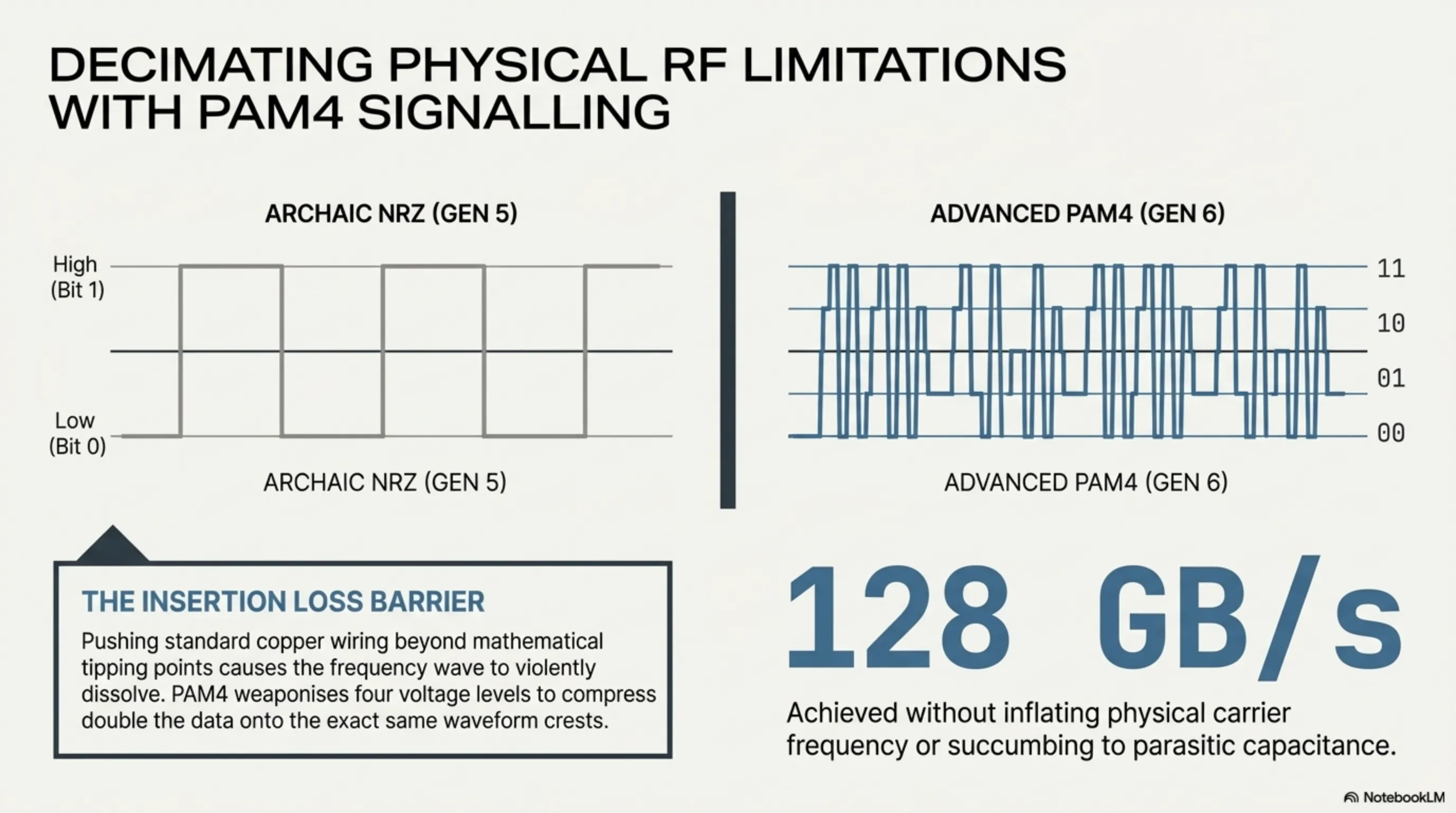
To translate this brutal engineering into straightforward commercial vernacular: The PCIe 6.0 architecture has successfully, completely doubled the raw operational bandwidth to a truly awe-inspiring, utterly staggering 128 Gigabytes per second (specifically when operating fully in a standard bi-directional x16 slot configuration). Most critically, it successfully executes this miraculous leap entirely without forcing the underlying physical waveform frequency traveling across the copper wiring to become substantially more erratic or hostile than it already was under PCIe 5.0. It achieved this merely by deeply, densely compressing considerably more analytical information directly onto the literal crests of the waveform—a phenomenal, undefeated absolute victory of pure logic design against the restrictive physical limitations of electrical resistance and parasitic capacitance.
Part 3: Forward Error Correction (FEC): The Mathematical Shield Against Signal Death
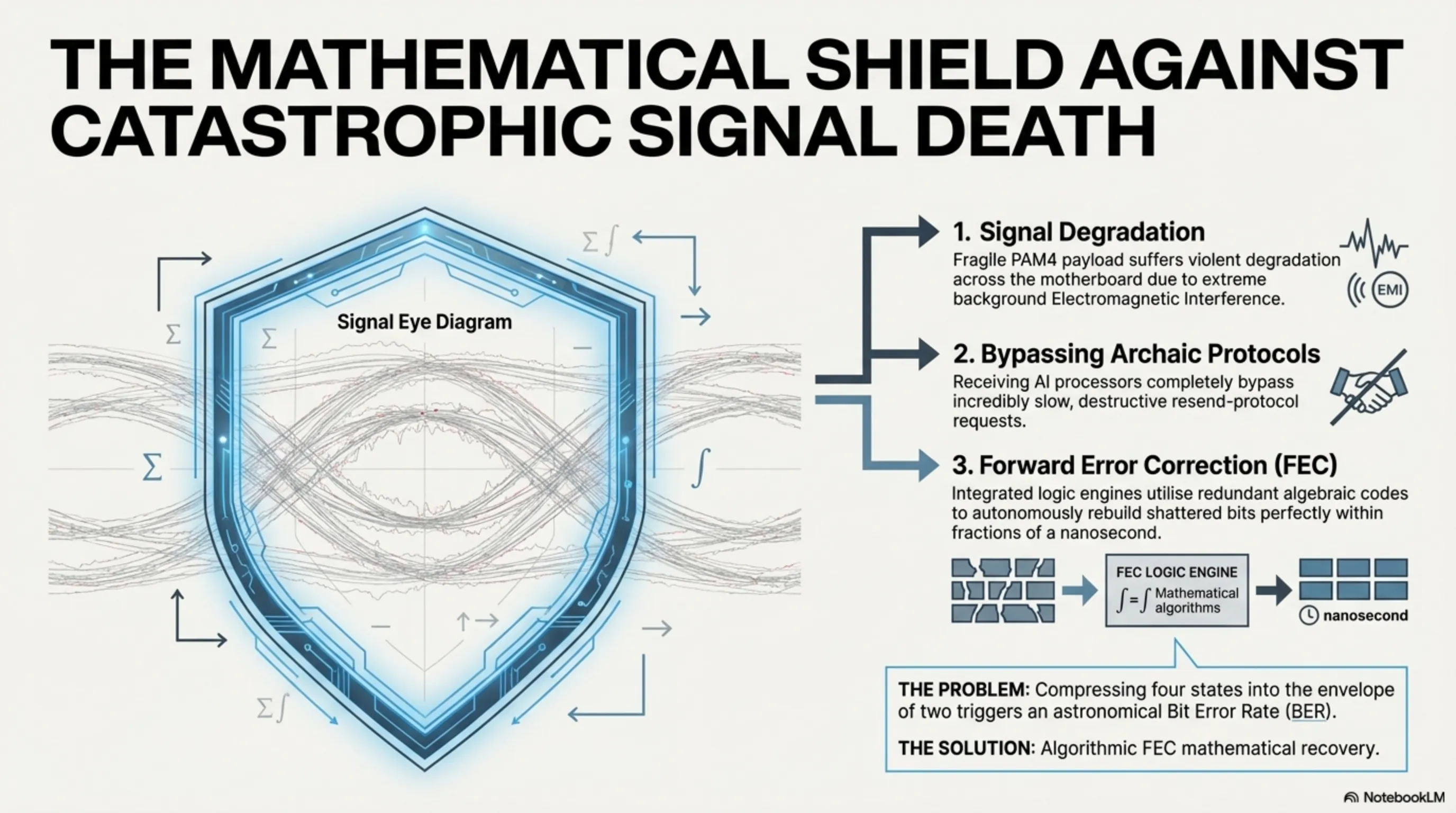
However, within the notoriously unforgiving, relentlessly harsh world of elite silicon engineering, absolutely no monumental leap forward is granted freely without extracting a severe subsequent toll. When an architecture aggressively decides to wedge four specific, precise voltage states into the exact same microscopic physical electrical envelope that previously housed only two, the distinct "Voltage Distance" naturally residing between these new designated levels compresses drastically (a symptom formally known as the severe shrinking of the Signal Eye Diagram).
This highly compressed, densely packed state inherently forces the transmitting signals to become profoundly, wildly susceptible and fragile concerning any ambient Electromagnetic Interference (EMI) or background noise. Consequently, the fundamental internal Bit Error Rate (BER) natively inherent to PAM4 transmission skyrockets astronomically compared to archaic systems; in layman's terms, the receiving server processor constantly, continuously reads the incoming data wildly incorrectly due to severe noise pollution.
To perfectly prevent the total, catastrophic collapse of the entire networking system, the PCIe 6.0 baseline specification officially, aggressively mandated the deep logical integration of a dedicated mathematical recovery unit formally designated "Forward Error Correction" (FEC). Within this paradigm, the originating data transmitter actively bundles and injects incredibly dense, complex algebraic recovery codes and redundant recovery logic directly alongside the primary data payloads.
Consequently, when the payload inevitably suffers violent degradation during physical transit across the motherboard and several individual digital bits are irrevocably crushed or scrambled by noise, the receiving GPU—rather than triggering an incredibly slow, painfully expensive, and highly destructive "Resend Protocol Request"—entirely autonomously engages its integrated mathematical FEC logic engines. It actively utilizes the bundled algorithmic formulas to instantly, seamlessly guess, rebuild, and perfectly repair the ruined bit accurately within mere fractions of a solitary nanosecond. The uncompromising, unified marriage of the dense PAM4 frequency architecture firmly bound with the hyper-intelligent FEC mathematical correction engine serves unequivocally as the absolute, definitive bedrock keeping heavy datacenter networks fundamentally alive and violently stable throughout 2026 and vastly beyond.
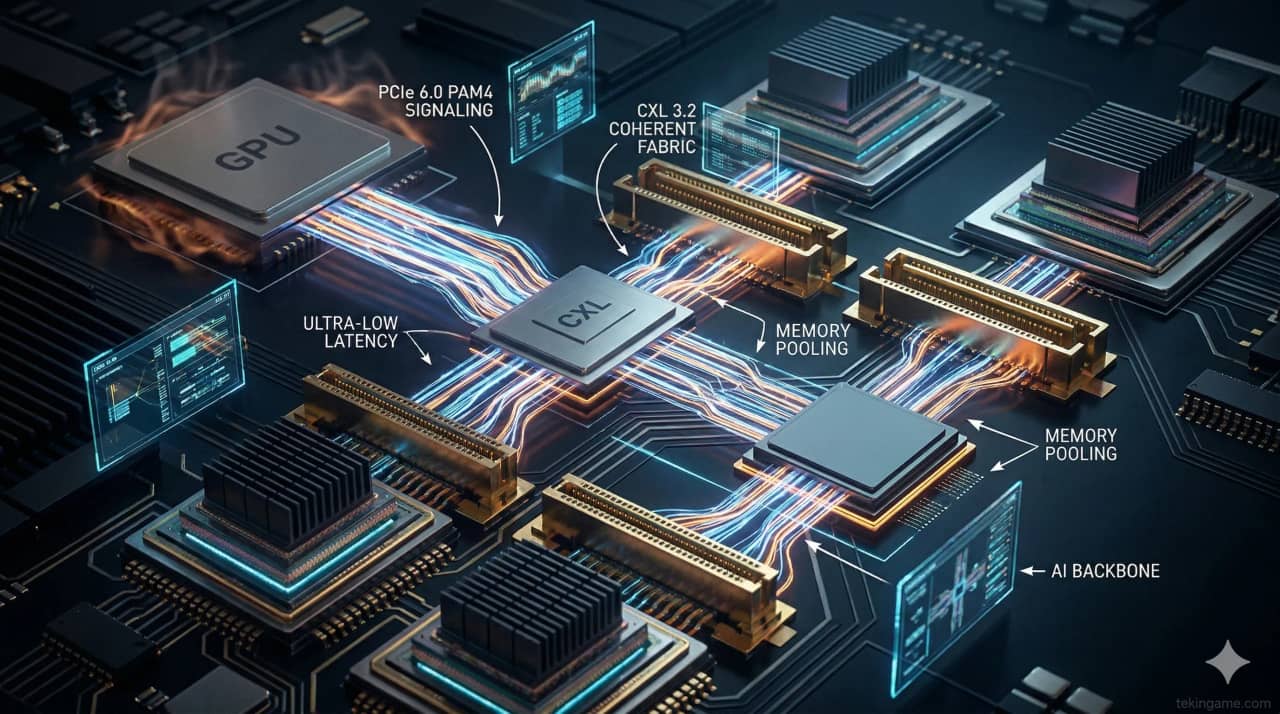
Part 4: The CXL 3.2 Revolution: Memory Disaggregation and Fabric Switching
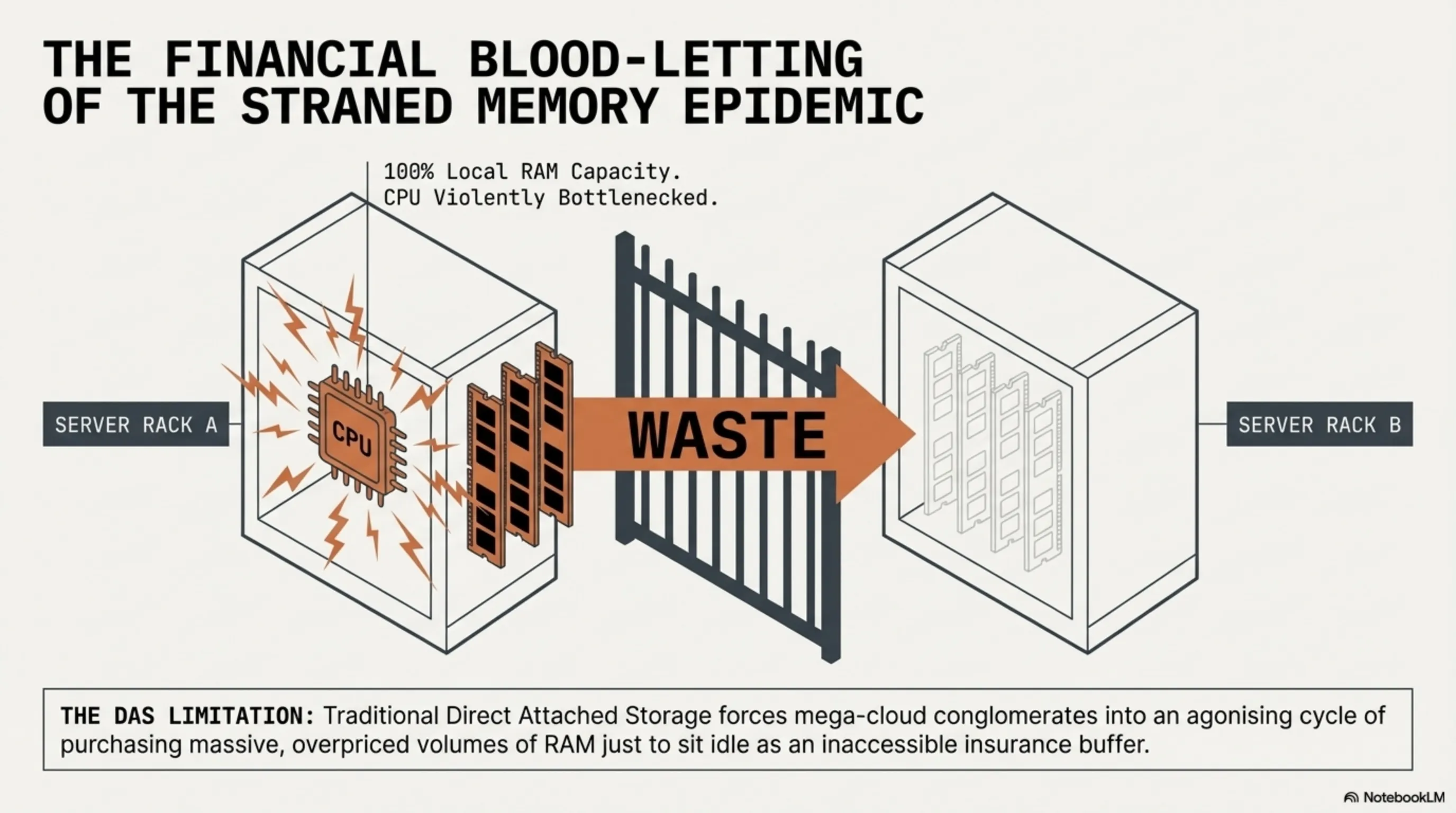
The colossal datacenter revolution actively manifesting throughout 2026 fundamentally refuses to be constrained solely by raw, brutish increases in sheer transfer speed; its ultimate, most profound impact resides deeply within the total physical dismantlement and radical re-architecting of System Memory itself, propelled aggressively by the total maturation of the Compute Express Link (CXL) hardware standard. The CXL protocol natively rides directly upon the precise physical copper traces and deep slot infrastructure mandated by PCIe 6.0, yet its ultimate, unrelenting mission is to definitively murder the catastrophic corporate financial blood-letting known as the "Stranded Memory Epidemic" heavily plaguing global cloud infrastructure.
Within deeply traditional, classically constructed server environments (utilizing standard Direct Attached Storage topologies), every single solitary Central Processing Unit (CPU) securely retains its own rigidly fenced, entirely exclusive array of Random Access Memory (RAM). Consequently, if Processor Node Alpha suddenly requires an aggressive, massive injection of temporary memory to compile an expansive algorithm, yet its local physical memory DIMM slots are heavily saturated at 100% capacity, it absolutely cannot borrow or access the entirely vacant, wholly unused RAM sitting idle on Processor Node Beta located across the server rack. This incredibly archaic physical limitation actively forces multi-billion dollar mega-cloud conglomerates into a vicious, deeply agonizing cycle where they must constantly, endlessly purchase massive volumes of heavily overpriced RAM merely just to sit idle as an "insurance buffer," heavily wasting capital.

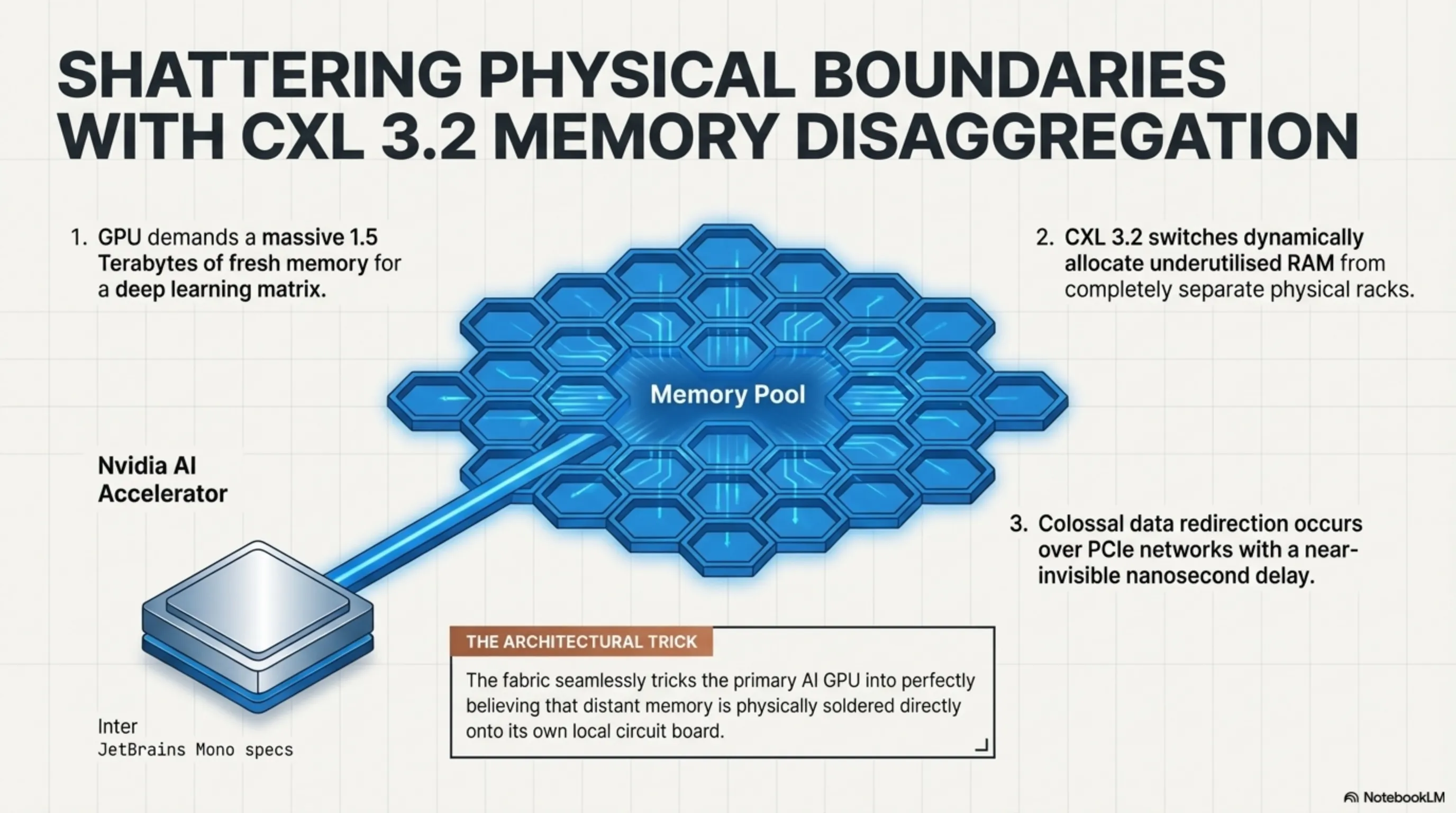
However, with the aggressive enterprise deployment of the highly evolved CXL 3.2 specification fully realizing the concept of "Memory Disaggregation" (and its sibling, Deep Fabric Switching), the architecture completely shatters this limitation. Now, utilizing ultra-dense CXL 3.2 switches located at the absolute hyper-core of elite 2026 global datacenters, the localized, isolated RAM capacities spanning dozens of entirely separate physical server racks are fundamentally, logically dissolved and magically unified into one singular, colossal, seamless, continuous "Memory Pool."
If a wildly expensive Nvidia AI Accelerator housed in Server Rack A abruptly mandates the immediate injection of 1.5 Terabytes of fresh memory to aggressively crunch a deep learning matrix, the unified CXL controller actively, dynamically, and seamlessly allocates the necessary volume directly from the heavily underutilized memory sticks physically residing inside Server Rack D. It executes this colossal data redirection directly across the PCIe network cabling with an agonizingly small, near-invisible delay measuring merely in nanoseconds—tricking the primary AI GPU into perfectly believing that the distant, far-away memory is physically soldered directly onto its own internal local circuit board! This singular breakthrough represents a violently efficient, utterly merciless revolution against archaic, bloated hardware expenditure budgets.
Part 5: Silicon Middlemen: Astera Labs, Microchip, and the Retimer Monopoly
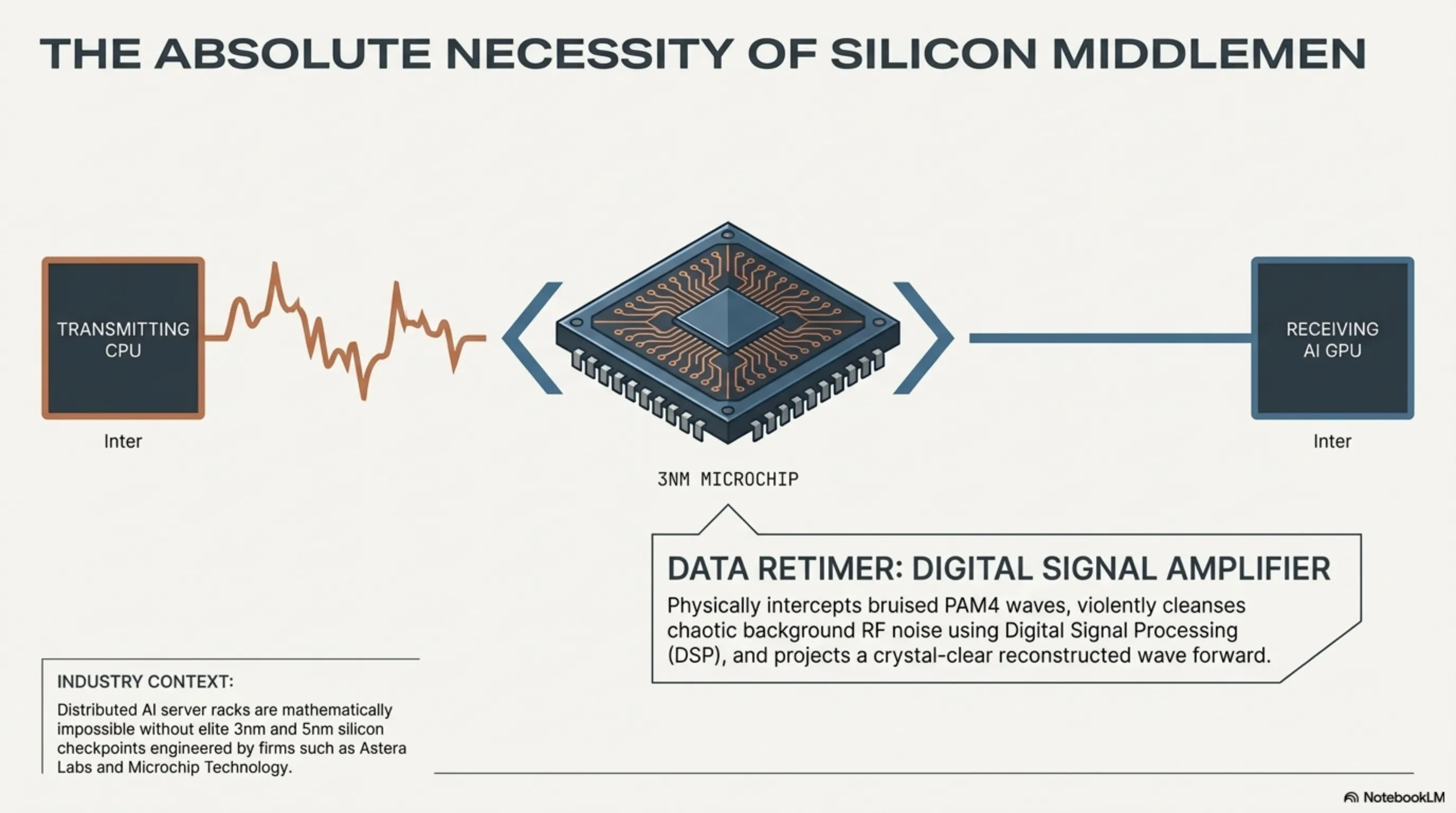
Successfully launching and maintaining a continuous, uninterrupted 64 GT/s frequency signal forcefully across heavily densely packed fiber boards or routing it through lengthy copper cables snaking internally inside massive server chassis is physically not an easy endeavor; it is mathematically grueling and invariably confronts devastating degrees of severe signal decay (Attenuation). This exact physical limitation is precisely where highly specialized, elite semiconductor design firms—most notably industry darlings Astera Labs and the seasoned conglomerate Microchip Technology—firmly established practically total monopolies, generating absolutely astronomical, legendary financial revenues throughout 2026 by exclusively manufacturing and distributing hyper-specialized microchips formally classified as "Data Retimers."

A Retimer fundamentally acts as an aggressive "Digital Signal Amplifier and Reconstruction Station" physically bolted directly onto the centerline of the vast PCIe interconnect cables bridging internal server components. This incredibly complex, brutally expensive chipset functionally actively intercepts the heavily distorted, severely bruised, and highly degraded PAM4 signal wave halfway through its agonizing journey across the copper wiring. It violently cleanses the chaotic waveform utilizing deep Digital Signal Processing (DSP) logic, perfectly strips away the accumulated background RF noise, and perfectly reconstructs and flawlessly regenerates a pristine, crystal-clear digital signal wave. It then aggressively projects this perfectly rebuilt signal forward possessing the exact, original structural power toward its final processing destination. Without the massive, ubiquitous, heavily strategic commercial deployment of these incredibly advanced 3-nanometer and 5-nanometer Retimer chips from these elite silicon architects, the physical, bodily design and subsequent assembly of any deeply advanced, highly distributed modern AI training server (where the GPU farms are physically cordoned off from the primary CPU chassis via heavy cables) would remain mathematically and physically completely impossible.
Part 6: The Immediate Supremacy of AI Accelerators (Nvidia B200 & AMD MI400)
The highly explosive global launch of next-generation "AI Supervisor Racks" physically hitting the heavy enterprise market in the crucial second half of 2026, aggressively spearheaded by Nvidia’s flagship operations, heavily relies entirely upon the foundational existence of direct-attach PCIe 6.0 interface ports. To successfully and coherently compile and train a foundational language structure rivaling the magnitude of a theoretical GPT-5 construct, hardware engineers absolutely cannot rely solely upon highly specialized, proprietary bridge fabrics such as Nvidia's NVLink interconnects. They urgently and aggressively mandate the utilization of standardized, insanely fast networking bridge cards (such as 800-Gigabit or 1.6-Terabit Ethernet controllers) and vastly expanded matrices of hyper-fast NVMe storage drives to continuously, relentlessly "feed" the massively hungry GPU cores with raw training data practically instantaneously.
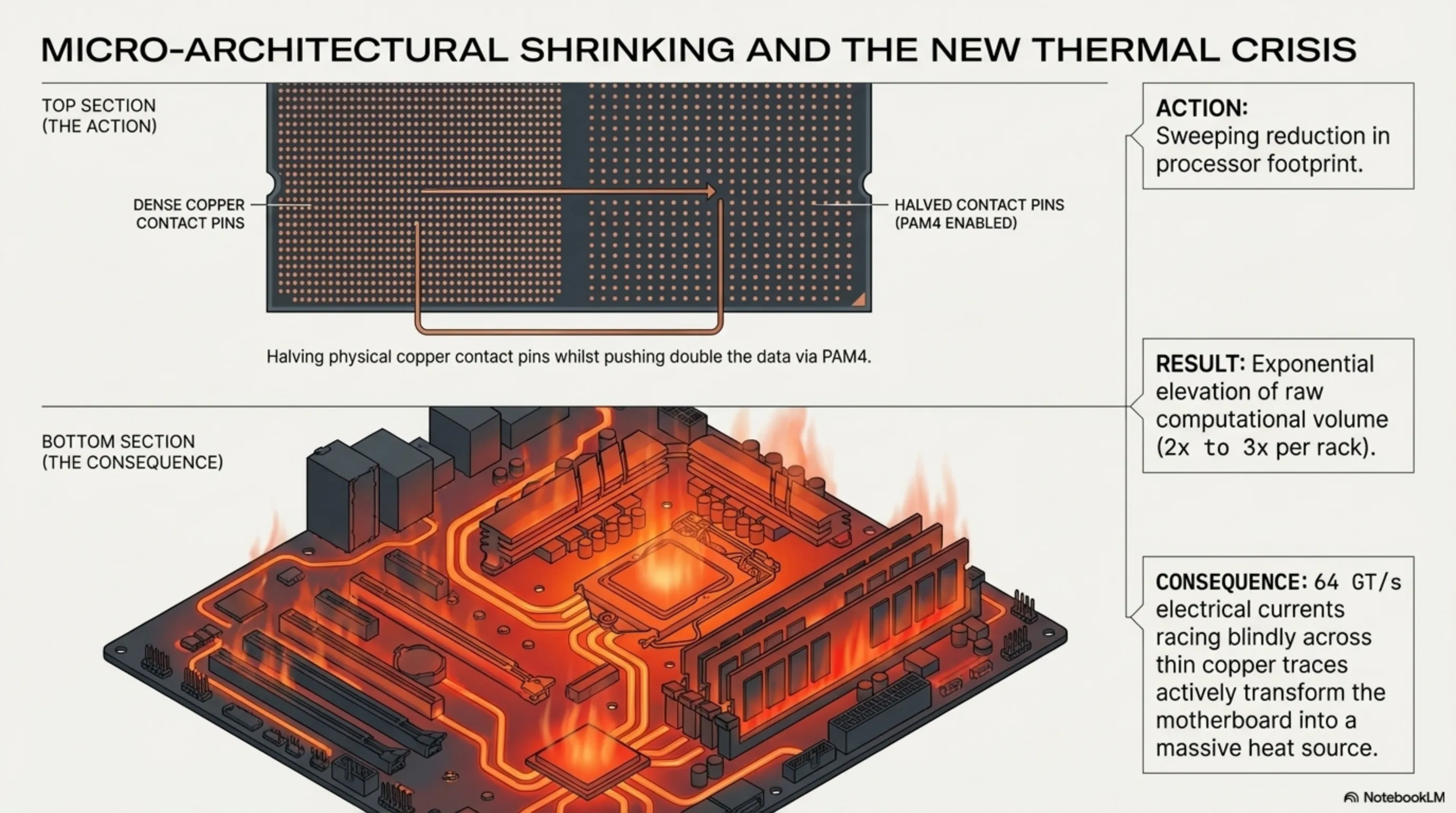
The systemic industry-wide migration plunging heavily into the PCIe Gen 6 framework granted elite silicon design architects a highly unique, practically magical physical capability: Instead of fundamentally needing to construct massive, widely spread physical contact pins across the processor die to move heavy data, they could aggressively halve the physical number of copper pins, whilst immediately exploiting the phenomenally dense PAM4 architecture to forcefully push double the data through that minimized footprint. This deeply aggressive micro-architectural strategy immediately, decisively resulted in the profound physical shrinking of the CPU and GPU footprint upon the motherboard, successfully triggering a massive, sweeping reduction in overall ambient localized heat generation across hyper-scale cloud server facilities, whilst seamlessly maintaining the brutal capacity to exponentially elevate the raw computational volume of every single processing rack present within the modernized datacenter by a staggering multiple of two to three.
Part 7: Cooling Mechanics: Thermal Dissipation in 64 GT/s Micro-environments
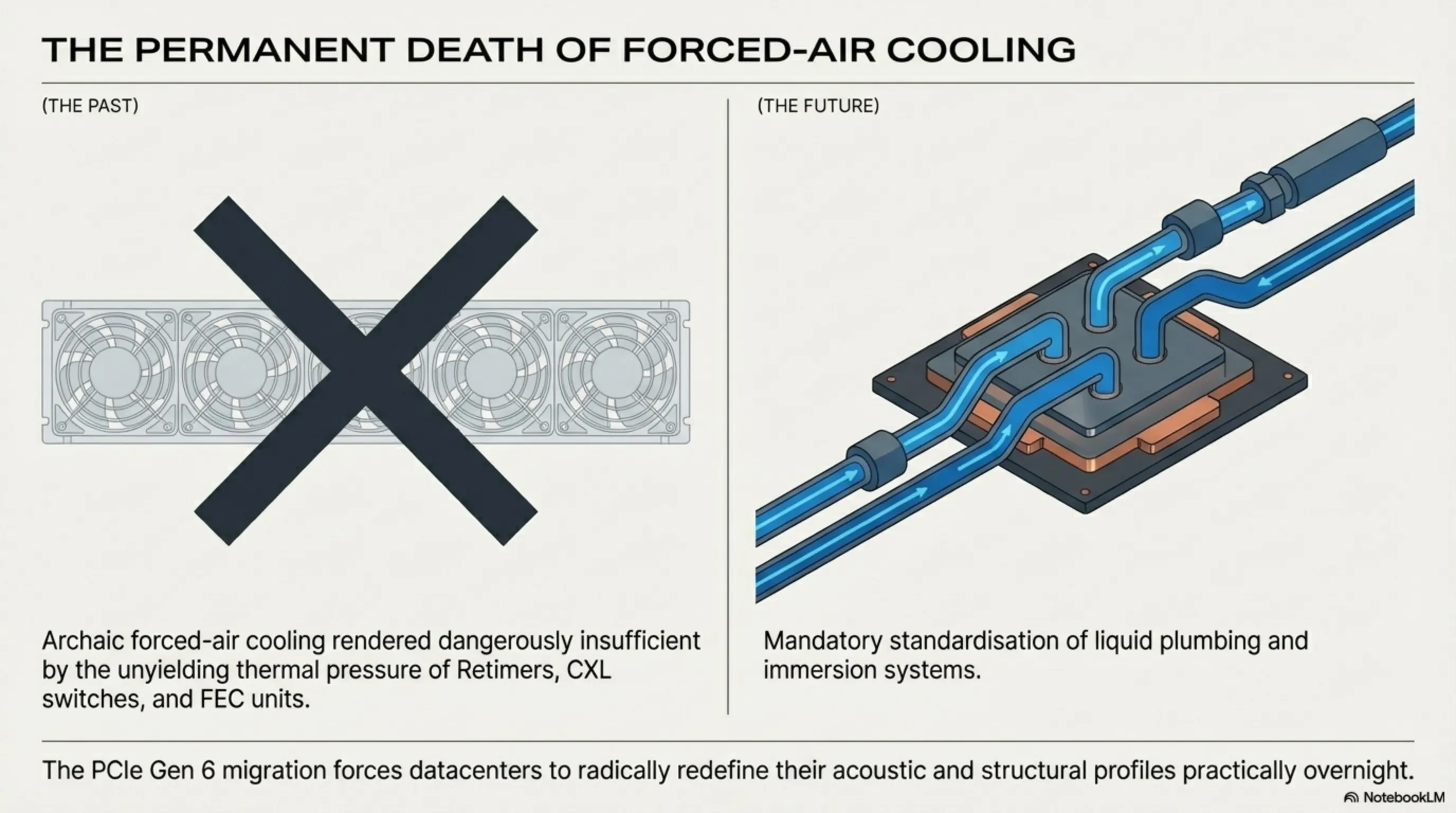
A frequently vastly under-analyzed and severely ignored consequence directly resulting from the brutal integration of PCIe 6.0 systems into mainframes is the terrifyingly complex engineering crisis surrounding localized heat dynamics. While the processors themselves may have successfully shrunk their contact pins, the massive, violent flow of 64 GT/s electrical currents racing blindly across the thin copper traces of the primary PCB (Printed Circuit Board) actively transforms the physical board itself into a sprawling, intensely hot thermal radiator. The specialized Retimer chips, the heavy CXL 3.2 switching matrices, and the deeply integrated FEC calculation units continuously running at maximum load all aggressively stack intense levels of thermal radiation.
This unyielding thermal pressure has unequivocally rendered traditional, archaic forced-air cooling fan systems entirely obsolete and dangerously insufficient for these specific, hyper-dense connection zones. Consequently, the massive adoption of PCIe Gen 6 has simultaneously, aggressively forced the datacenter ecosystem to completely abandon fans and violently standardize Direct-to-Chip Liquid Cooling (DLC) architectures and profound Immersion Cooling solutions practically overnight, radically redefining the plumbing and acoustic profile of modern data processing hubs.
Part 8: Global Supply Chains: Active Optical Cables (AOC) and the Cost of Copper Death
From a brutally harsh economic perspective, migrating towards the PCIe 6.0 topology represents a deeply violent, highly expensive infrastructural expenditure cycle for the enterprise. Standard, deeply cheap passive copper cabling previously utilizing massive lengths to connect server racks has spectacularly completely failed; it physically cannot support the extreme attenuation requirements of the new signal wave without destroying data. Consequently, practically all long-run interconnects within the modern datacenter must be violently ripped out and immediately replaced by insanely expensive, highly complex Active Optical Cables (AOC) that physically translate the electrical signal into perfect light using integrated lasers at each physical terminal.
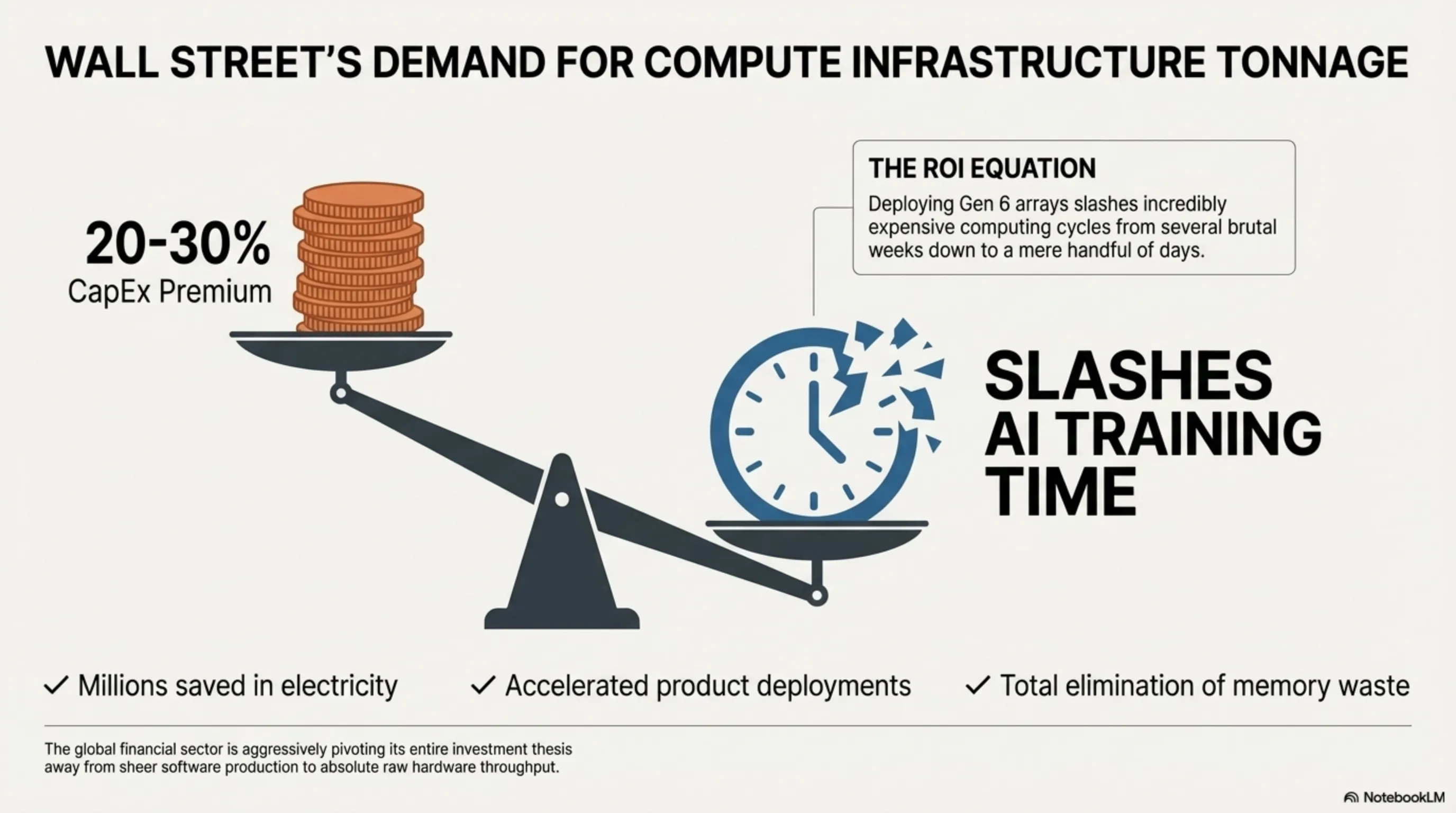
Furthermore, demanding the exclusive use of phenomenally advanced motherboards meticulously engineered with aerospace-grade carbon-fiber weaves and achieving absolute, total isolation (Shielding) to crush the threat of Signal Crosstalk aggressively inflates the base price of the bare-metal server unit by a staggering 20 to 30 percent when compared historically against older Gen 5 server configurations. This violent massive spike in required structural capital expenditure heavily dictates that only the absolute wealthiest, most deeply entrenched Sovereign Wealth Funds, massive Saudi Arabian mega-developments (like NEOM), and trillion-dollar silicon valley clouds currently possess the immense financial firepower required to stockpile and deploy these CXL 3.2 switch matrices globally on a massive scale.
Part 9: Financial Sector ROI: Why Wall Street Craves PCIe 6.0 Adopters
The financial implications perfectly mirror the architectural violence of this transition. Wall Street analysts deeply scrutinizing the tech sector in 2026 are aggressively pivoting their entire fundamental investment thesis entirely away from sheer software production and heavily towards absolute raw, unadulterated "Compute Infrastructure Tonnage." The deeply profound shift towards PCIe 6.0 and CXL completely rewires the fundamental definition of Corporate Return on Investment (ROI) regarding server deployments.

For an enterprise intensely training LLMs, deploying a deeply integrated PCIe Gen 6 server array practically guarantees a monumental, mathematically verifiable reduction in total AI Model Training Time—often successfully slashing incredibly expensive computing cycles from several brutal weeks down to a mere handful of days. This incredibly massive acceleration directly equates to millions of dollars in highly expensive electricity saved, vastly accelerated product deployment cycles, and total elimination of "Stranded Memory" waste. Consequently, the global financial sector actively punishes heavily any cloud provider stubbornly clinging to outdated Gen 5 architecture, instantly recognizing them as fundamentally non-competitive within the grueling race to Artificial General Intelligence (AGI).
Part 10: Security Architecture: Integrity and Data Encryption over Component Interconnects
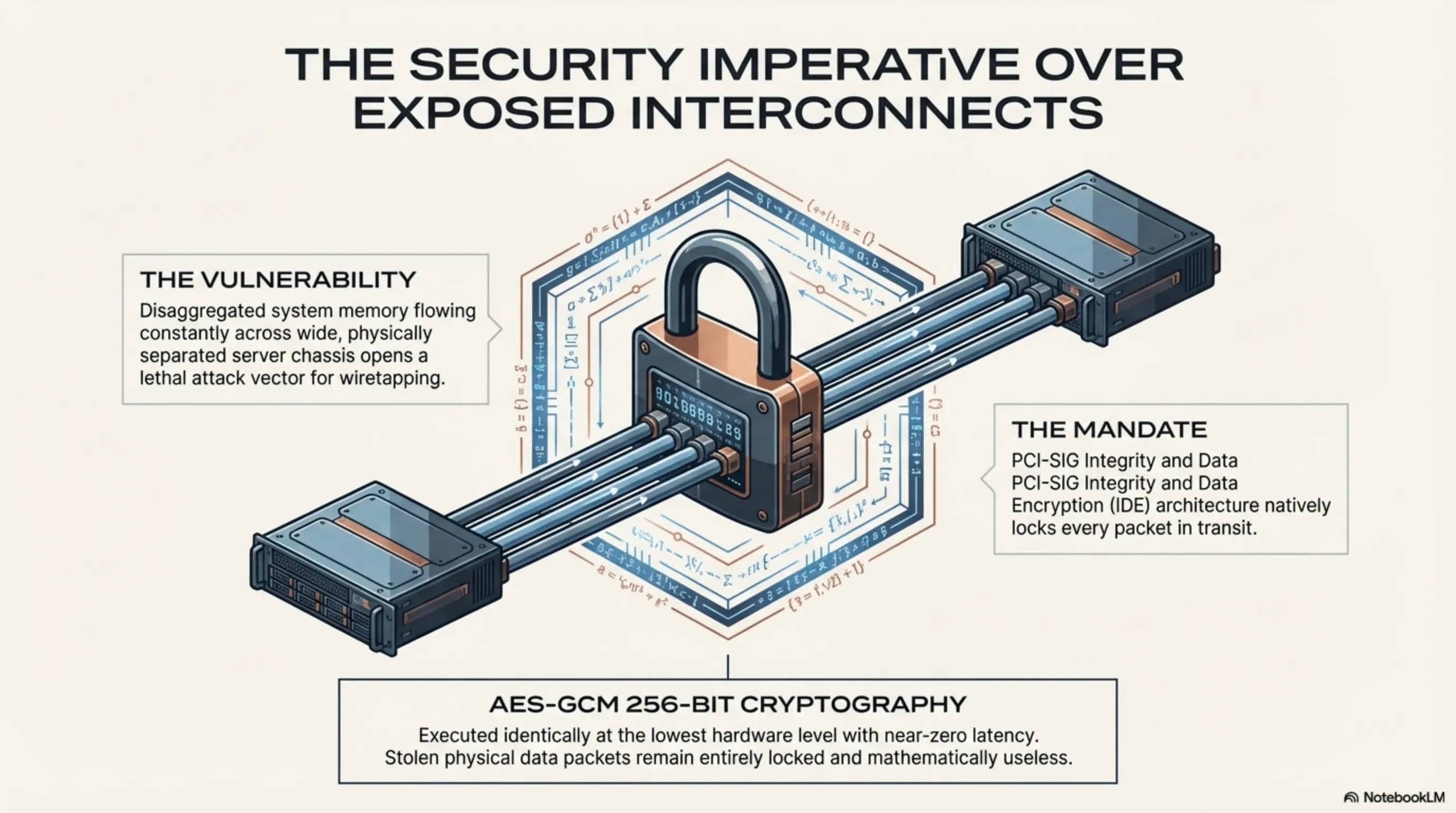
As entire datacenters aggressively shift rapidly into the deeply disaggregated framework practically mandated by CXL 3.2, a terrifyingly massive, profoundly lethal new security attack vector is ripped wide open. Since vital, highly unencrypted, hyper-sensitive system memory data is now constantly, seamlessly flowing rapidly across wide, exposed physical cables actively connecting completely distinct, physically separated server chassis, the concept of localized security is utterly compromised. A highly sophisticated malicious actor, or elite corporate espionage unit, could theoretically completely intercept these massive data flows practically entirely unnoticed by executing aggressive physical wiretapping maneuvers directly onto the interconnects.
To ruthlessly counter and annihilate this severe internal systemic threat, the PCI-SIG heavily incorporated the brutally strict Integrity and Data Encryption (IDE) architecture directly into the core foundation of the PCIe 6.0 and CXL 3.x standardized protocols. Driven natively by profound AES-GCM 256-bit cryptography executed identically at the absolute lowest hardware level within the connection endpoints at near-zero latency, every single solitary data payload traversing the server racks is perfectly, entirely encrypted in transit. This implies that even if an attacker successfully physically breaches the heavy security perimeter of a government-grade datacenter and clamps sniffing hardware directly onto the PCIe backplane, the intercepted, stolen data packet flow remains entirely locked, heavily encrypted, and mathematically completely useless to the attacker, perfectly securing the integrity of decentralized AI compute structures globally.
Part 11: Structural Conclusion: The Inescapable Prerequisite for the Trillion-Parameter Epoch
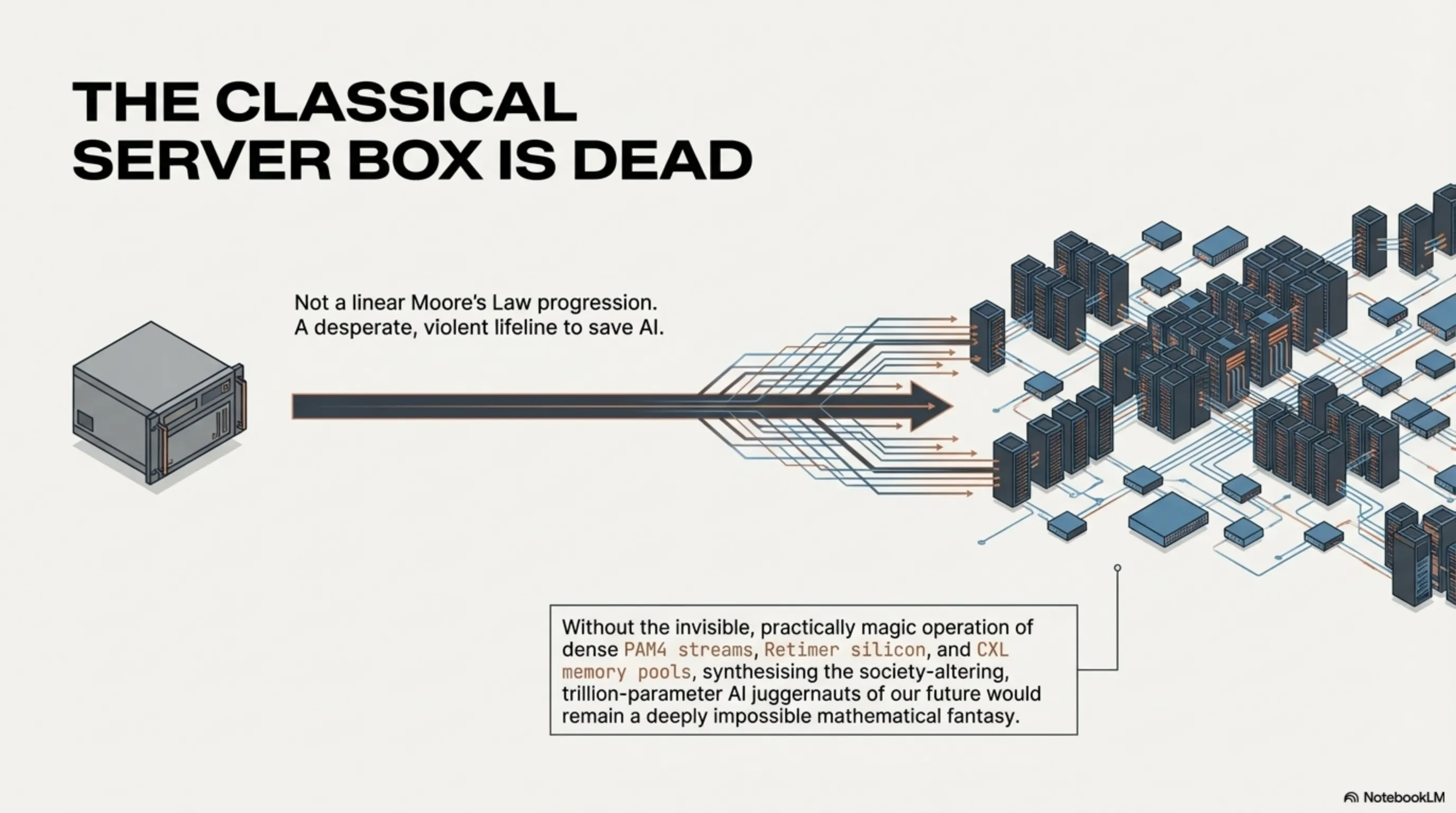
In the brutally honest, highly audited final analysis, the incredibly massive, heavily forced industrial migration directly toward the staggering power of the PCIe Gen 6 standard—and its profoundly transformative, system-shattering companion standard, CXL 3.2—resolutely does not simply represent a standard, highly expected, deeply linear evolutionary hardware progression perfectly in line with "Moore's Law." It represents something far more profound: it is the global silicon sector's desperate, incredibly violent lifeline and absolute singular salvation strategy to completely avoid a total, catastrophic halt regarding the continuous progression of artificial intelligence integration. Without these profound technological miracles, scaling up the absolute cognitive complexity of heavy Deep Learning matrices definitively stops and crashes entirely due to severe physical bandwidth starvation.
By aggressively and successfully abandoning the old, fundamentally constrained architecture of two-state transmission systems and brilliantly implementing dense PAM4 signaling, coupled beautifully with dynamic, heavily fluid CXL memory pools structurally spanning widely across sprawling mega-facilities, the classical computer server has practically ceased existing as an isolated, rigid "box." It has incredibly mutated into an aggressive, brilliantly interconnected, fully distributed monolithic brain, seamlessly transferring unimaginable torrents of critical data deeply beneath the surface. For massive enterprise organizations, heavily funded Cloud Service Providers, and hyper-scale operators stationed globally from Silicon Valley heavily expanding towards deeply ambitious Middle Eastern artificial intelligence tech-hubs, immediately writing the colossal checks required to completely absorb the staggering financial costs of this structural transition is absolutely no longer a mere option or strategic luxury. It represents the singular, aggressively mandatory entrance fee required to maintain relevance and definitively participate actively within the terrifying, hyper-fast, trillion-parameter processing epoch dominating the remainder of human history.
Final Editorial Verdict from the Tekin Engineering Desk: The Only Escape from Severe Bandwidth Asphyxiation
Hardware Value Proposition for Pure Home Computing PCs and Elite Gaming Enthusiasts: 1 out of 10 (The profound bandwidth limits possessed by PCIe 4.0 and PCIe 5.0 systems identically remain entirely un-saturated by even the absolute most aggressive, hyper-fast gaming graphics cards currently available to the market, significantly including the flagship RTX 5090 arrays. Consequently, investing entirely in this radical architecture for pure home consumer usage represents a practically laughable, absurdly foolish expenditure of capital at this current historical juncture.)
Critical Necessity Standard for Global Cloud Platforms and AI Super-Clusters: 10 out of 10 (This topology operates exclusively as the absolute, non-negotiable primary cardiovascular backbone inherently required merely to keep the incredibly ravenous next-generation AI accelerator hardware alive and aggressively functioning without totally imploding on itself.)
Final Tekin Structural Strategic Analysis: The architecture defining PCIe Gen 6.0 and its utterly brilliant overarching counterpart mechanism CXL 3.2 are absolutely not routine, incredibly boring "tick-tock" generational upgrades. Their incredibly complex inception and rushed market debut actually represent the profound, brutally honest admission of a severe hardware failure! The global silicon industry, upon violently reaching the absolute physical limitation of the NRZ modulation methodology embedded deeply within the 5th generation, finally collectively conceded that raw physical copper traces fundamentally cannot mathematically endure higher frequencies. This massive, paradigm-shifting transition replacing basic electrical language structurally with dense PAM4 streams, combined fundamentally with the revolutionary deployment of cloud-based CXL Dynamic Memory Pools, practically provides absolute, irrefutable evidence that classical "Servers" are aggressively metamorphosing perfectly from "a steel box heavily containing tightly packed localized components" into "a globally massive, interconnected, entirely dispersed digital brain physically spanning across vast expanses." Without the deeply invisible, practically magic operation of these systems—and the incredibly expensive deployment of hyper-specialized Retimer Silicon—synthesizing and nurturing the immense, society-altering software-based AI juggernauts dominating our future would remain a deeply impossible mathematical fantasy.

Advanced Datacenter Architecture Gallery