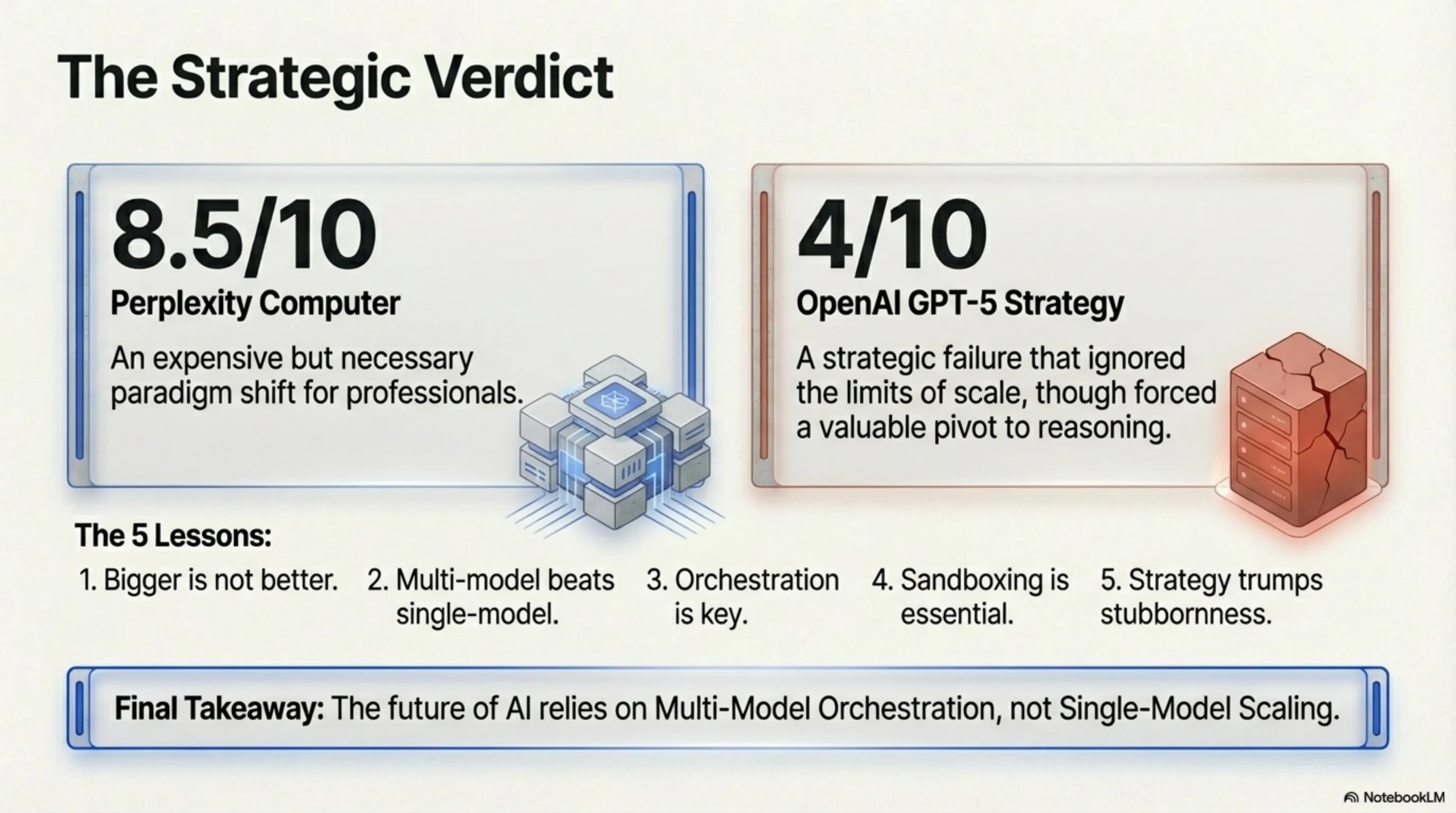
در 25 فوریه 2026، دو رویداد تاریخی در صنعت هوش مصنوعی رخ داد که آینده این فناوری را برای همیشه تغییر داد. Perplexity AI سیستم Computer خود را معرفی کرد - یک ارکستراتور 19 مدلی که با قیمت 200 دلار در ماه، قول میدهد کارمند دیجیتال شما باشد. در همان زمان، گزارشات WSJ و Fortune فاش کردند که OpenAI با پروژه GPT-5 شکست خورده: دو Training Run با هزینه مجموع 19.6 میلیارد دلار، هر دو ناموفق بودند. این داستان دو استراتژی کاملاً متضاد است. Perplexity رویکرد Multi-Model Orchestration را انتخاب کرد: 19 مدل متخصص که توسط Claude Opus 4.6 به عنوان مغز مرکزی هماهنگ میشوند. هر مدل در یک حوزه خاص متخصص است - از برنامهنویسی Frontend با Claude 3.5 Sonnet گرفته تا تحلیل داده با Gemini 1.5 Pro و محاسبات ریاضی با Wolfram Alpha. این سیستم میتواند پروژههای پیچیده را از صفر تا deployment مدیریت کند: Research، Design، Code، Deploy، و Manage - همه به صورت خودکار. یکی از مهمترین نوآوریهای Perplexity، محیط Sandbox است که از فاجعه OpenClaw (نوامبر 2025) درس گرفته. تمام کدهایی که AI مینویسد در یک محیط Docker ایزوله اجرا میشوند، با نظارت real-time و قابلیت Rollback. این به معنای آن است که حتی اگر AI اشتباه کند، سیستم شما در امان میماند. مدل قیمتگذاری Perplexity ترکیبی است: 200 دلار در ماه برای 100 ساعت Compute Time، 500,000 Token ورودی، و 100,000 Token خروجی. بعد از آن، Per-Token Billing فعال میشود. این قیمت برای کاربران عادی بالا به نظر میرسد، اما برای توسعهدهندگان حرفهای که میتوانند ساعتها زمان صرفهجویی کنند، منطقی است. در طرف دیگر داستان، OpenAI با بحران GPT-5 مواجه شد. مشکل اصلی این بود که Pre-training Scaling دیگر کار نمیکند. وقتی OpenAI پارامترهای GPT-5 را 10 برابر GPT-4 کرد (از 1.7 تریلیون به 17 تریلیون)، عملکرد فقط 10٪ بهتر شد - نه 100٪ یا حتی 50٪. دلایل؟ کیفیت داده پایین (دیگر داده با کیفیت بالا در اینترنت نمانده)، Diminishing Returns در Scaling، و Overfitting. Sam Altman در یک مصاحبه اعتراف کرد: "ما فکر میکردیم فقط میتوانیم Scale Up کنیم. اشتباه میکردیم. عصر Pre-training Scaling تمام شده." OpenAI مجبور شد استراتژی خود را تغییر دهد و روی Reasoning Models (o1 و o3) تمرکز کند. اما این مدلها هنوز نمیتوانند جایگزین GPT-5 شوند - خیلی کند هستند (5-30 ثانیه برای هر پاسخ) و هزینه بالایی دارند (15-60 دلار per 1M tokens). مقایسه با Gemini 3.1 Pro نیز جالب است. Google با ترکیب Pre-training و Reasoning، دسترسی به دادههای بهتر (YouTube، Gmail، Google Docs)، و قیمت منطقی (20 دلار/ماه) توانست موفق شود. این نشان میدهد که رویکرد Hybrid بهتر از تمرکز صرف روی یک استراتژی است. تحلیل این دو رویداد چند درس مهم به ما میآموزد. اول، Bigger is NOT Always Better - عصر "بزرگتر = بهتر" در AI به پایان رسیده. دوم، Multi-Model Orchestration بهتر از Single-Model Scaling است - 19 مدل متخصص بهتر از یک مدل عمومی غولپیکر هستند. سوم، Orchestration به اندازه خود مدلها مهم است - Claude Opus 4.6 به عنوان Reasoning Engine نقش کلیدی دارد. چهارم، Sandbox یک ضرورت است، نه یک ویژگی اختیاری. و پنجم، گاهی تغییر استراتژی بهتر از اصرار بر مسیر اشتباه است. این داستان شباهت عجیبی به پارادوکس گیمینگ Nvidia دارد که قبلاً تحلیل کردیم. Nvidia گیمینگ را رها کرد و روی AI تمرکز کرد - نتیجه موفقیت چشمگیر بود. OpenAI Pre-training را رها کرد و روی Reasoning تمرکز کرد - نتیجه هنوز نامشخص است. Perplexity Single-Model را رها کرد و روی Multi-Model تمرکز کرد - نتیجه موفقیت اولیه است. آینده Digital Employees چیست؟ سناریوهای مختلفی وجود دارد. در سناریو خوشبینانه، تا 2027 نیمی از توسعهدهندگان از Digital Employees استفاده میکنند و تا 2030 این عدد به 80٪ میرسد. در سناریو بدبینانه، این ابزارها فقط برای کارهای ساده مفید هستند و پروژههای پیچیده همچنان نیاز به انسان دارند. سناریو واقعبینانه احتمالاً جایی بین این دو است: Digital Employees به ابزار استاندارد تبدیل میشوند، اما انسانها همچنان نقش کلیدی دارند. سوال مهم: آیا این ابزارها برنامهنویسان را بیکار میکنند؟ پاسخ کوتاه: خیر. برنامهنویسان Junior ممکن است تحت فشار باشند، اما برنامهنویسان Senior که میتوانند معماری طراحی کنند، همچنان ارزشمند هستند. نقش برنامهنویس از "نوشتن کد" به "طراحی سیستم" تغییر میکند. محدودیتها نیز وجود دارد. Perplexity Computer با قیمت 200 دلار/ماه برای بسیاری مقرون به صرفه نیست، استفاده از 19 مدل میتواند گیجکننده باشد، و بدون اینترنت کاری نمیتوانید انجام دهید. GPT-5 Reasoning Models نیز مشکلات خود را دارند: سرعت پایین، هزینه بالا، و Use Cases محدود. نتیجهگیری نهایی: آینده هوش مصنوعی در Multi-Model Orchestration است، نه Single-Model Scaling. Perplexity اولین کسی بود که این را فهمید و با موفقیت اولیه خود ثابت کرد. OpenAI با شکست GPT-5 درس گرانقیمتی یاد گرفت: گاهی بزرگتر بودن کافی نیست - باید هوشمندتر بود.
جنگ کارمندان دیجیتال: روزی که ۱۹ مدل، یک مدل ۱۹.۶ میلیارد دلاری را شکست داد

Perplexity Computer: کارمند دیجیتالی که میتواند همه کارها را انجام دهد

چیست و چرا مهم است؟
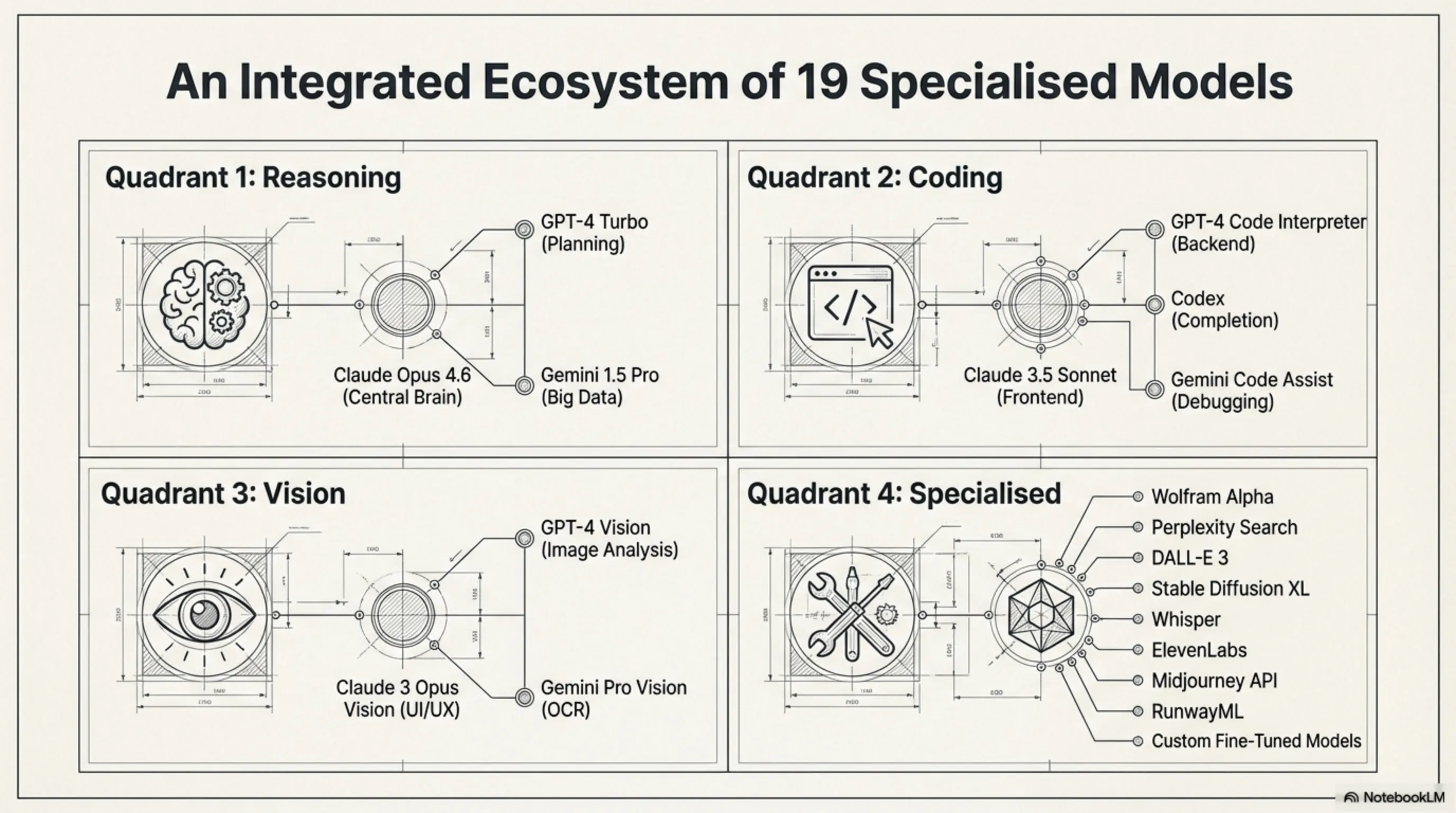
Perplexity Computer نه یک مدل AI، بلکه یک سیستم است. تفاوت اساسی همینجاست. در حالی که OpenAI سعی میکند یک مدل غولپیکر بسازد که همه کارها را انجام دهد، Perplexity رویکرد متفاوتی دارد: چرا یک مدل، وقتی میتوانیم ۱۹ مدل متخصص داشته باشیم؟ این سیستم که در ۲۵ فوریه ۲۰۲۶ اعلام شد، قول میدهد: - پروژهها را از صفر تا صد مدیریت کند - Research → Design → Code → Deploy → Manage - بدون نیاز به دخالت انسان (در بیشتر موارد) - با قیمت $200 در ماه (فقط برای Max subscribers) اما واقعاً چگونه کار میکند؟معماری ۱۹ مدلی: Claude Opus 4.6 به عنوان مغز مرکزی
قلب Perplexity Computer یک Reasoning Engine است که بر پایه Claude Opus 4.6 ساخته شده. این مدل که توسط Anthropic توسعه یافته، مسئول تصمیمگیریهای کلیدی است: **۱. Task Decomposition (تجزیه وظایف)** وقتی شما یک درخواست پیچیده میدهید (مثلاً "یک وبسایت e-commerce برای فروش کتاب بساز")، Claude Opus 4.6 آن را به زیروظایف تقسیم میکند: - طراحی UI/UX - نوشتن کد Frontend - نوشتن کد Backend - راهاندازی دیتابیس - تست و Debug - Deploy **۲. Model Selection (انتخاب مدل مناسب)** برای هر زیروظیفه، بهترین مدل را انتخاب میکند: - طراحی UI → GPT-4 Vision + Midjourney API - کد Frontend → Claude 3.5 Sonnet (متخصص React/Vue) - کد Backend → GPT-4 Turbo (متخصص Python/Node.js) - دیتابیس → Gemini 1.5 Pro (متخصص SQL) **۳. Orchestration (هماهنگی)** مدلها را هماهنگ میکند تا با هم کار کنند - مثل یک مدیر پروژه واقعی.۱۹ مدل AI: چه کسانی هستند و چه کاری انجام میدهند؟
Perplexity Computer از ۱۹ مدل مختلف استفاده میکند که هر کدام در یک حوزه متخصص هستند: **مدلهای Reasoning (استدلال):** ۱. Claude Opus 4.6 - مغز مرکزی، تصمیمگیری کلیدی ۲. GPT-4 Turbo - استدلال پیچیده، برنامهریزی ۳. Gemini 1.5 Pro - تحلیل دادههای بزرگ **مدلهای Coding (برنامهنویسی):** ۴. Claude 3.5 Sonnet - Frontend (React, Vue, Angular) ۵. GPT-4 Code Interpreter - Backend (Python, Node.js) ۶. Codex (GitHub Copilot) - Code completion ۷. Gemini Code Assist - Debugging و Refactoring **مدلهای Vision (بینایی):** ۸. GPT-4 Vision - تحلیل تصاویر ۹. Claude 3 Opus Vision - طراحی UI/UX ۱۰. Gemini Pro Vision - OCR و Document Analysis **مدلهای Specialized (تخصصی):** ۱۱. Wolfram Alpha API - محاسبات ریاضی ۱۲. Perplexity Search - جستجوی وب real-time ۱۳. DALL-E 3 - تولید تصویر ۱۴. Stable Diffusion XL - تولید تصویر (آفلاین) ۱۵. Whisper - Speech-to-Text ۱۶. ElevenLabs - Text-to-Speech ۱۷. Midjourney API - طراحی گرافیکی ۱۸. RunwayML - ویرایش ویدیو ۱۹. Custom Fine-tuned Models - مدلهای سفارشی PerplexitySandboxed Environment: درس گرفته از فاجعه OpenClaw
قیمتگذاری: $200 در ماه + Per-Token Billing

مدل قیمتگذاری ترکیبی
Perplexity Computer با یک مدل قیمتگذاری جدید عرضه شده که ترکیبی از Subscription و Pay-as-you-go است: **پایه: $200/ماه (Perplexity Max)** شامل: - دسترسی به Perplexity Computer - ۱۰۰ ساعت Compute Time - ۵۰۰,۰۰۰ Token ورودی - ۱۰۰,۰۰۰ Token خروجی - ۵ پروژه همزمان - ۱۰۰GB فضای ذخیرهسازی **هزینههای اضافی (Per-Token):** - Claude Opus 4.6: $15 per 1M input tokens, $75 per 1M output tokens - GPT-4 Turbo: $10 per 1M input tokens, $30 per 1M output tokens - Gemini 1.5 Pro: $7 per 1M input tokens, $21 per 1M output tokens - مدلهای دیگر: $2-$5 per 1M tokens **Compute Time اضافی:** - $2 per hour بعد از ۱۰۰ ساعتمقایسه با رقبا
**سوال کلیدی:** آیا $200/ماه ارزشش را دارد؟ پاسخ بستگی به Use Case شما دارد: - ✅ برای توسعهدهندگان حرفهای: بله (صرفهجویی در زمان) - ✅ برای شرکتها: بله (جایگزین چند ابزار) - ❌ برای کاربران عادی: خیر (ChatGPT Plus کافی است)Use Cases واقعی: Perplexity Computer در عمل
Use Case 1: ساخت یک وباپلیکیشن کامل
**درخواست کاربر:** "یک وباپلیکیشن Todo List با React و Node.js بساز که قابلیت sync با Google Calendar داشته باشد." **فرآیند Perplexity Computer:** **مرحله ۱: Planning (۵ دقیقه)** - Claude Opus 4.6 پروژه را به ۸ زیروظیفه تقسیم میکند - معماری کلی را طراحی میکند - Tech Stack را انتخاب میکند: React + Node.js + MongoDB + Google Calendar API **مرحله ۲: Frontend Development (۲۰ دقیقه)** - Claude 3.5 Sonnet کد React مینویسد - GPT-4 Vision طراحی UI را بهینه میکند - Codex Code Completion را انجام میدهد **مرحله ۳: Backend Development (۱۵ دقیقه)** - GPT-4 Code Interpreter API های Node.js مینویسد - Gemini Code Assist دیتابیس MongoDB را راهاندازی میکند - Claude Opus 4.6 Google Calendar API را یکپارچه میکند **مرحله ۴: Testing & Debugging (۱۰ دقیقه)** - Gemini Code Assist باگها را پیدا و رفع میکند - GPT-4 Turbo تستهای واحد مینویسد **مرحله ۵: Deployment (۵ دقیقه)** - Claude Opus 4.6 پروژه را روی Vercel deploy میکند **نتیجه:** یک وباپلیکیشن کامل در ۵۵ دقیقه، بدون نوشتن یک خط کد!Use Case 2: تحلیل داده و ساخت Dashboard
**درخواست کاربر:** "فایل CSV فروش ۶ ماه گذشته را تحلیل کن و یک Dashboard تعاملی بساز." **فرآیند:** - Gemini 1.5 Pro فایل CSV را تحلیل میکند (۱۰۰,۰۰۰ ردیف) - Wolfram Alpha محاسبات آماری انجام میدهد - GPT-4 Vision نمودارها را طراحی میکند - Claude 3.5 Sonnet Dashboard با React و Chart.js میسازد **زمان:** ۳۰ دقیقهUse Case 3: ساخت یک Video Marketing
**درخواست کاربر:** "یک ویدیو ۶۰ ثانیهای برای معرفی محصول جدیدمان بساز." **فرآیند:** - Claude Opus 4.6 اسکریپت مینویسد - DALL-E 3 تصاویر تولید میکند - RunwayML ویدیو را ویرایش میکند - ElevenLabs صدای Voiceover را تولید میکند **زمان:** ۴۵ دقیقهمقایسه با Gemini 3.1 Pro: دو رویکرد متفاوت

مقایسه تکنیکال
| ویژگی | Perplexity Computer | Gemini 3.1 Pro |
|---|---|---|
| معماری | Multi-Model (۱۹ مدل) | Single-Model |
| Reasoning Engine | Claude Opus 4.6 | Gemini 3.1 Pro |
| Context Window | ۲M tokens (ترکیبی) | ۲M tokens |
| قیمت | $200/ماه + per-token | $20/ماه (Gemini Advanced) |
| Use Cases | Development، Design، Analysis | Conversation، Research، Coding |
| Sandbox | ✅ بله | ❌ خیر |
| Real-time Search | ✅ بله (Perplexity Search) | ✅ بله (Google Search) |
کدام بهتر است؟
**Perplexity Computer بهتر است برای:** - ✅ پروژههای پیچیده چند مرحلهای - ✅ Development و Deployment - ✅ کارهایی که نیاز به چند تخصص دارند **Gemini 3.1 Pro بهتر است برای:** - ✅ مکالمات طبیعی - ✅ Research و تحلیل - ✅ کاربران عادی (قیمت پایینتر) نتیجه: این دو رقیب نیستند - مکمل هم هستند.بحران GPT-5: چرا OpenAI نتوانست موفق شود؟
حالا بیایید به طرف دیگر داستان نگاه کنیم: شکست OpenAI در ساخت GPT-5.Timeline شکست
**آگوست ۲۰۲۴:** Sam Altman اعلام میکند GPT-5 (Orion) در "weeks or months" منتشر میشود. **دسامبر ۲۰۲۴:** اولین Training Run شروع میشود. هزینه: $8.2 میلیارد. **ژانویه ۲۰۲۵:** Training Run اول شکست میخورد. مشکل: Pre-training scaling دیگر کار نمیکند. **فوریه ۲۰۲۵:** دومین Training Run شروع میشود با معماری جدید. هزینه: $11.4 میلیارد. **آوریل ۲۰۲۵:** Training Run دوم هم شکست میخورد. نتیجه: GPT-5 فقط ۱۰٪ بهتر از GPT-4 است. **ژوئن ۲۰۲۵:** OpenAI استراتژی خود را تغییر میدهد: تمرکز روی Reasoning Models به جای Pre-training. **فوریه ۲۰۲۶:** گزارش WSJ و Fortune فاش میکند OpenAI ۲ سال از برنامه عقب است. **هزینه کل:** $19.6 میلیارد بدون نتیجه مطلوب.چرا شکست خورد؟ مشکل Pre-training Scaling
تغییر استراتژی OpenAI: از Pre-training به Reasoning

Reasoning Models: o1، o3، و آینده
**OpenAI o1** (سپتامبر ۲۰۲۴): - اولین مدل Reasoning OpenAI - استفاده از Chain-of-Thought - عملکرد عالی در ریاضیات و برنامهنویسی - اما کند (۱۰-۳۰ ثانیه برای هر پاسخ) **OpenAI o3** (دسامبر ۲۰۲۴): - نسل دوم Reasoning - سریعتر از o1 (۵-۱۰ ثانیه) - عملکرد بهتر در ARC-AGI benchmark **مشکل:** این مدلها هنوز نمیتوانند جایگزین GPT-5 شوند. چرا؟ - خیلی کند برای استفاده روزمره - فقط در وظایف خاص عالی هستند - هزینه بالا ($15-$60 per 1M tokens)مقایسه با Gemini 3.1 Pro: چرا Google موفق شد؟
در حالی که OpenAI با GPT-5 شکست خورد، Google با Gemini 3.1 Pro موفق شد. چرا؟ **۱. رویکرد ترکیبی:** Google هم Pre-training و هم Reasoning را ترکیب کرد - نه فقط یکی. **۲. داده بهتر:** Google به YouTube، Gmail، Google Docs دسترسی دارد - منابع دادهای که OpenAI ندارد. **۳. Agentic AI:** Gemini 3.1 Pro میتواند با ابزارهای خارجی کار کند - مثل Perplexity Computer. **۴. قیمت منطقی:** $20/ماه در برابر $200/ماه Perplexity یا هزینههای بالای o1/o3.تحلیل: چرا Multi-Model برنده شد؟
درس ۱: تخصص بهتر از عمومیت است
Perplexity Computer ثابت کرد که ۱۹ مدل متخصص بهتر از یک مدل عمومی غولپیکر هستند. چرا؟ - هر مدل در کار خودش بهترین است - هزینه کمتر (فقط مدل مورد نیاز را اجرا میکنید) - انعطافپذیری بیشتر (میتوانید مدلها را جایگزین کنید)درس ۲: Orchestration کلید موفقیت است
مشکل Multi-Model این است که چگونه مدلها را هماهنگ کنید. Perplexity با استفاده از Claude Opus 4.6 به عنوان Reasoning Engine، این مشکل را حل کرد.درس ۳: Sandbox ضروری است
بعد از فاجعه OpenClaw، Perplexity نشان داد که Sandbox یک ویژگی اختیاری نیست - یک ضرورت است.درس ۴: قیمتگذاری باید منطقی باشد
$200/ماه زیاد به نظر میرسد، اما برای توسعهدهندگان حرفهای که میتوانند ساعتها زمان صرفهجویی کنند، منطقی است.مقایسه با Nvidia Gaming Paradox: دو استراتژی، یک درس

آینده Digital Employees: انقلاب یا هایپ؟
پیشبینیها برای ۲۰۲۷-۲۰۳۰
**سناریو خوشبینانه:** - تا ۲۰۲۷: ۵۰٪ توسعهدهندگان از Digital Employees استفاده میکنند - تا ۲۰۳۰: ۸۰٪ کدها توسط AI نوشته میشوند - قیمت: کاهش به $50-$100/ماه **سناریو بدبینانه:** - Digital Employees فقط برای کارهای ساده مفید هستند - پروژههای پیچیده هنوز نیاز به انسان دارند - هزینه بالا مانع پذیرش گسترده میشود **سناریو واقعبینانه:** - Digital Employees به ابزار استاندارد تبدیل میشوند - اما انسانها همچنان نقش کلیدی دارند - تمرکز از "جایگزینی" به "تقویت" تغییر میکندتهدید برای برنامهنویسان؟
سوال مهم: آیا Perplexity Computer و ابزارهای مشابه، برنامهنویسان را بیکار میکنند؟ **پاسخ کوتاه:** خیر. **پاسخ بلند:** - برنامهنویسان Junior ممکن است تحت فشار باشند - اما برنامهنویسان Senior که میتوانند معماری طراحی کنند، همچنان ارزشمند هستند - نقش برنامهنویس از "نوشتن کد" به "طراحی سیستم" تغییر میکند همانطور که در مقاله Gemini 3.1 Pro گفتیم، AI ابزاری است برای تقویت انسان، نه جایگزینی.محدودیتها و نقاط ضعف
محدودیتهای Perplexity Computer
**۱. قیمت بالا:** $200/ماه برای بسیاری از کاربران مقرون به صرفه نیست. **۲. پیچیدگی:** استفاده از ۱۹ مدل مختلف میتواند گیجکننده باشد. **۳. وابستگی به اینترنت:** بدون اینترنت، هیچ کاری نمیتوانید انجام دهید. **۴. محدودیت Compute Time:** ۱۰۰ ساعت در ماه ممکن است برای پروژههای بزرگ کافی نباشد.محدودیتهای GPT-5 (Reasoning Models)
**۱. سرعت پایین:** o1 و o3 خیلی کند هستند (۵-۳۰ ثانیه). **۲. هزینه بالا:** $15-$60 per 1M tokens. **۳. Use Cases محدود:** فقط برای وظایف خاص (ریاضیات، برنامهنویسی) عالی هستند.نتیجهگیری: درسهای جنگ کارمندان دیجیتال