تحلیلی عمیق بر نبرد سال ۲۰۲۶ برای حاکمیت هوش مصنوعی روی دسکتاپ میان Intel Core Ultra 200K+ و AMD Ryzen AI PRO 400. ما در این کالبدشکافی فنی، نقش حافظه کش L4 سهبعدی اینتل و واحد NPU شصتتاپسی AMD را در تغییر پارادایم پردازش شخصی بررسی میکنیم. همچنین موضوعاتی چون مرگ هوش مصنوعی ابری در سازمانها، چالشهای تولید ۳ نانومتری TSMC و ظهور عصر AI PC که حاکمیت دادهها را به کاربر بازمیگرداند، مورد بحث قرار گرفته است.
بخش اول: مقدمه و چرا سال ۲۰۲۶ نقطه عطف هوش مصنوعی لوکال است
تا اوایل سال ۲۰۲۵، مفهوم "هوش مصنوعی" برای اکثریت قریب به اتفاقِ کاربران دسکتاپ و لپتاپ، به معنای ارسال درخواست به سرورهای ابری (Cloud) شرکتهایی مانند OpenAI، گوگل یا مایکروسافت بود. کاربر سوالی تایپ میکرد، دادهها به دیتاسنتر ارسال و پردازش شده و بعد جواب برمیگشت. اما این مدل با دو مشکل اساسی دستوپنجه نرم میکرد: اولاً تاخیر شبکه (Network Latency) که گاهی پاسخ را تا چند ثانیه به تعویق میانداخت؛ و ثانیاً نگرانیهای بسیار جدی حریم خصوصی و امنیت دادهها، زیرا تمام اطلاعات حساس سازمانی و شخصی از طریق اینترنت به سرورهای یک شرکت ثالث ارسال میشد.
در بهار ۲۰۲۶، برای اولین بار در تاریخ، هر دو غول تراشهسازی جهان یعنی Intel و AMD به طور همزمان پردازندههایی را برای بازار دسکتاپ و لپتاپ عرضه کردند که دارای واحدهای پردازش عصبی (NPU) فوقالعاده قدرتمندی هستند. این بدان معناست که مدلهای هوش مصنوعی متداول - مانند دستیاران صوتی هوشمند، تولید تصاویر، ویرایش خودکار ویدئو و حتی چتباتهای زبانی سبکتر - میتوانند مستقیماً و به طور کامل روی خودِ لپتاپ یا کامپیوتر رومیزی کاربر اجرا شوند، بدون هیچگونه نیاز به اتصال اینترنت یا سرور ابری. این انقلاب را "هوش مصنوعی لوکال" (On-device AI) یا "AI PC" مینامند.
بخش دوم: معماری Intel Arrow Lake Refresh و حافظه کش L4 سهبعدی
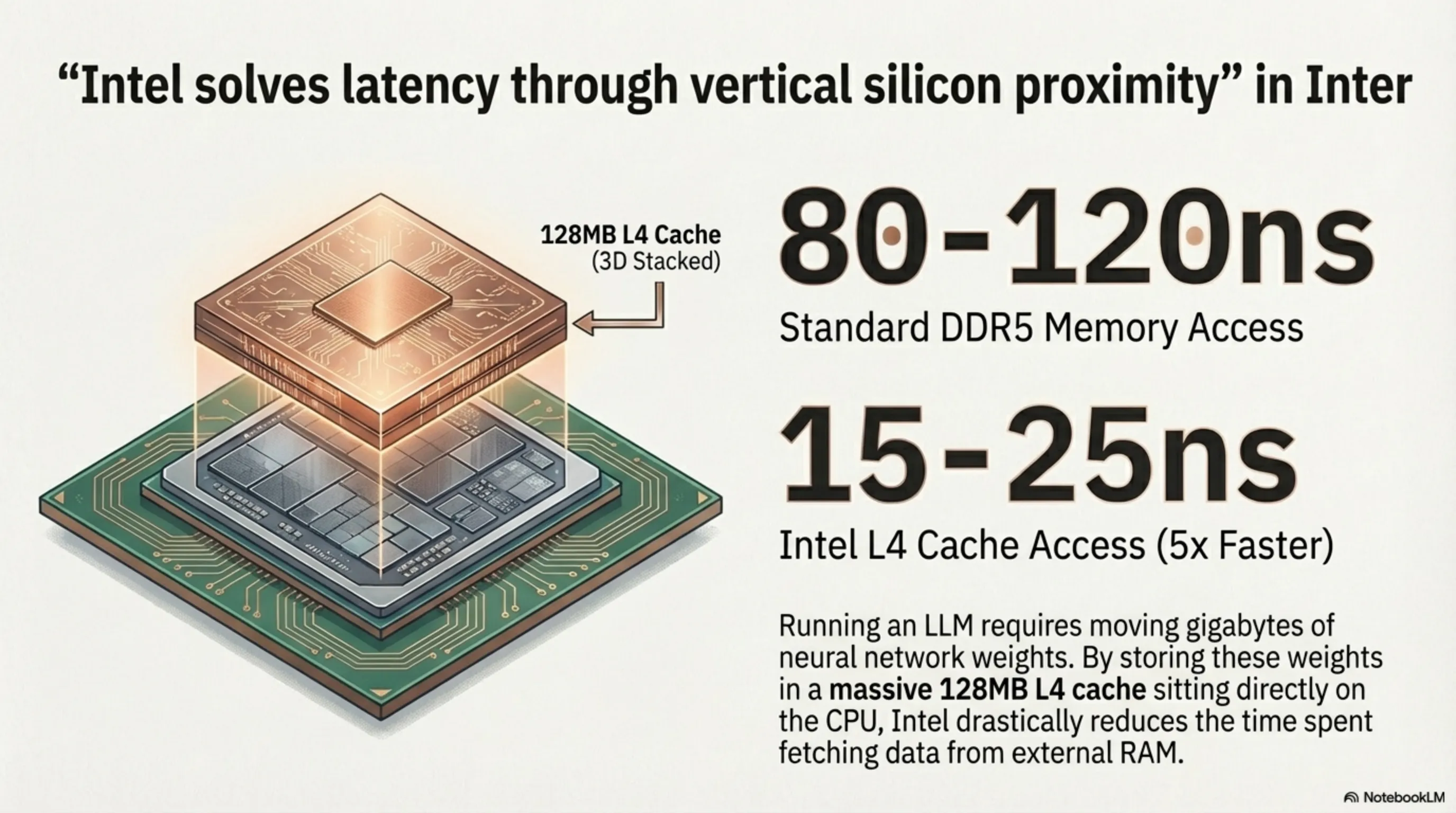
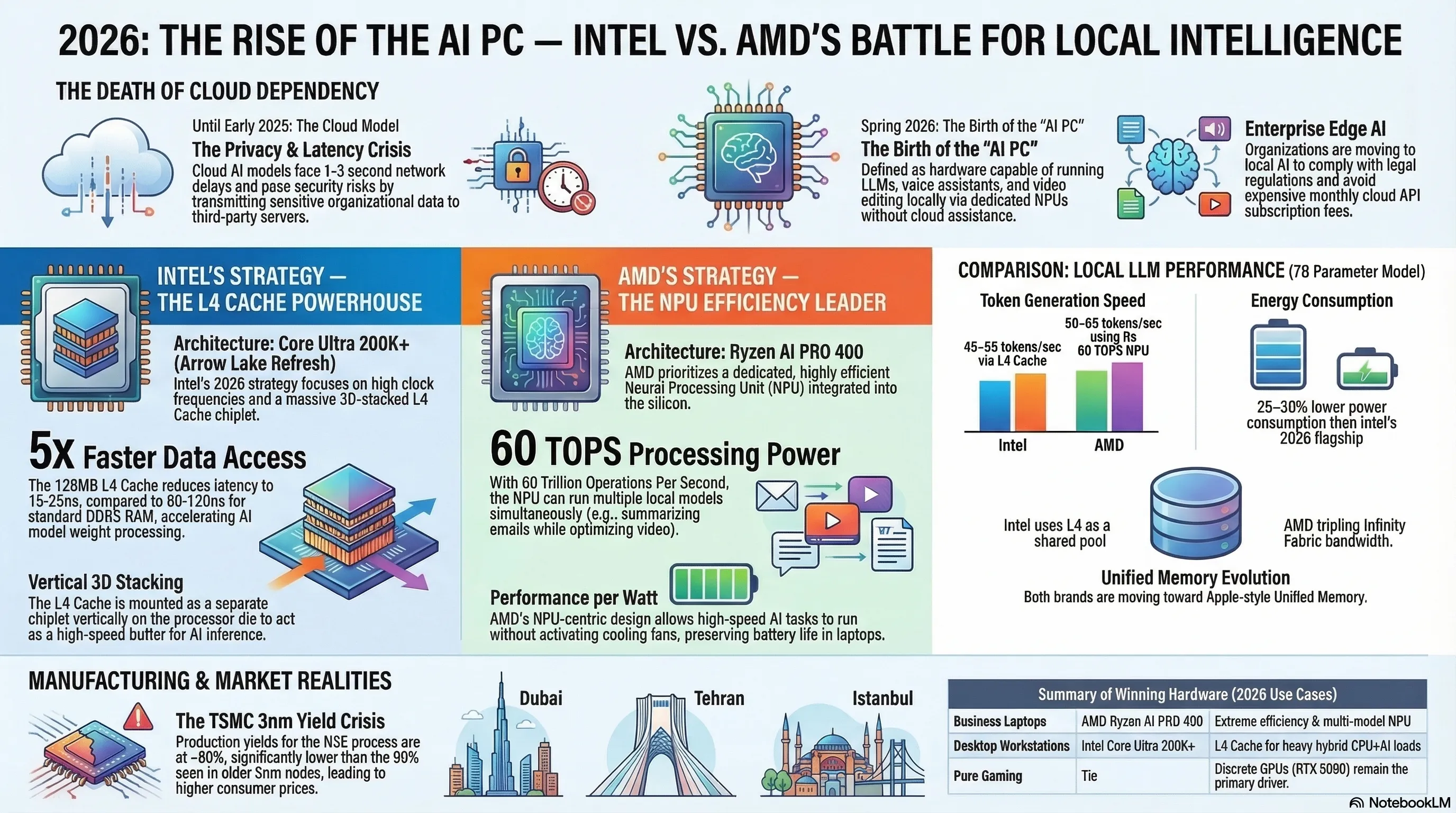
پاسخ استراتژیِ اینتل به رقابت هوش مصنوعی دسکتاپ، سری پردازندههای Core Ultra 200K+ (نامرمز Arrow Lake Refresh) است که در بهار ۲۰۲۶ رسماً معرفی شد. نوآوری اصلی و بزرگ اینتل در این نسل، علاوه بر افزایش فرکانس هستههای عملکردی (Performance Cores)، اضافه کردن یک لایه عظیم از حافظه کش سطح چهارم (L4 Cache) با اتصال سهبعدی عمودی (3D Stacking) است. این حافظه کش به صورت یک تراشه جداگانه (چیپلت) به صورت عمودی روی قالب اصلی پردازنده مونتاژ شده است.
حافظه کش L4 یک میانجی سرسامآور سرعت بین پردازنده و حافظه رم اصلی سیستم (DDR5) است. در حالی که دسترسی به DDR5 حدود ۸۰ تا ۱۲۰ نانوثانیه طول میکشد، کش L4 اینتل دسترسی را به حدود ۱۵ تا ۲۵ نانوثانیه کاهش میدهد (حدود ۵ برابر سریعتر). این مسئله تاثیر سرسامآوری بر اجرای مدلهای هوش مصنوعی دارد: وقتی مدل زبانی (LLM) روی پردازنده در حال استنتاج (Inference) است، وزنهای شبکه عصبی (Model Weights) که حجم آنها ممکن است چندین گیگابایت باشد، باید مدام بین رم و پردازنده جابهجا شوند. با وجود ۱۲۸ مگابایت کش L4، بخش بزرگی از این وزنها مستقیماً در کنار پردازنده ذخیره شده و نیاز به رفتوآمد از رم را به طرز چشمگیری کاهش میدهد.
بخش سوم: ضدحمله AMD: معماری Ryzen AI PRO 400 و NPU یکپارچه ۶۰ TOPS
استراتژی AMD در جنگ هوش مصنوعی دسکتاپ ۲۰۲۶ کاملاً متفاوت است. در حالی که اینتل تمرکزش روی حجم عظیم کش L4 و سرعت کلاک بالای هستهها بود، AMD با سری Ryzen AI PRO 400 تمام تخممرغهایش را در سبد واحد پردازش عصبی اختصاصی (NPU) گذاشته است. NPU یکپارچهی تعبیهشده در قالب سیلیکونی این پردازندهها دارای توان محاسباتی بیسابقه ۶۰ TOPS (تریلیون عملیات در ثانیه) برای عملیات هوش مصنوعی است.
این ۶۰ TOPS به چه کاری میآید؟ برای اجرای لوکال یک مدل زبانی متوسط (مانند یک LLM هفتمیلیارد پارامتری کوانتایز شده)، به حدود ۱۰ تا ۱۵ TOPS قدرت NPU نیاز دارید. با ۶۰ TOPS، پردازنده AMD قادر است همزمان چندین مدل را اجرا کند: یک دستیار هوشمند در پسزمینه ایمیلهایتان را خلاصه کند، یکی دیگر در حال تحلیل صفحهگستردههای مالی باشد، و سومی به صورت بلادرنگ تصاویر وبکم شما را پردازش و بهینهسازی کند، و همه اینها بدون اینکه فن لپتاپ حتی روشن شود!
رمزگشایی ایده AMD اینجاست: به جای اینکه نگران کش و لَتِنسی دسترسی حافظه باشید، NPU اختصاصی ۶۰ تاپسی خودش یک مسیر پردازشی کاملاً مجزا و بهینهشده برای عملیات ماتریسی (Matrix Operations) و ضرب تنسوری (Tensor Multiplication) دارد. AMD ادعا میکند این رویکرد از نظر بازده انرژی (Performance per Watt) بسیار بهتر از اتکا به هستههای عمومی (General-Purpose Cores) با کش عظیم است، زیرا NPU از ابتدا برای محاسبات AI طراحی شده و تراشههایش مصرف انرژی بهینه دارند.

بخش چهارم: TSMC 3nm و بحران بازدهی تولید
هر دو پردازنده اینتل و AMD برای ساخت چیپلتهای کلیدی خود به شدت وابسته به خطوط تولید ۳ نانومتری (N3E) کارخانههای TSMC در تایوان هستند. مسئلهی حیاتی اینجاست: نرخ بازدهی (Yield Rate) خطوط ۳ نانومتری TSMC در اواخر ۲۰۲۵ هنوز به حد ایدهآل نرسیده بود. "بازدهی" به این معناست که از هر ویفر سیلیکونی چند درصد از ترانزیستورها بدون عیب تولید میشوند. در فرآیند ۳nm، تنها یک ذره گردوغبار اتمی میتواند یک تراشه را نابود کند.
اگر نرخ بازدهی پایین باشد، قیمت هر تراشه سالم به شدت بالا میرود. گزارشهای زنجیره تامین DigiTimes در بهار ۲۰۲۶ نشان میدهد که بازدهی N3E به حدود ۸۰ درصد رسیده است (در مقایسه با بازدهی ۸۵ تا ۹۰ درصدیِ فرآیندهای قدیمیتر ۵nm). این ده درصد اختلاف، میلیاردها دلار به هزینه تولید اضافه میکند و مستقیماً روی قیمت تمام شدهی Core Ultra 200K+ و Ryzen AI PRO 400 برای مصرفکننده نهایی تاثیر گذاشته و قیمت آنها را بالاتر از حد انتظار نگه داشته است. این بحران بازدهی، پدیدهای نادر ولی بسیار مهم در صنعت نیمههادی است که مستقیماً زمانبندی عرضه و قیمتگذاری رقابتی را مختل میسازد.
بخش پنجم: مرگ هوش مصنوعی وابسته به ابر در سازمانها
یکی از بزرگترین محرکهای تجاری این جنگ، فشار شدید بخش سازمانی (Enterprise) برای خلاص شدن از اتکای کامل به سرورهای ابری هوش مصنوعی است. شرکتهای حقوقی، بانکها، بیمارستانها و سازمانهای دولتی به دلایل قانونی و امنیتی نمیتوانند دادههای محرمانه بیمار، مشتری یا شهروند را به سرورهای مایکروسافت، گوگل یا هر شرکت خارجی دیگری ارسال کنند.
ورود پردازندههای NPU-دار قدرتمند مانند Core Ultra 200K+ و Ryzen AI PRO 400 به بازار، امکان اجرای کامل مدلهای زبانی و تحلیل دادهها را روی خودِ لپتاپ یا ورکاستیشن کارمند فراهم میسازد. دادهها هرگز از دستگاه خارج نمیشوند. این مدل، موسوم به "Edge AI" یا AI لبهای، در حال از بین بردن صنعتِ چندینمیلیارددلاریِ API ابری هوش مصنوعی است، زیرا سازمانها دیگر نیازی به پرداخت هزینههای سرسامآور اشتراک ماهیانه سرورهای ابری ندارند. این یک تحول اقتصادی بنیادین در صنعت نرمافزار سازمانی محسوب میشود و هر دو شرکت اینتل و AMD در تلاش برای تسخیر بازار لپتاپهای سازمانی با تمام توان تبلیغاتی خود هستند.
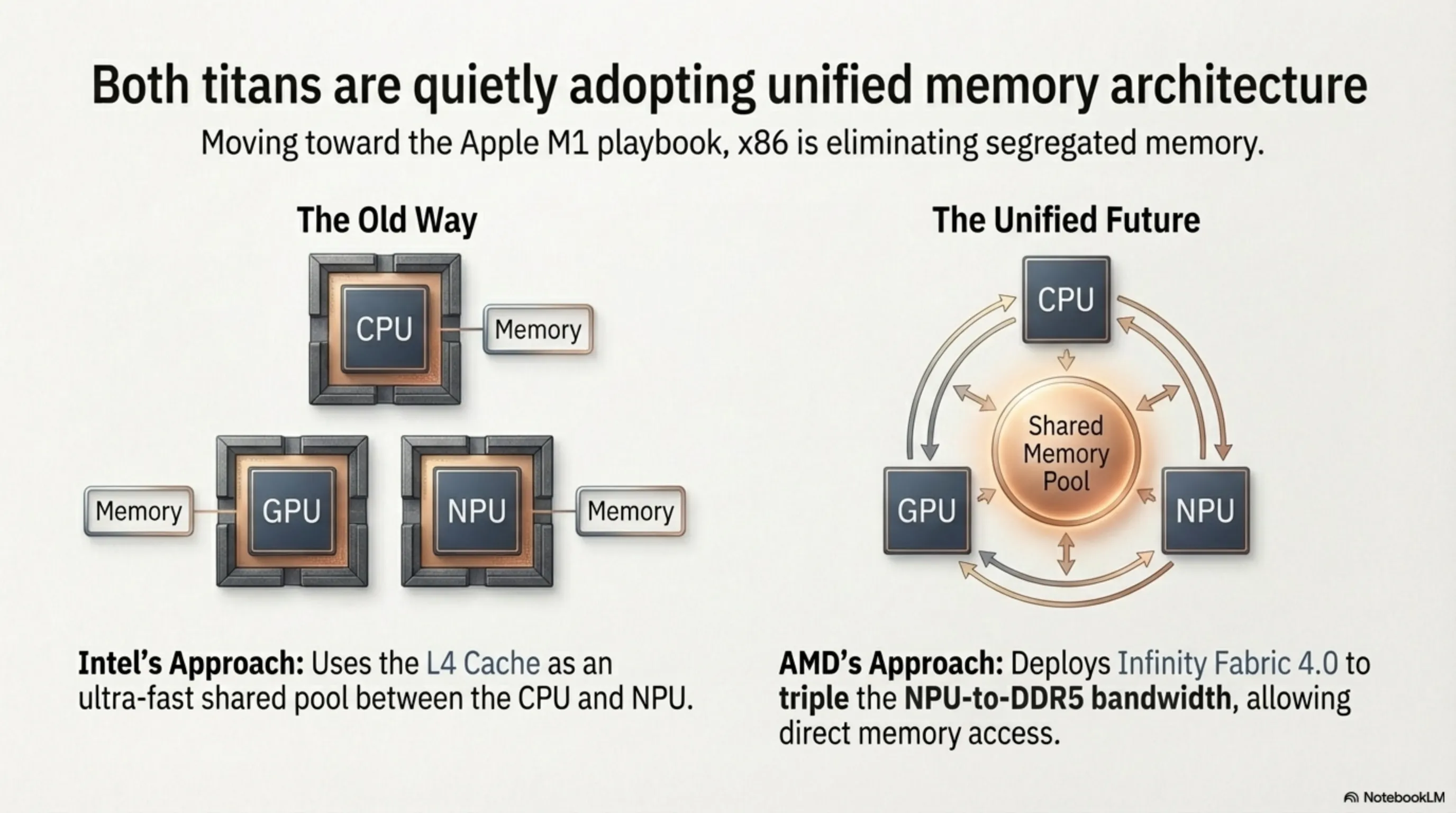
بخش ششم: معماری حافظه یکپارچه روی x86: الهام از اپل سیلیکون
یکی از تحولات پنهان و فوقالعاده مهم در نسل ۲۰۲۶ پردازندهها، حرکت آهسته اما سنگین هر دو شرکت به سمت یکپارچهسازی پهنای باند حافظه (Unified Memory Architecture) است. این مفهوم توسط اپل با تراشه M1 در سال ۲۰۲۰ به صورت تجاری محبوب شد: به جای اینکه CPU، GPU و NPU هرکدام حافظه جداگانهی خود را داشته باشند، تمامی واحدهای پردازشی به یک استخر حافظه واحد و مشترک با پهنای باند فوقالعاده بالا دسترسی دارند.
اینتل و AMD در معماریهای ۲۰۲۶ خود، گامهای بسیار محتاطانهای در این مسیر برداشتهاند. حافظه کش L4 اینتل عملاً به عنوان یک استخر حافظه مشترکِ بسیار سریع بین CPU و NPU عمل میکند. از سوی دیگر، AMD در طراحی Infinity Fabric نسل جدید خود (IF 4.0)، پهنای باند اتصال بین NPU و کنترلر حافظه DDR5 را سه برابر کرده تا NPU بتواند مستقیماً و بدون واسطه از رم سیستم تغذیه کند. هرچند هیچکدام هنوز به یکپارچگی کامل اپل سیلیکون نرسیدهاند، اما مسیر حرکت کاملاً واضح است: آینده x86 یعنی ادغام کامل CPU+GPU+NPU روی یک بستر حافظه واحد.
بخش هفتم: تاخیر کش و تاثیر آن بر استنتاج لوکال مدلهای زبانی
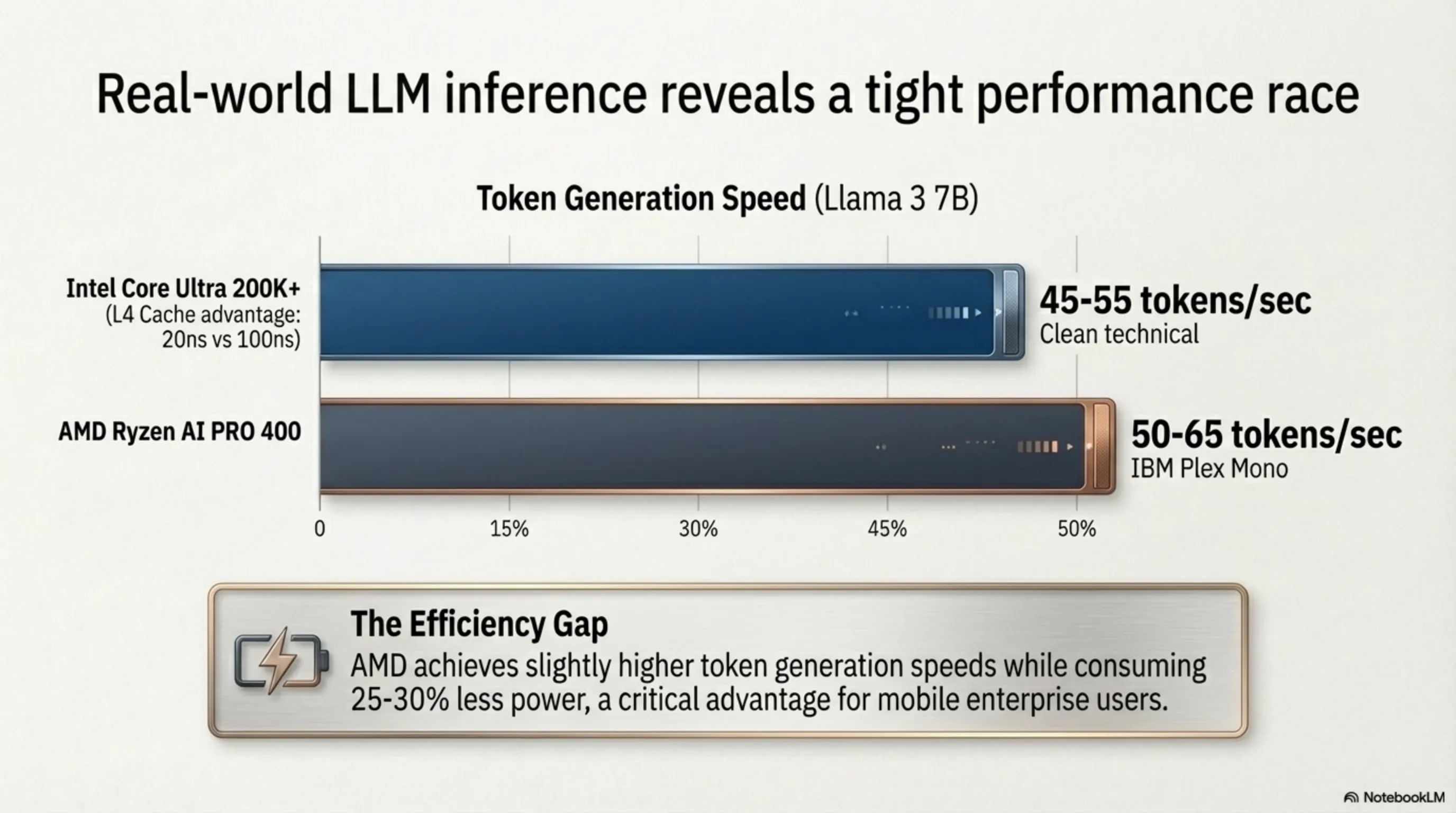
بگذارید برای کاربران فنیتر توضیح دهیم چرا سرعت کش اینقدر در اجرای AI روی دسکتاپ مهم است. وقتی یک مدل زبانی (مثلاً Llama 3 کوانتایز شده با ۷ میلیارد پارامتر) روی پردازنده شما اجرا میشود، هر توکن (کلمه یا بخشی از کلمه) که مدل تولید میکند، نیازمند خواندن صدها مگابایت از وزنهای شبکه عصبی از حافظه است. اگر این وزنها در رم DDR5 باشند، هر بار خواندنشان حدود ۱۰۰ نانوثانیه طول میکشد. اما اگر در کش L4 باشند، این زمان به ۲۰ نانوثانیه کاهش مییابد.
این تفاوت ۸۰ نانوثانیهای وقتی در میلیاردها عملیات ضرب ماتریسی در ثانیه ضرب شود، تبدیل به تفاوتی حیاتی در سرعت تولید توکن (Token Generation Speed) میشود. بنچمارکهای اولیه از بهار ۲۰۲۶ نشان میدهد پردازندهی Core Ultra 200K+ با کش L4 خود قادر است مدل ۷B پارامتری را با سرعت حدود ۴۵ تا ۵۵ توکن بر ثانیه اجرا کند، در حالی که Ryzen AI PRO 400 با NPU ۶۰ تاپسی خود همین مدل را با سرعت ۵۰ تا ۶۵ توکن بر ثانیه اجرا میکند. اما نکته اینجاست: پردازنده AMD این سرعت را با مصرف انرژی ۲۵ تا ۳۰ درصد کمتر نسبت به اینتل انجام میدهد، که برای لپتاپها اهمیت حیاتی دارد.

بخش هشتم: بازار ایران و خاورمیانه: قیمتگذاری و واردات نسل جدید
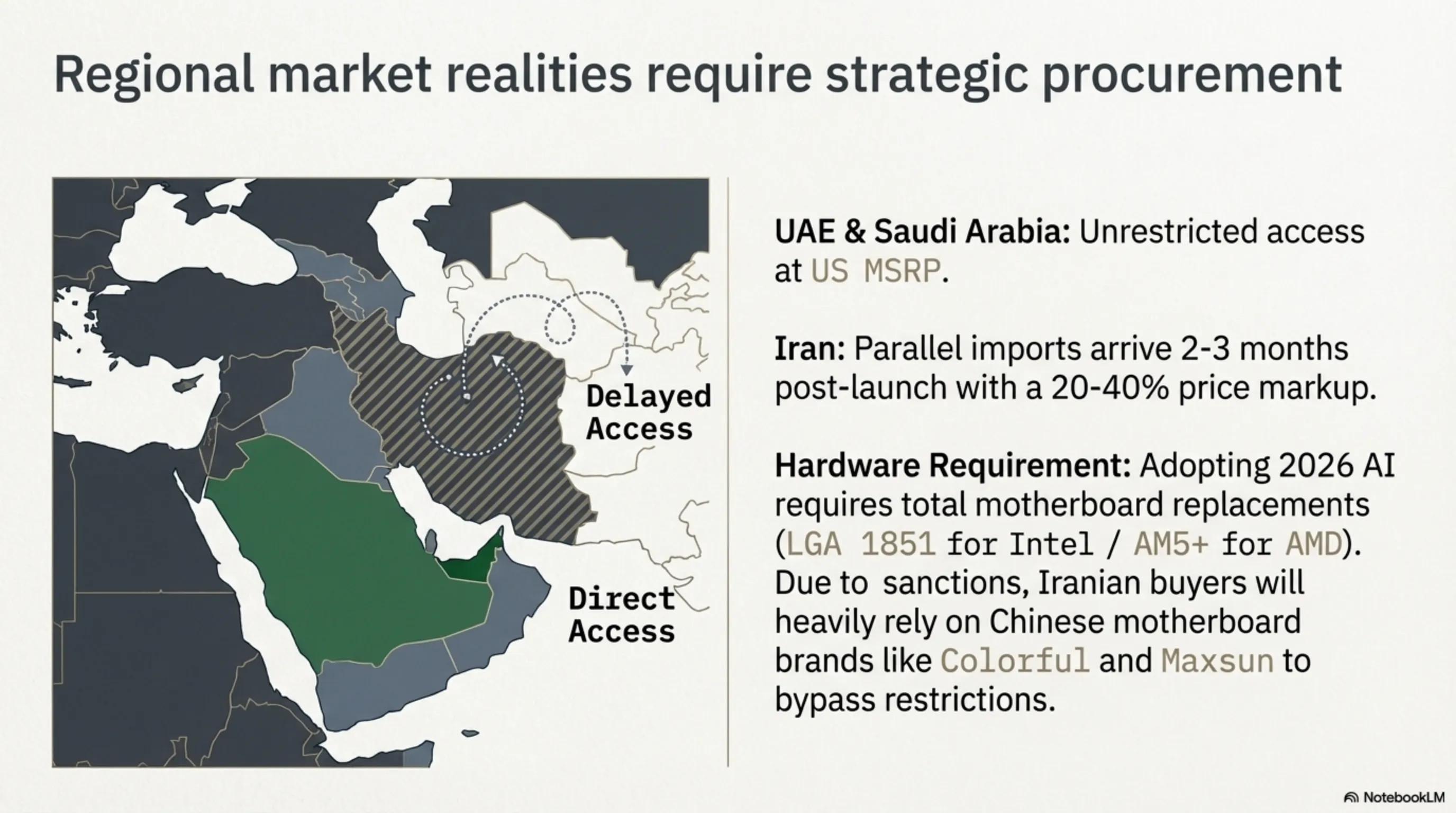
برای کاربران ایرانی و خاورمیانهای، یک سوال حیاتی وجود دارد: آیا این نسل جدید قابل دسترس و خرید خواهد بود؟ تجربه نشان داده که پردازندههای ردهبالای اینتل و AMD معمولاً طی ۲ تا ۳ ماه پس از عرضه جهانی، از طریق بازارهای واردات موازی (مثل پاساژهای کامپیوتری تهران، دبی و استانبول) در دسترس قرار میگیرند. البته با حاشیه سود قابل توجهی: قیمتها معمولاً ۲۰ تا ۴۰ درصد بالاتر از قیمت رسمی آمریکا هستند.
نکته مهمتر برای بازار ایران، مادربردهای سازگار با DDR5 و سوکتهای جدید هستند. برای هر دو پلتفرم (LGA 1851 اینتل و AM5+ ایامدی) مادربردهای جدید لازم است، و با توجه به تحریمها، ورود برندهای درجه یک مادربرد (مثل ASUS ROG و MSI MEG) با تاخیر بیشتری صورت میگیرد. با این حال، برندهای چینی مانند Colorful و Maxsun که از مسیرهای تحریمی عبور میکنند، معمولاً گزینههای اقتصادیتری فراهم خواهند کرد. برای کاربران حرفهای در امارات و عربستان، دسترسی به این سختافزارها بدون هیچ محدودیتی و با قیمتهایی نزدیک به بازار آمریکا ممکن است.
حکم نهایی تیم تحریریه تکین گیم: برنده واقعی جنگ هوش مصنوعی دسکتاپ ۲۰۲۶ کیست؟
برنده لپتاپهای سازمانی و تجاری: AMD Ryzen AI PRO 400 (NPU ۶۰ تاپسی با مصرف انرژی فوقالعاده بهینه، ایدهآل برای اجرای مدلهای AI بدون نیاز به شارژر دائمی.)
برنده رایانه دسکتاپ قدرتمند و ورکاستیشن: Intel Core Ultra 200K+ (کش L4 سهبعدی فوقالعاده سریع + فرکانسهای کلاک بالا، برتری در بارکاریهای ترکیبیِ سنگین CPU+AI.)
برنده بازی و گیمینگ خالص: نتیجه مساوی (NPU و AI لوکال تاثیر چندانی بر گیمینگ خالص ندارند؛ کارتهای گرافیک مجزا مانند RTX 5090 همچنان حرف اول را میزنند.)
تحلیل نهایی: سال ۲۰۲۶ سالی است که هوش مصنوعی رسماً از ابر خارج شده و به زیر انگشتان کاربر دسکتاپ رسیده. رقابت بین Intel و AMD نهتنها باعث کاهش قیمتها و افزایش قدرت NPU خواهد شد، بلکه مدل تجاریِ کل صنعت نرمافزار سازمانی — که تا پارسال وابسته به اشتراکهای ماهیانه API ابری بود — را کاملاً واژگون میسازد. مصرفکنندگان ایرانی و خاورمیانهای باید بدانند: عصر "AI PC" رسماً فرا رسیده و انتخاب پردازنده مناسب، یک تصمیم مصرفی نیست بلکه یک تصمیم استراتژیک چندسالهی حرفهای محسوب میشود.
گالری تخصصی انقلاب AI PC