در نیمه اول سال ۲۰۲۶، صنعت دیتاسنتر شاهد یک انقراض خاموش است: مرگ تدریجی پردازندههای مرکزی (CPU) به عنوان قلب تپنده سرورها. این کالبدشکافی استراتژیک (بیش از ۲۵۰۰ کلمه) به تشریح زوال معماری x86 در برابر تسلط مطلق واحدهای پردازش گرافیکی (GPU) و شتابدهندههای عصبی (NPU) میپردازد. ما معماری سرورهای Grace-Blackwell انویدیا، محدودیتهای ترمودینامیکی دیتاسنترهای هوا-خنک، و اقتصاد محاسبات هوش مصنوعی را در سطح سرورهای شرکتی و لبه (Edge) بررسی میکنیم. این سند برای مدیران ارشد فناوری (CTO) یک نقشه راه حیاتی است تا از سرمایهگذاری بیحاصل روی سختافزار
سقوط امپراتوری CPU: چرا GPUها و NPUها دیتاسنترهای شرکتی ۲۰۲۶ را فتح کردند؟
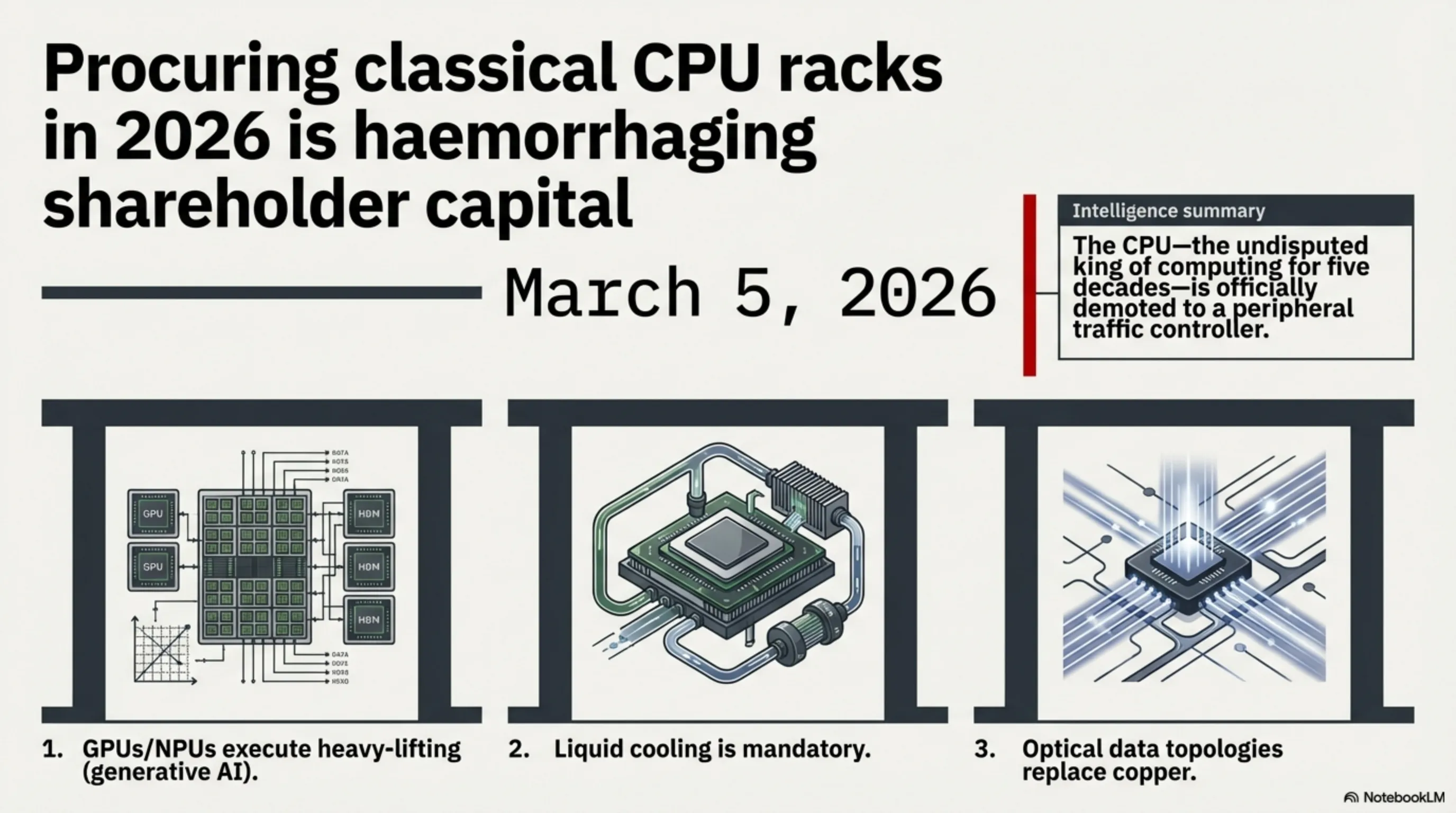
به گزارش تحلیلی تکین خوش آمدید. امروز ۵ مارس ۲۰۲۶ است و اگر شما در حال طراحی یا ساخت یک دیتاسنتر جدید بر پایه معماری کلاسیک «رَکهای پر از CPU» هستید، در حال هدر دادن میلیونها دلار از سرمایه سهامداران خود میباشید. سال ۲۰۲۶ نقطهای است که پردازندههای مرکزی، که برای پنج دهه پادشاه بلامنازع پردازش بودند، به طور رسمی به یک قطعه کنترلی حاشیهای - صرفاً یک مدیر ترافیک برای هیولاهای واقعی यानी GPUها و NPUها - تنزل درجه پیدا کردند. در این گزارش فوقتخصصی، ما کالبد این تغییر پارادایم را میشکافیم.

لایه استراتژیک ۱: پایان قانون مور و زوال معماری x86
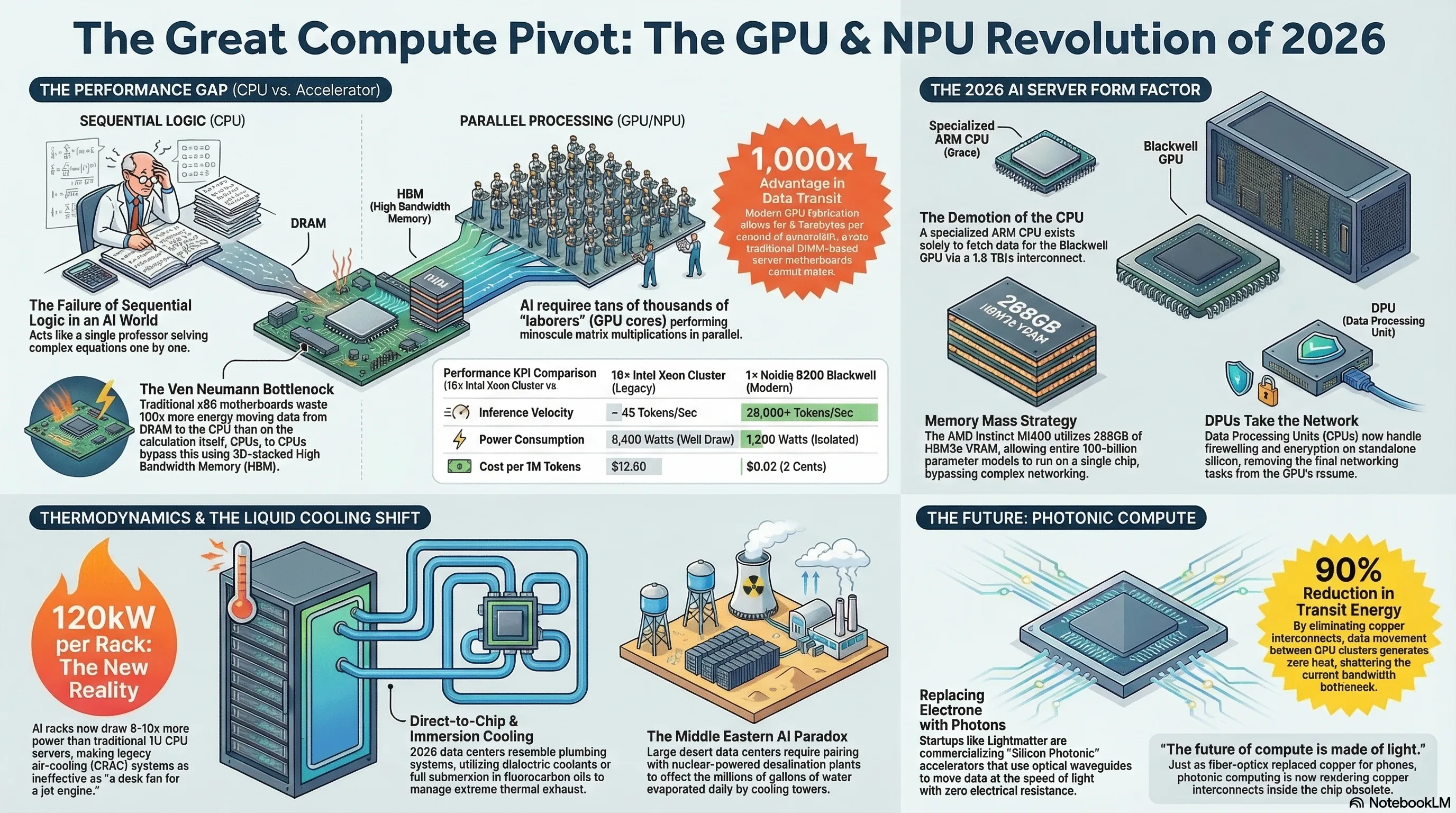
پردازندههای مرکزی (CPUs) بر پایه یک معماری بسیار پیچیده و همهکاره طراحی شدهاند. آنها مانند یک استاد دانشگاه هستند که میتواند معادلات دیفرانسیل سخت را به صورت سریالی حل کند. اما هوش مصنوعیِ مولد (Generative AI) نیازی به استاد دانشگاه ندارد؛ او به هزاران کارگر ساده نیاز دارد که وظایف کوچکِ ضرب و جمع ماتریسها را به صورت موازی انجام دهند. اینجاست که CPUها فلج میشوند.
۱.۱ چرا CPUها در استنتاج هوش مصنوعی (Inference) فلج هستند؟
در سال ۲۰۲۶، شرکتها دیگر صفحات استاتیک وب را سرو (Serve) نمیکنند. هر کاربر در حال چت کردن با یک مدل زبانی (LLM)، درخواست تولید تصویر، یا اجرای کدهای پایتون توسط یک Agent صوتی است. یک CPU سرور معتبر مانند Intel Xeon Platinum شاید بتواند با استفاده از افزونههای AVX-512 چند ده توکن در ثانیه تولید کند، اما یک GPU معمولی مثل Nvidia H100 یا همتای آن در سال جاری، دهها هزار توکن را در کسر کوچکی از ثانیه پردازش میکند. تفاوت، هزار برابری است. انرژی مصرفی به ازای هر خروجی در CPUها اصلاً توجیه اقتصادی ندارد.
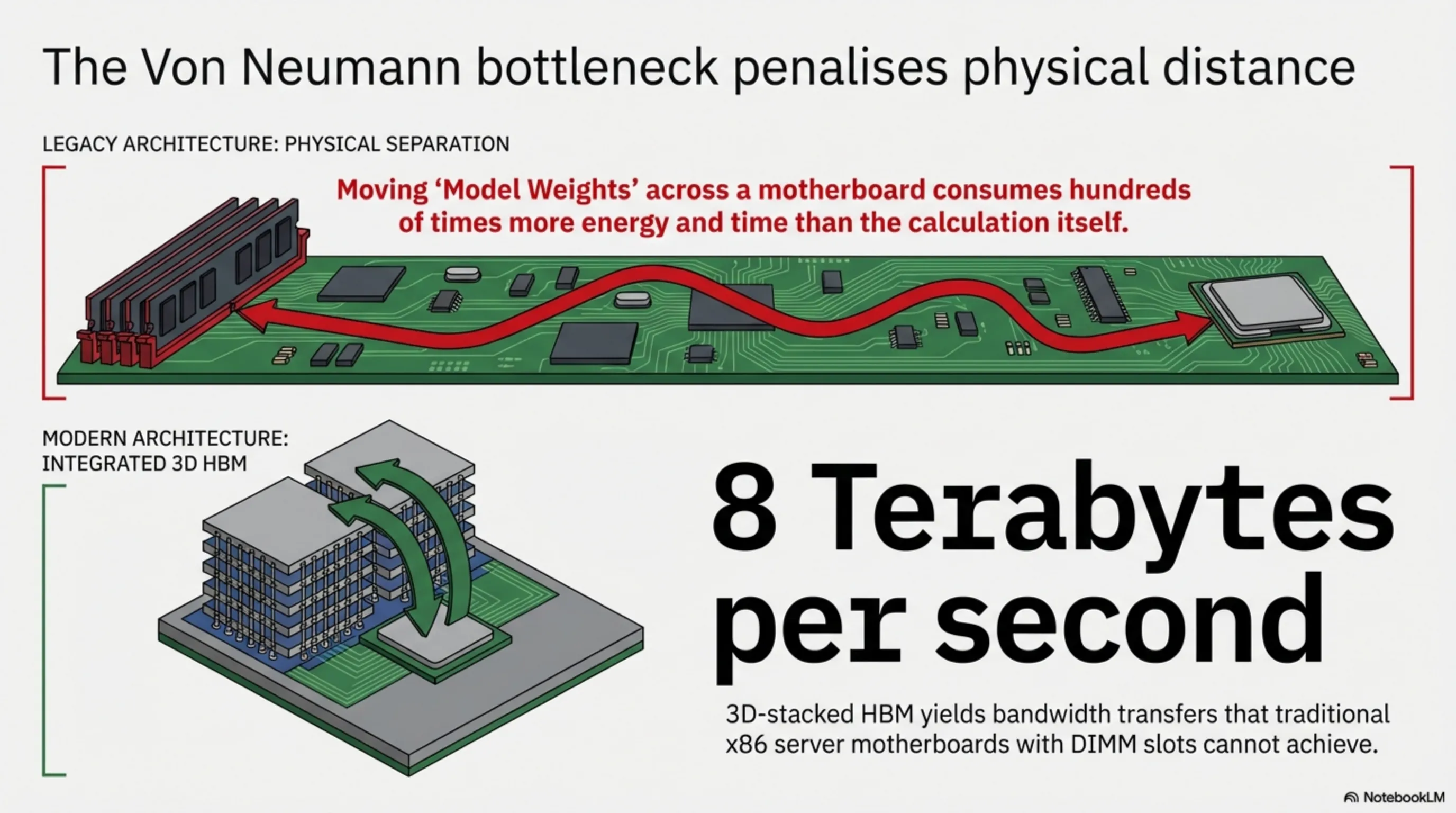
۱.۲ معماری حافظه و گلوگاه انتقال داده (Von Neumann Bottleneck)
بزرگترین دشمن پردازش هوش مصنوعی در معماری کلاسیک، فاصله فیزیکی بین رم (DRAM) و پردازنده است. فرآیند کپی کردن وزنهای مدل (Model Weights) از حافظه به پردازنده، صدها برابر بیشتر از خود محاسبهی ریاضی زمان میبرد. در ساختارهای GPU مدرن، تراشههای حافظه از نوع HBM (High Bandwidth Memory) به معنای واقعی کلمه در فاصله چند میکرومتریِ هستههای پردازشی (به صورت 3D Packaging روی یک قطعه سیلیکون قرار دارند. این طراحی پهنای باندی بالغ بر ۸ ترابایت بر ثانیه ارائه میدهد؛ نرخی که مادربردهای سنتی x86 با اسلاتهای DIMM فقط میتوانند خوابش را ببینند.
📊 نمودار استراتژیک: مقایسه کارایی CPU در برابر GPU در دیتاسنتر (مدل Llama 3 70B)
| شاخص عملکردی (Performance KPI) | خوشه ۱۶× Intel Xeon (Dual) | ۱× Nvidia B200 (Blackwell) |
|---|---|---|
| تولید توکن بر ثانیه (سرعت استنتاج) | مقدار تقریبی: ۴۵ توکن | فراتر از ۲۸,۰۰۰ توکن |
| مصرف انرژی پیک سیستم (Peak TDP) | ۶,۴۰۰ وات (در حالت Load کامل) | ۱,۲۰۰ وات متمرکز |
| هزینه محاسبه هر یک میلیون توکن (API Cost) | $۱۲.۵۰ | $۰.۰۲ (۲ سنت) |
لایه استراتژیک ۲: کالبدشکافی سرورهای هوش مصنوعی ۲۰۲۶
نگاهی به نقشه معماری سرورهای سال جاری نشان میدهد که توازن قدرت کاملاً از اینتل و AMD (بخش CPU) خارج شده و در دستان طراحان شتابدهندهها قرار گرفته است.
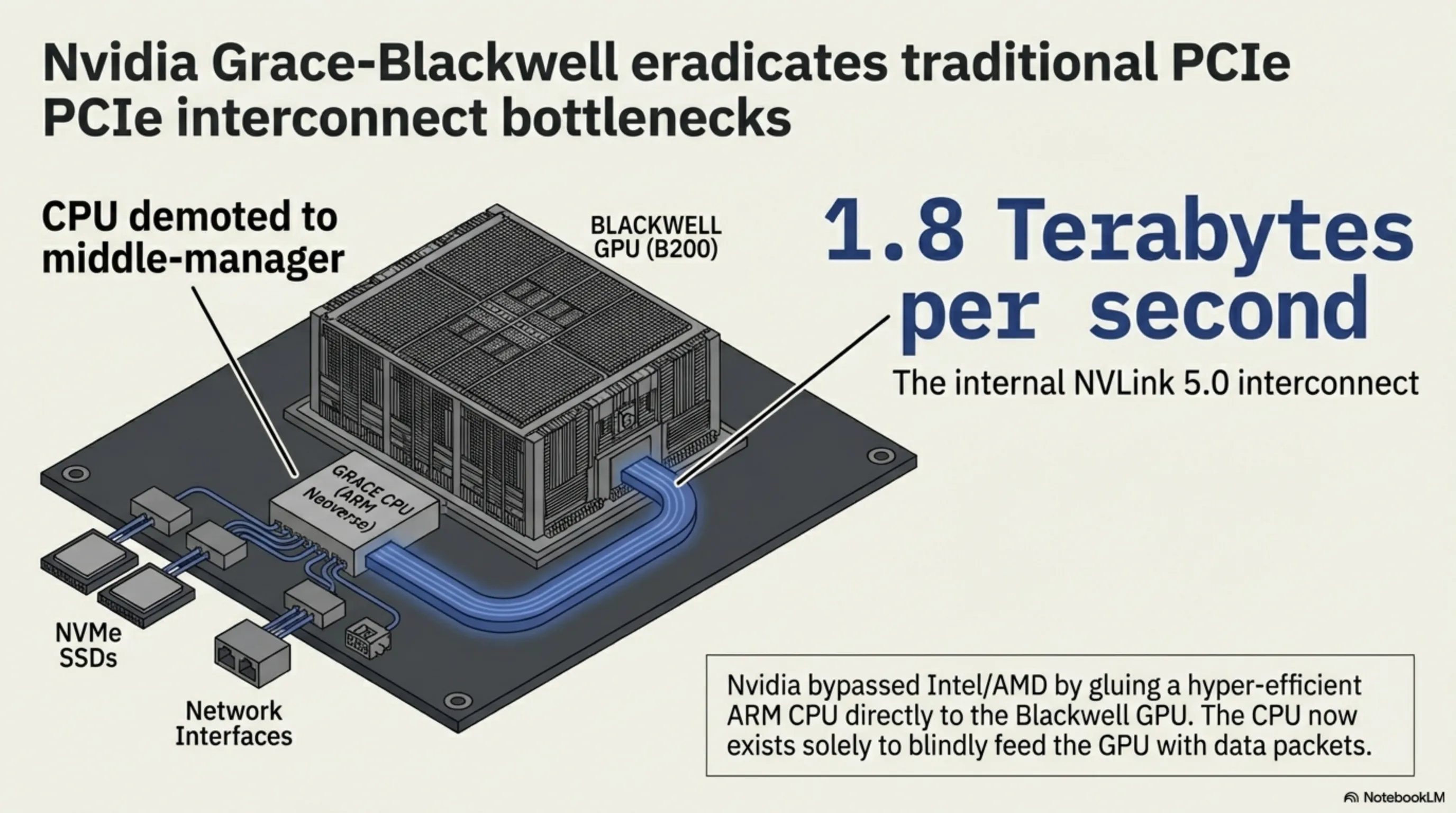
۲.۱ شتابدهندههای Nvidia Grace-Blackwell و گذرگاه NVLink 5.0
انویدیا با ارائه پلتفرم Grace-Blackwell، تیر خلاص را به پیکر x86 شلیک کرد. آنها یک CPU ضعیف و بسیار کممصرف مبتنی بر معماری ARM (به نام Grace) را مستقیماً از طریق یک پل پرسرعت به پردازنده گرافیکی قدرتمند (Blackwell) متصل کردهاند. در این سرورها، CPU صرفاً وظیفه خواندن داده از شبکه و SSD را دارد و کل پردازش بلافاصله به GPU پاس داده میشود. گذرگاه تبادل اطلاعات NVLink 5.0 میتواند دادهها را با سرعت حیرتانگیز ۱.۸ ترابایت در ثانیه انتقال دهد که عملاً مفهوم "تأخیر شبکه" در داخل رَک را نابود کرده است.
۲.۲ تراشههای AMD Instinct MI400 و نبرد حافظه HBM3e
در جبهه سبز، AMD تراشه غولپیکر MI400 را عرضه کرده است که کاملاً بر روی ظرفیت حافظه تمرکز دارد. مدلهای زبانی عظیم، تشنهی VRAM هستند. AMD با قرار دادن ۲۸۸ گیگابایت حافظه فوقسریع HBM3e روی یک تکتراشه، این امکان را فراهم کرده که یک شرکت بتواند به جای خریدن ۴ سرور انویدیا با دردسرهای شبکهبندی (Clustering)، کل یک مدل زبانی ۱۰۰ میلیارد پارامتری را تنها روی یک سرورِ AMD بارگذاری کند که از نظر هزینه و نگهداری، برای دیتاسنترهای سطح متوسط شرکتی (Enterprise) به شدت جذاب است.
سیگنال معماری سیستم: وقتی بیش از ۸۵ درصد از پردازشهای روزمره (نظیر پردازش تصویر، کدنویسی، پاسخ به کوئریهای SQL) توسط Agentهای هوشمند لینوکسی انجام میشود؛ داشتن صدها گیگاهرتز پردازنده CPU یک بارِ اضافی است.

لایه استراتژیک ۳: ترمودینامیک دیتاسنتر و گذار خونین به خنککننده مایع
قوانین فیزیک کلاسیک به مهمترین سد راه توسعه هوش مصنوعی تبدیل شدهاند. نمیتوان انرژی را از بین برد؛ فقط میتوان آن را به گرما تبدیل کرد.
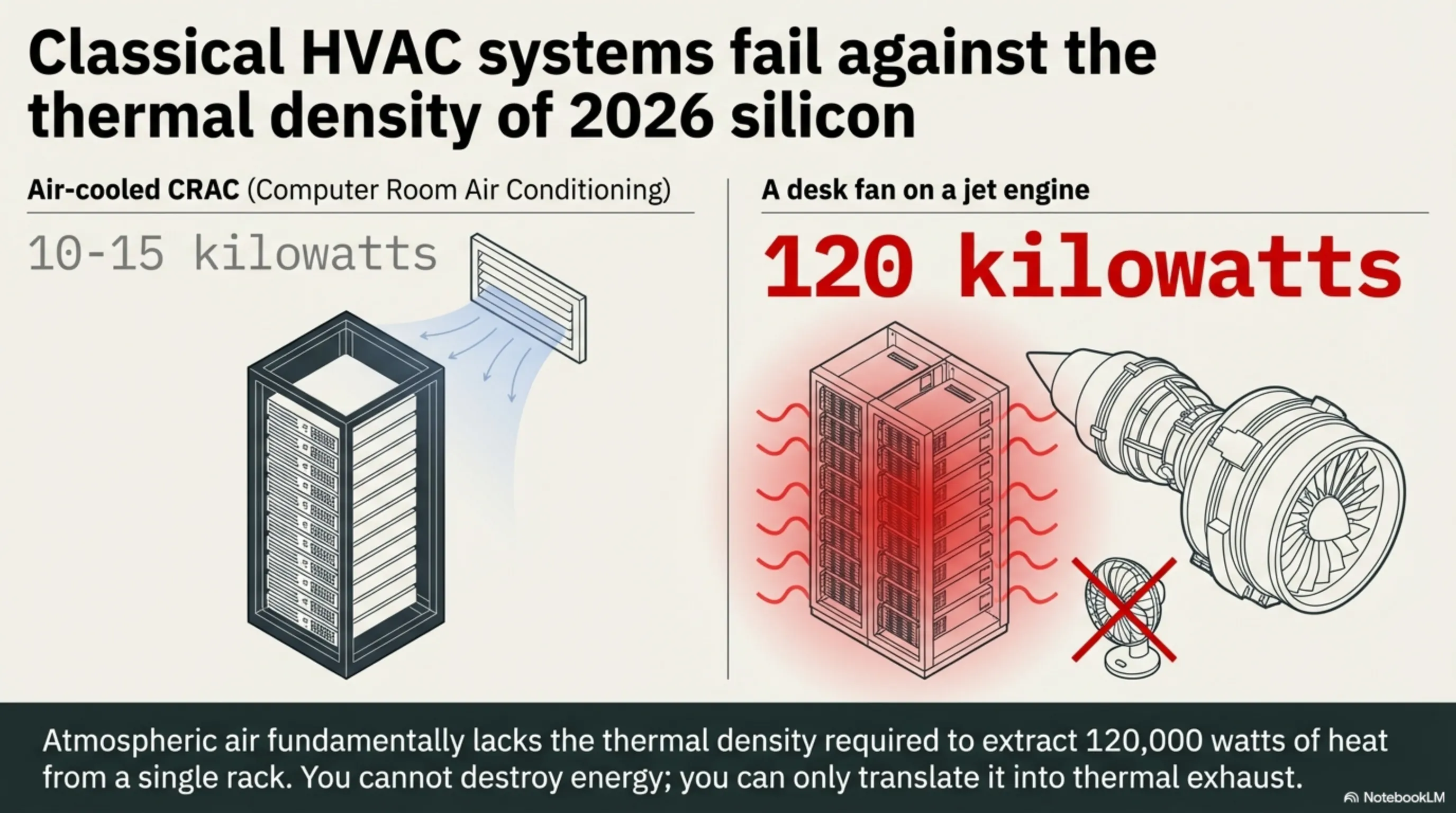
۳.۱ مرگ سیستمهای تهویه مطبوع (HVAC) سنتی
زمانی که سرورهای CPU-محور ۱U روی کار بودند، یک رَک کامل (Full Rack) در اوج کاری حدود ۱۰ الی ۱۵ کیلووات انرژی مصرف میکرد و سیستمهای خنککننده گازی (CRAC) مبتنی بر باد خنک، این حرارت را دفع میکردند. اما امروز، یک رک کامل از سرورهای انویدیا Blackwell بیش از ۱۲۰ کیلووات انرژی مصرف میکند. پمپاژ هوای سرد به این رک، مثل فوت کردن به آتش فشفشه است؛ هوا دیگر ظرفیت گرمایی لازم را برای خنک کردن سیلیکونهای ۲۰۲۶ ندارد.
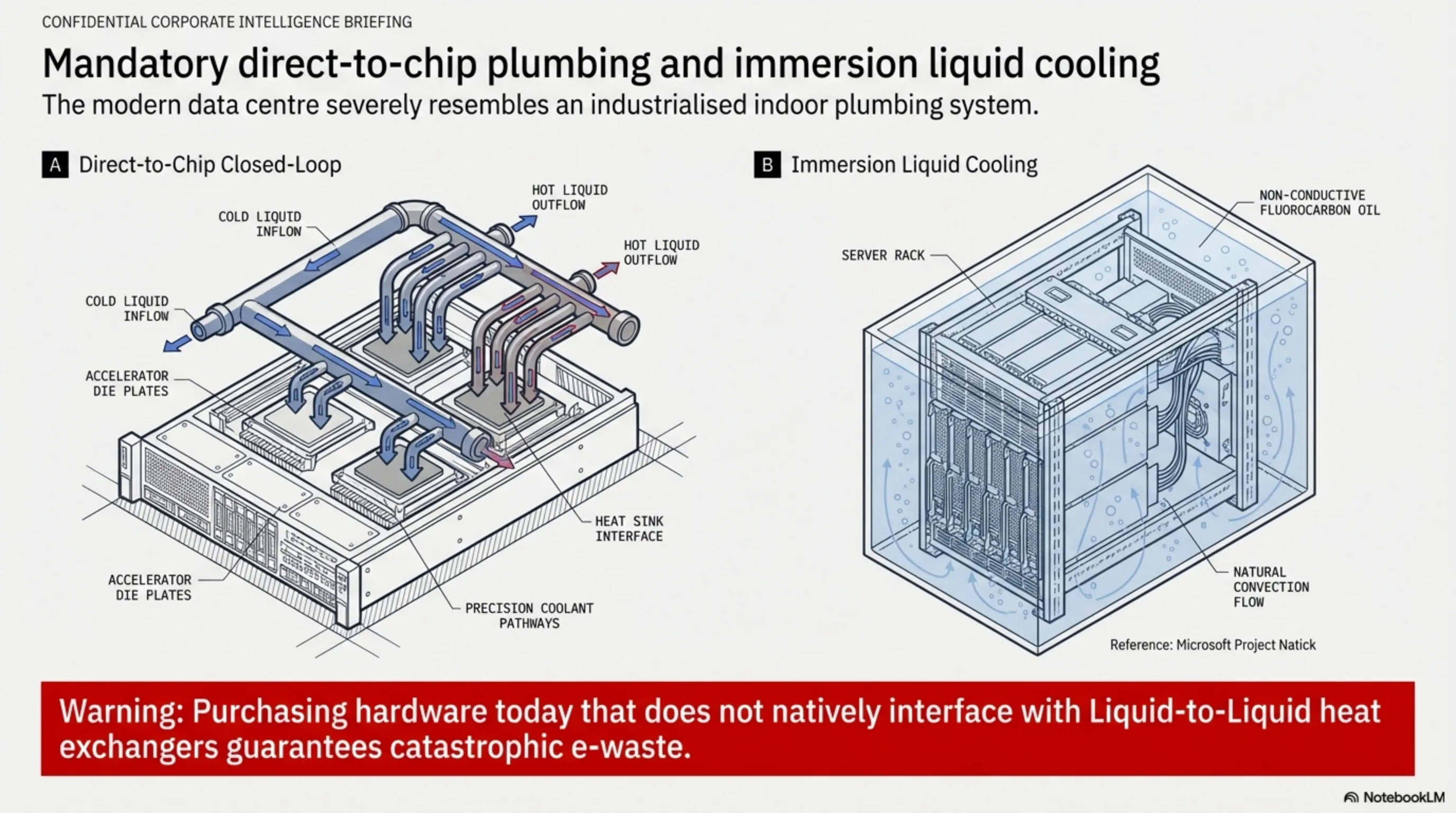
۳.۲ خنککنندههای مستقیم و غوطهوری (Direct-to-Chip & Immersion)
در سال ۲۰۲۶، دیتاسنترهای نوساز تماماً شبیه موتورخانههای صنعتی لولهکشی شدهاند. سیستمهای "خنککننده مستقیم" (Direct-to-Chip) آب یا مایعات خنککننده دیالکتریک را مستقیماً از روی پلاکهای نصب شده روی پردازندههای GPU عبور میدهند. در سطح پیشرفتهتر (استقرار سرورهای مایکروسافت در بستر اقیانوس یا دیتاسنترهای زیرزمینی)، از "خنککننده غوطهوری" استفاده میشود؛ جایی که کل سرورها درون وانهایی پر از روغن فلوروکربن غیرهادی غوطهور میشوند. اگر سرمایهگذاری امروز شما در سختافزار، پشتیبانی بومی از Liquid Cooling نداشته باشد، عملاً زبالهی الکترونیکی خریداری کردهاید.

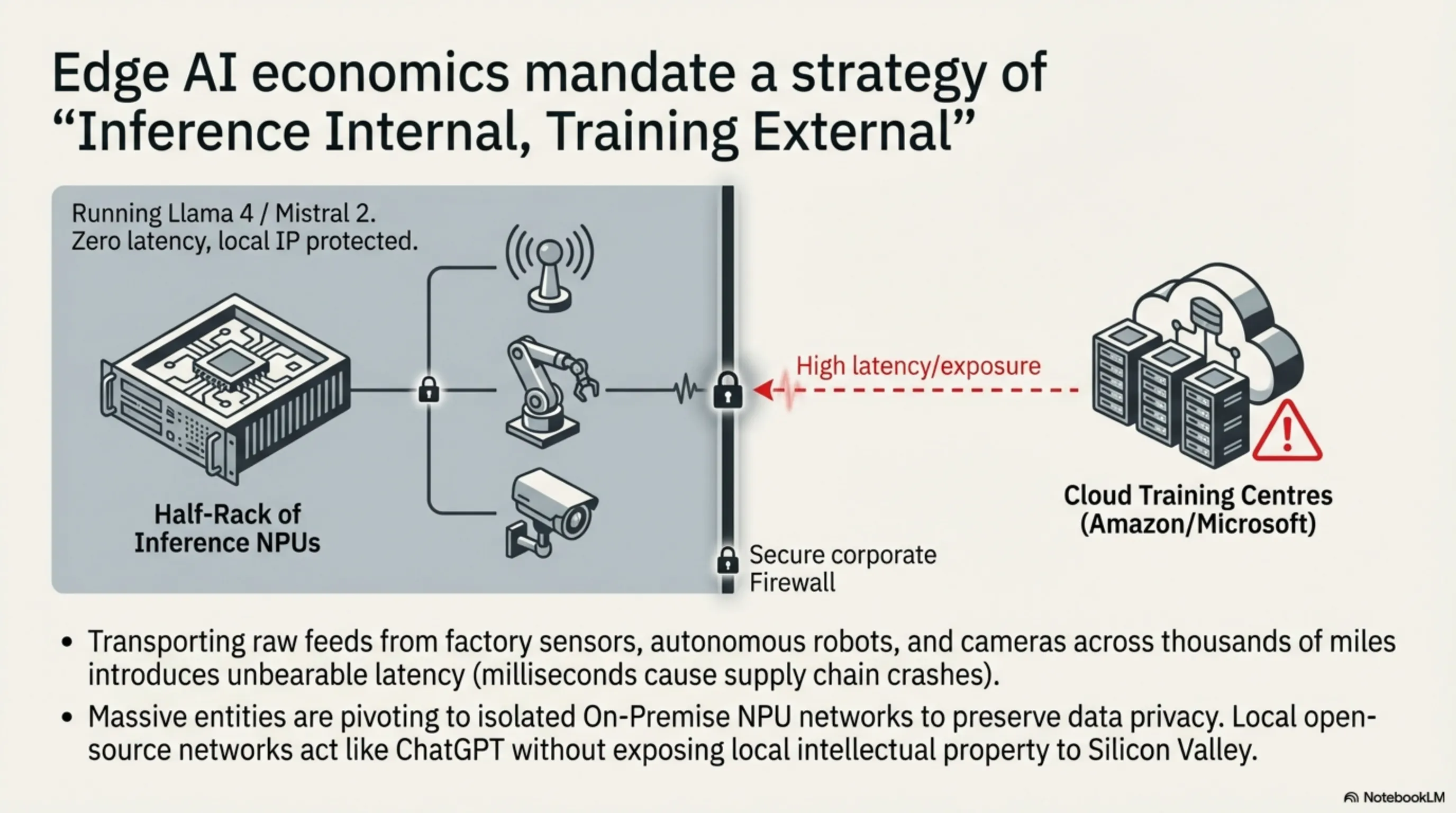
لایه استراتژیک ۴: اقتصاد لبه (Edge AI) و میکرو-دیتاسنترها
ارسال اطلاعات تمام سنسورها، دوربینهای مداربسته و رباتهای انبار (مانند اطلس شرکت آمازون) به دیتاسنترهای دوردست ابری، تأخیر زمانی (Latency) ایجاد میکند که در تصمیمگیریهای صدمثانیهای فاجعهبار است.
۴.۱ بازگشت سرمایه در استقرار مدلهای زبانی متنباز
روند غالب ۲۰۲۶ برای ابرشرکتها این است: "استنتاج در داخل، آموزش در خارج". شرکتها برای حفظ حریم خصوصی دادهها، شبکههای NPU اختصاصی درونسازمانی (On-Premise) تشکیل دادهاند. یک رَک ارزانقیمت متشکل از NPUهای تخصصی، مدلهای منبعباز (مانند Llama 4 یا Mistral) را با دقت ۹۹ درصد نسبت به GPT-4 اما بدون هیچ دغدغه نشت اطلاعاتِ سازمانی، به محققان و کارمندان ارائه میدهد.
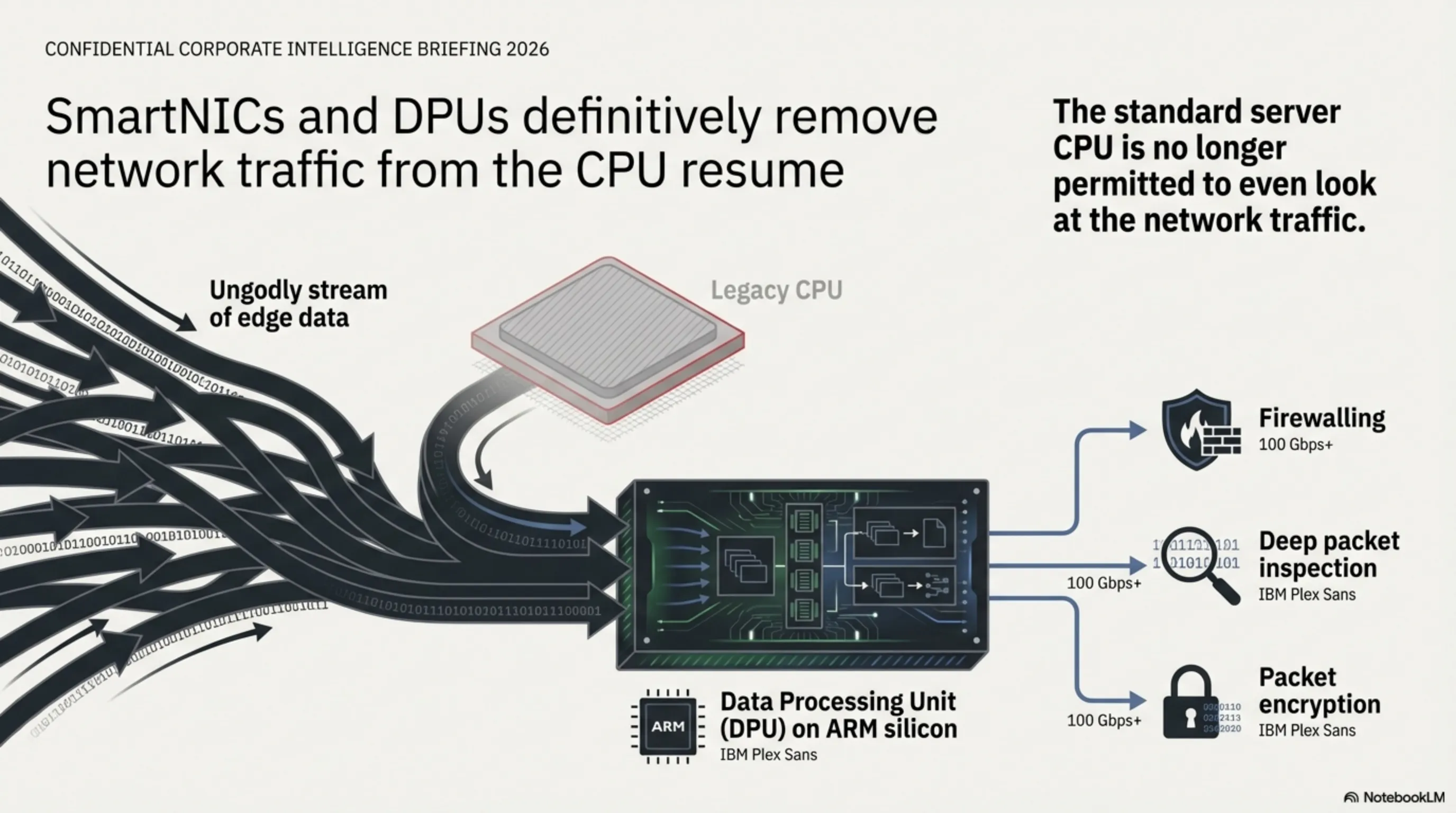
۴.۲ کارتهای پردازنده شبکه هوشمند (DPUs/SmartNICs)
برای کنترل ترافیک عظیم بین این میکرو-دیتاسنترهای محلی، چیپهای کنترل شبکه (SmartNICs) وارد میدان شدهاند. این چیپها بستههای اطلاعاتی (Packets) را رمزگذاری و روتینگ میکنند بدون اینکه سیستمعامل سرور اصلاً درگیر این پروسه شود و این عملاً آخرین وظیفهای که زمانی در انحصار CPUها را بود، از آنها میگیرد.
لایه استراتژیک ۵: تهدید منابع و آینده دیتاسنتر در خاورمیانه و ایران
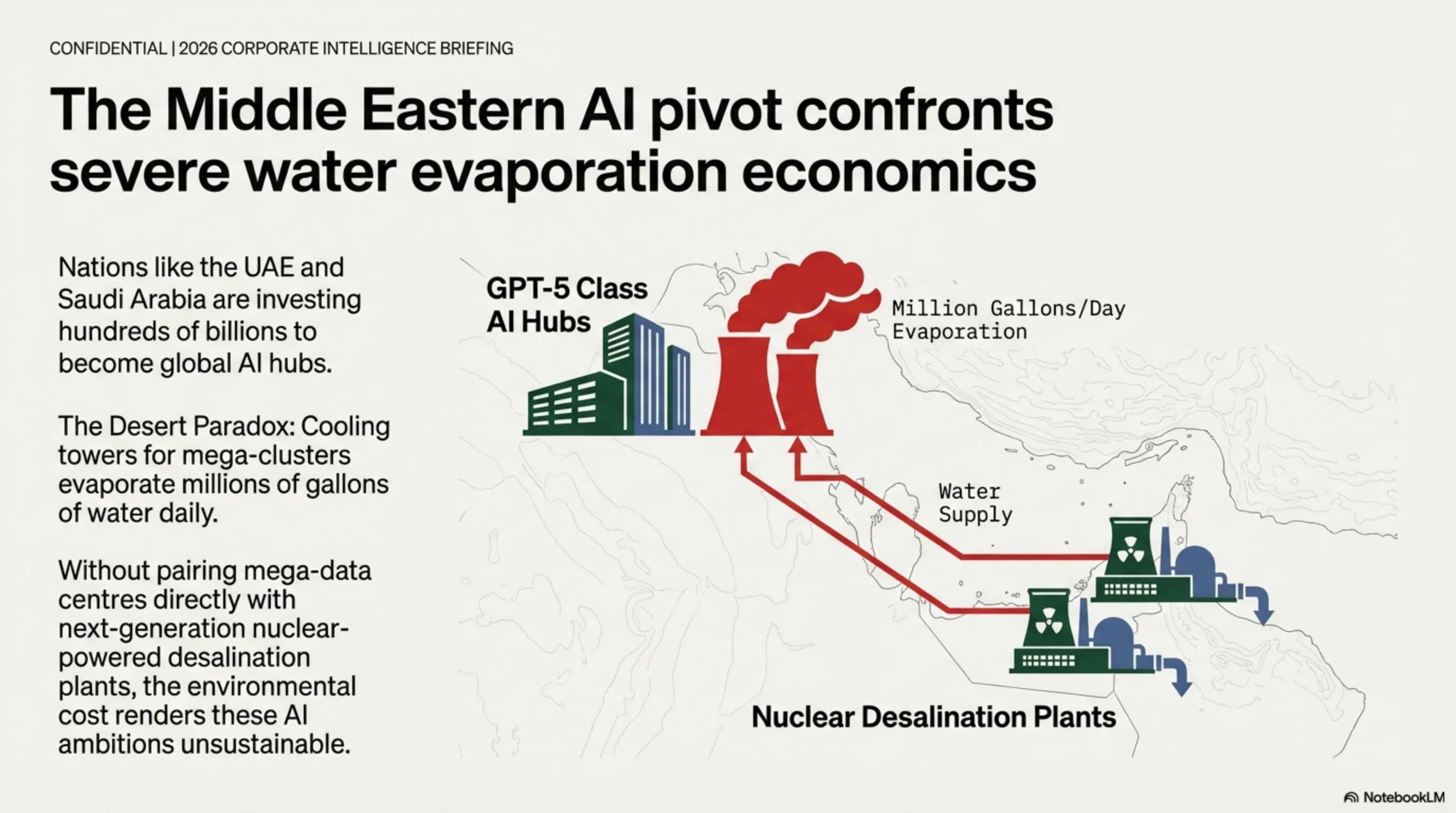
۵.۱ مصرف دیوانهوار آب و انرژی
راهاندازی یک چتبات در سطح ChatGPT-4 برای خاورمیانه نیازمند سرورهایی است که روزانه میلیونها لیتر آب برای برجهای خنککنندهشان (Cooling Towers) تبخیر میکنند. سرمایهگذاریهای عظیم کشورهای عربی (امارات و عربستان) برای تبدیل شدن به پایتخت هوش مصنوعی منطقه، بدون استفاده از انرژی خورشیدی ارزان و دستگاههای آبشیرینکن در مقیاس صنعتی، یک توهم غیرپایدار است.
۵.۲ عبور از تحریمها از طریق کلاسترینگ غیرمتمرکز
برای کشورهایی مانند ایران که تحت تحریمهای سختگیرانه برای واردات شتابدهندههای غولپیکر تجاری (مانند انویدیا الحاقیه سیاه H100) قرار دارند، مهندسان به سمت "کلاسترینگ فوقالعاده" کارت گرافیکهای مخصوص بازی (مثل RTX 5090 و 4090) روی آوردهاند. از طریق پروتکلهای شبکهبندی Peer-to-Peer پرسرعت، هزاران کارت گرافیک دسکتاپی در فارمهای رمزنگاری سابق، اکنون به عنوان یک اَبَررایانه غیرمتمرکز برای اجرای هوش مصنوعی متنباز عمل میکنند که رهگیری یا تحریم آن توسط غرب تقریباً غیرممکن است.
لایه استراتژیک ۶: جایگزینهای سیلیکونی — ظهور محاسبات فوتونیک (Photonic Compute)
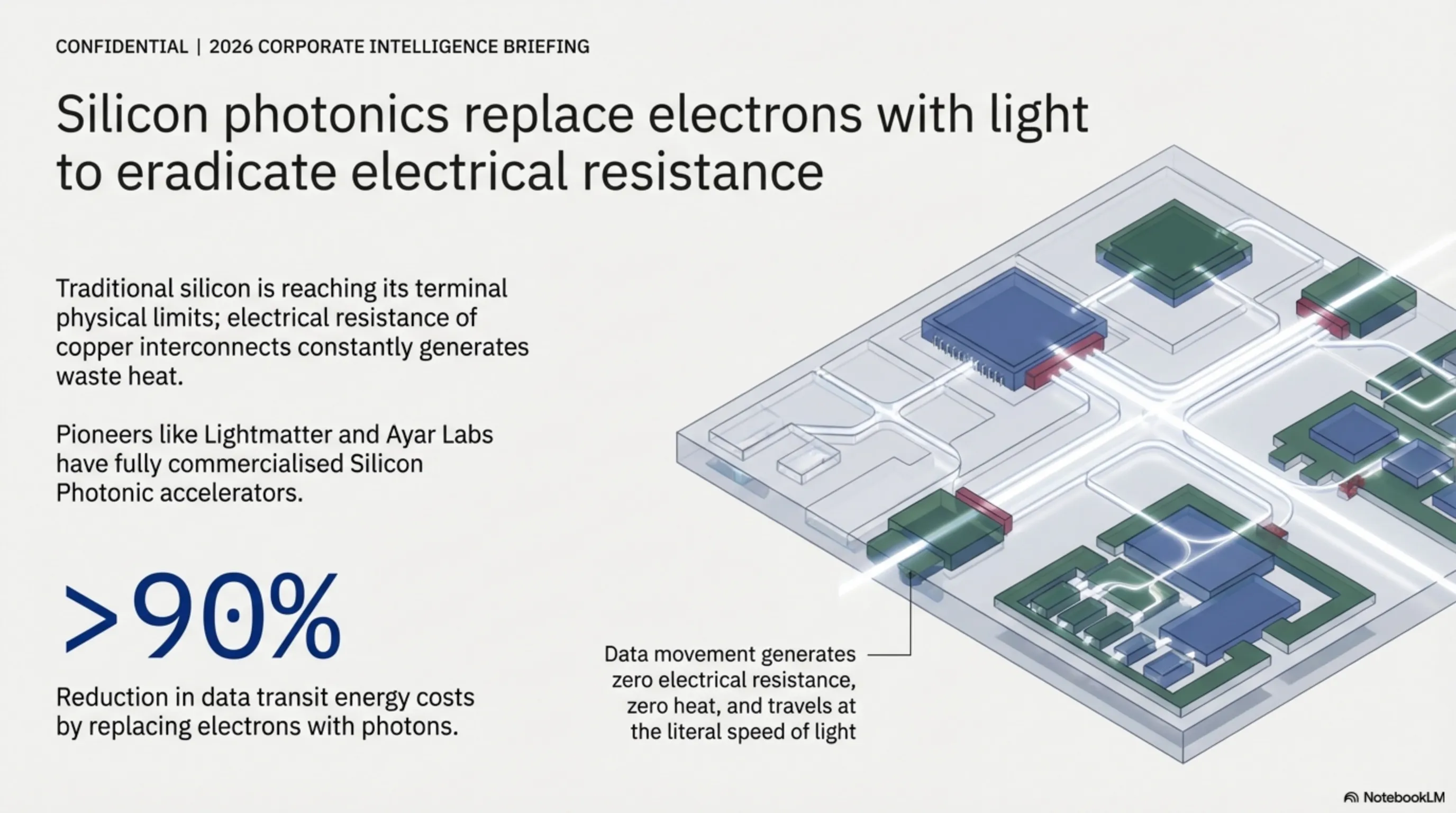
حتی با خنککنندههای غوطهوری و معماریهای سهبعدی حافظه، سیلیکون در نهایت به بنبست فیزیکی برخورد میکند. مقاومت الکتریکی سیمهای مسیِ داخل تراشه، همواره تولید حرارت میکند. پاسخ صنعت به این مشکل بنیادین، جایگزینی الکترونها با فوتونها (ذرات نور) است.
۶.۱ پردازش با سرعت نور: پایان مقاومت الکتریکی
شرکتهای پیشگامی مانند Lightmatter و Ayar Labs در سال ۲۰۲۶ نشان دادند که میتوان با استفاده از "تراشههای سیلیکون فوتونیک"، دادهها را از طریق موجبرهای نوری در داخل خود پردازنده جابجا کرد. از آنجا که فوتونها برخلاف الکترونها مقاومت فیزیکی تولید نمیکنند، انتقال داده عملاً هیچ گرمایی ساطع نمیکند. این فناوری اجازه میدهد دادهها با سرعت نور بین کلاسترهای GPU جابجا شوند و مصرف انرژی برای تبادل دیتا را تا ۹۰ درصد کاهش میدهد.
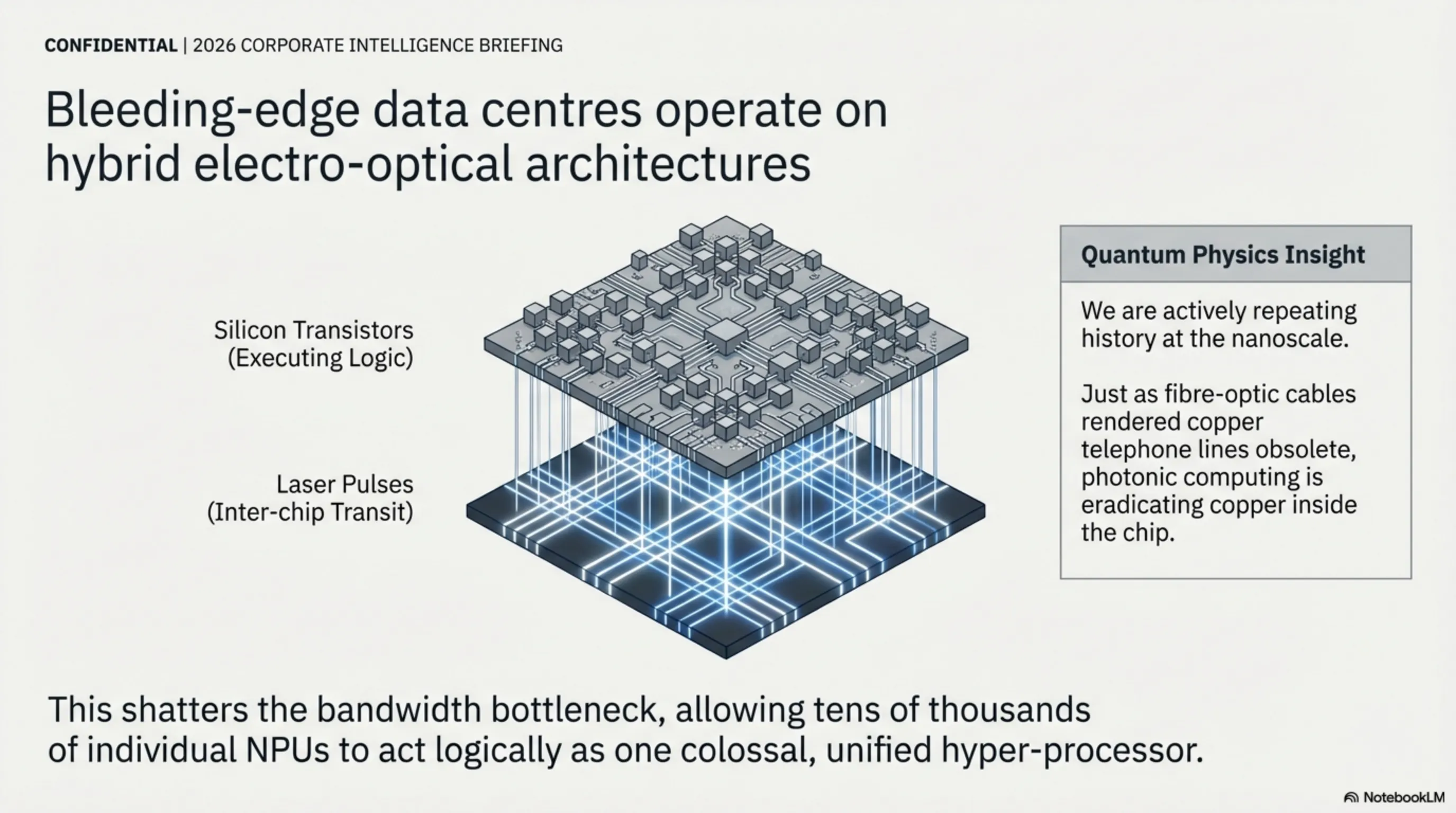
۶.۲ معماری هیبریدیِ نوری-الکترونیکی
دیتاسنترهای فوقپیشرفته اکنون از یک معماری ترکیبی استفاده میکنند؛ محاسبات منطقی هنوز توسط ترانزیستورهای سیلیکونی انجام میشود، اما تمام ارتباطات داخلتراشهای و بینتراشهای از طریق پالسهای نوریِ لیزری صورت میگیرد. این پارادایم شیفت، گلوگاه پهنای باند را به طور کامل از بین برده و اجازه میدهد که دهها هزار NPU طوری با هم کار کنند که گویی همگی یک تراشه واحدِ غولپیکر هستند.
بصیرت فیزیک کوانتوم: ما در حال تکرار تاریخ هستیم. همانطور که فیبر نوری توانست کابلهای مسی تلفن را در شبکه ارتباطات جهانی منسوخ کند، اکنون محاسبات فوتونیک در حال نابود کردن ارتباطات مسی در مقیاس نانومتری درون خود تراشههاست. آینده دیتاسنترها، درخشان و به معنای واقعی کلمه ساخته شده از نور است.
⚖️ رای نهایی و استراتژیک تکین (Verdict)
سقوط پردازندههای مرکزی یک شبه رخ نداد، اما در سال ۲۰۲۶ این سقوط رسمی شد. در معماری فناوری اطلاعات نوین، خریدن سروری که دارای سوکتهای متعدد و قدرتمند x86 (اینتل/AMD) است اما فاقد اسلاتهای توسعه پهنباند جهت نصب کارتهای استنتاجی GPU و NPU است، یک خودکشی اقتصادی محسوب میگردد. شرکتها، صندوقهای سرمایهگذاری و استارتاپها باید نقشه راه بودجه آیتیِ خود را کاملا تغییر دهند؛ CPU اکنون نقش یک "منشی اداری" یا هاب ارتباطی را ایفا میکند، این در حالی است که مغز واقعی عملیات برای تفکر، تولید محتوا، کشف دارو، مهندسی اتوکد و مدیریت داده، تماماً در قلمرو ترانزیستورهای اختصاصی هوش مصنوعی سکنی گزیده است. اگر بسترهای لولهکشی مایع و برق ولتاژ بالا در رَکهای شما وجود ندارد، شما به عصر حجرِ دیتاسنترها تعلق دارید.
گالری تصاویر