
1. 🧠 آناتومی یک صدای جادویی: چرا صدای مستند خاص است؟
قبل از اینکه دست به موس ببریم و دکمه "Generate" را فشار دهیم، باید بدانیم دنبال چه خروجیای هستیم. اگر ندانید مقصد کجاست، بهترین نقشه هم به دردتان نمیخورد. صدای یک راوی مستند (Narrator) با صدای یک گوینده اخبار یا یک پادکستر فرق دارد. بیایید سه ویژگی کلیدی آن را کالبدشکافی کنیم:
الف) ریتم و مکث (Pacing & Pauses)
راوی مستند عجله ندارد. او میداند که تصویر دارد داستان را تعریف میکند و صدا فقط یک مکمل است. بزرگترین اشتباه کاربران هوش مصنوعی این است که متنی طولانی را بدون مکث به خورد AI میدهند. نتیجه؟ صدایی که مثل مسلسل کلمات را شلیک میکند. راوی خوب، بین جملات نفس میکشد تا مخاطب فرصت هضم اطلاعات را داشته باشد.
ب) دامنه دینامیکی (Dynamic Range)
صدای انسان "خطی" نیست. وقتی درباره شکار یک یوزپلنگ صحبت میکنیم، صدا باید کمی "تند، تیز و هیجانی" باشد. اما وقتی درباره مرگ یک ستاره در کهکشان صحبت میکنیم، صدا باید "بم، عمیق و فیلسوفانه" شود. هوش مصنوعیهای قدیمی "مونوتون" (یکنواخت) بودند، اما ابزارهای نسل جدید ۲۰۲۶ قابلیت درک این "احساسات متنی" را دارند.
ج) فرکانسهای بم (Low-End Frequency)
به صدای مورگان فریمن فکر کنید. چه چیزی آن را جذاب میکند؟ لرزشهای بم و عمیق در سینه. این فرکانسها حس "اعتماد" و "اقتدار" (Authority) را منتقل میکنند. ما در بخش میکس صدا یاد میگیریم چطور حتی اگر صدای هوش مصنوعی کمی نازک بود، این فرکانسها را به صورت مصنوعی تقویت کنیم.
2. 💎 بخش اول: ElevenLabs؛ پادشاه کیفیت
بیایید با بهترین گزینه شروع کنیم. ElevenLabs در حال حاضر استاندارد طلایی صنعت است. مدل Multilingual v2 این شرکت، زبان فارسی را چنان دقیق و با لهجه صحیح صحبت میکند که گاهی ترسناک میشود.
گام ۱: کلون کردن صدا (Instant Voice Cloning)
شما دو راه دارید: یا از صداهای آماده (Pre-made) استفاده کنید که عالی هستند، یا صدای خودتان (یا یک صدای خاص) را کلون کنید. برای کلون کردن:

- به تب VoiceLab بروید و روی علامت مثبت (+) کلیک کنید.
- گزینه Instant Voice Cloning را انتخاب کنید.
- نکته حیاتی برای آپلود فایل: فایلی که آپلود میکنید باید "تمیز" باشد. بدون موزیک پسزمینه، بدون نویز کولر و بدون اکو. اما مهمتر از کیفیت، "لحن" فایل است. اگر میخواهید خروجی شما "راوی مستند" باشد، باید فایل نمونهای که آپلود میکنید هم با لحن آرام و سنگین خوانده شده باشد. اگر فایل نمونه شما یک مکالمه تلفنی هیجانی باشد، هوش مصنوعی همیشه با همان هیجان صحبت خواهد کرد!
گام ۲: رمزگشایی از اسلایدرهای تنظیمات (Settings)
وقتی متن را نوشتید، با ۴ اسلایدر مهم روبرو میشوید که حکم فرمان ماشین را دارند:
- Stability (پایداری): این مهمترین تنظیم است.
مقدار بالا (۱۰۰٪): صدا کاملاً پایدار، بدون لرزش، اما کمی رباتیک و خبری.
مقدار پایین (۳۰٪): صدا بسیار احساسی، با نوسانات زیاد و "انسانی".
فرمول پیشنهادی بازرس: برای مستند، این عدد را روی ۴۰ تا ۵۰ درصد بگذارید. ما میخواهیم صدا کمی "نفس" و "لرزش دراماتیک" داشته باشد. - Similarity (شباهت): چقدر سعی کند شبیه فایل اصلی باشد؟
توصیه میکنم روی ۷۵٪ نگه دارید. اگر به ۱۰۰٪ ببرید، هوش مصنوعی ممکن است "نویزهای" فایل اصلی را هم به عنوان بخشی از شخصیت صدا بازسازی کند. - Style Exaggeration (مبالغه در سبک):
این اسلایدر خطرناک است! اگر زیادش کنید (بالای ۳۰٪)، صدا ممکن است عجیب و غریب شود یا حروف را بجود. برای کارهای فارسی معمولاً ۱۰٪ تا ۱۵٪ کافی است.
ترفند حرفهای: Speech-to-Speech (جادوی بازیگری)
این ویژگی "Game Changer" است. فرض کنید میخواهید روی ویدیو نریشن بگویید، اما صدای خودتان را دوست ندارید.
در حالت Speech-to-Speech، شما متن را خودتان با میکروفون گوشی میخوانید و تمام "احساسات"، "مکثها" و "تاکیدها" را اجرا میکنید. سپس هوش مصنوعی، صدای شما را میگیرد و آن را با "رنگ صدای" (Timbre) گوینده حرفهای جایگزین میکند.
نتیجه؟ اجرایی کاملاً انسانی و دقیق، اما با صدایی سینمایی. این بهترین روش برای ساخت مستندهای احساسی است.
3. 📝 مهندسی پرامپت صوتی: نوشتن برای گوش
هوش مصنوعی ElevenLabs باهوش است، اما ذهنخوان نیست. شما میتوانید با استفاده از علائم نگارشی، به او دستور بدهید چطور صحبت کند. این کار دقیقاً مثل کارگردانی یک بازیگر است:
- مکث کوتاه: از کاما (،) استفاده کنید. "اینجا جنگل آمازون است، ریه زمین."
- مکث بلند و دراماتیک: از خط تیره (—) یا سه نقطه (...) استفاده کنید.
"شیر آرام نزدیک شد... و ناگهان... حمله کرد!" - تغییر لحن: جملات سوالی (؟) لحن را بالا میبرند و نقطه (.) لحن را تمام میکند.
- نقل قول: اگر میخواهید صدای راوی کمی تغییر کند (مثلاً دارد از زبان کسی حرف میزند)، متن را داخل گیومه " " بگذارید.
تمرین عملی: یک پاراگراف را یک بار بدون علائم نگارشی و یک بار با علائم دقیق به هوش مصنوعی بدهید. تفاوت زمین تا آسمان است. نسخه اول یک "ربات" است، نسخه دوم یک "قصهگو".
4. 🛠️ بخش دوم: OpenVoice؛ جراح پلاستیک صدا
اگر بودجه اشتراک دلاری ندارید یا میخواهید روی پروژههای خاصتر (مثل تغییر صدای یک ویدیوی آماده) کار کنید، OpenVoice گزینه شماست. این پروژه که توسط محققان MIT و MyShell توسعه یافته، یک ویژگی جادویی دارد: Tone Color Converter.
مفهوم Tone Color Converter چیست؟
تصور کنید صدا دو بخش دارد: ۱. محتوا (Content): کلماتی که گفته میشود. ۲. رنگ (Tone Color): ویژگیهای فیزیکی صدای گوینده (بم بودن، خش دار بودن، لهجه).
OpenVoice میتواند این دو را از هم جدا کند. یعنی میتواند "رنگ صدای" مورگان فریمن را بردارد و روی "محتوای" صدای شما (که فارسی حرف میزنید) اعمال کند. خروجی؟ مورگان فریمن که سلیس فارسی حرف میزند!
راهکار طلایی برای فارسی (تکنیک ترکیبی)
OpenVoice به تنهایی هنوز در تولید متنبهگفتار فارسی (TTS) به پای ElevenLabs نمیرسد. اما ما یک ترفند داریم:
- تولید بیس (Base Generation): ابتدا متن فارسی خود را با یک سرویس رایگان و باکیفیت (مثل Microsoft Edge TTS که رایگان است و فارسی را عالی میخواند) تبدیل به فایل صوتی کنید. نگران نباشید که صدای مایکروسافت تکراری است.
- انتخاب مرجع (Reference): یک فایل ۱۰ ثانیهای از صدای راوی مورد علاقهتان (مثلاً صدای خسرو شکیبایی یا یک گوینده خارجی) پیدا کنید.
- ترکیب در OpenVoice: حالا در پلتفرم OpenVoice (یا MyShell)، فایل صدای مایکروسافت را به عنوان "Source" و فایل صدای خسرو شکیبایی را به عنوان "Reference" بدهید.
- جادو: هوش مصنوعی، لحن و رنگ صدای شکیبایی را روی فایل مایکروسافت اعمال میکند. حالا شما متنی دارید که با دقت مایکروسافت خوانده شده، اما جنس صدای آن کاملاً متفاوت و هنری است.

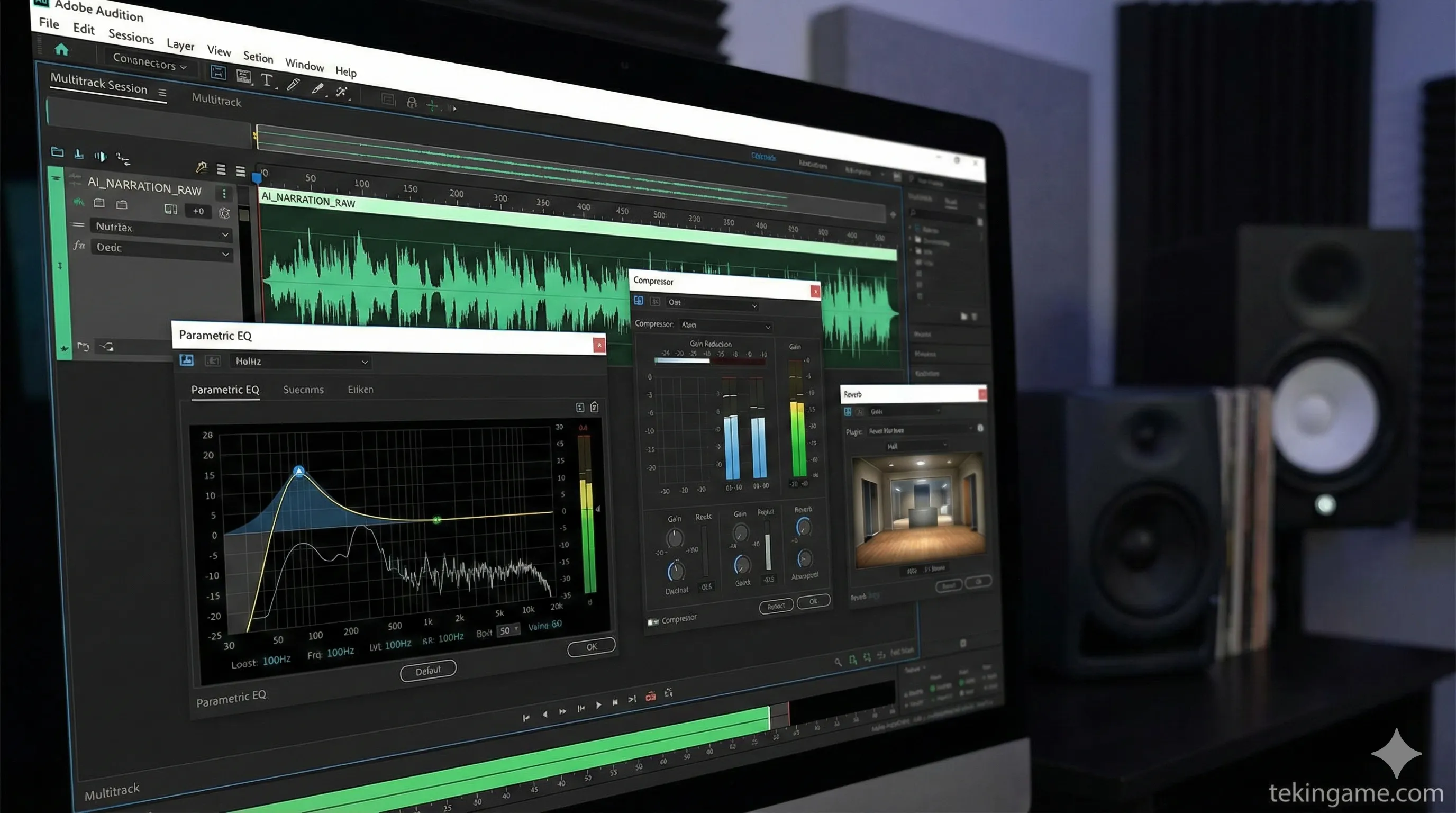
5. 🎚️ استودیوی مجازی: آموزش میکس صدا (Post-Processing)
اینجا جایی است که آماتورها از حرفهایها جدا میشوند. صدای خروجی از هوش مصنوعی (Raw) معمولاً "خشک" و "دیجیتالی" است. برای اینکه آن را "سینمایی" کنیم، باید آن را در نرمافزاری مثل Adobe Audition یا Audacity (رایگان) ویرایش کنیم.
زنجیره افکتهای پیشنهادی (Effect Chain):
این افکتها را به ترتیب روی صدا اعمال کنید:
۱. De-Clicking / De-Essing
هوش مصنوعی گاهی صداهای کلیکمانند ریز یا صدای "س" و "ش" تیز (Sibilance) تولید میکند. از فیلتر De-Clicker و De-Esser استفاده کنید تا این تیزیها گرفته شود و صدا نرم شود.
۲. Parametric Equalizer (EQ) - مهمترین مرحله!

برای ایجاد صدای مستند، باید منحنی فرکانس را دستکاری کنید:
- High-Pass Filter: فرکانسهای زیر ۸۰ هرتز را حذف کنید (برای حذف هام و نویزهای بم).
- Low-End Boost: فرکانسهای بین ۱۰۰ تا ۲۰۰ هرتز را حدود ۲ تا ۳ دسیبل تقویت کنید. این کار به صدا "وزن" و "گرما" میدهد (همان صدای رادیویی).
- High-End Boost: فرکانسهای بین ۳۰۰۰ تا ۵۰۰۰ هرتز را مقدار خیلی کمی (۱ دسیبل) بالا ببرید تا "شفافیت" (Clarity) کلمات بیشتر شود.
۳. Compression (کمپرسور)
کمپرسور اختلاف بین بلندترین و آرامترین بخشهای صدا را کم میکند. این باعث میشود صدای راوی همیشه "حضور" داشته باشد و زیر صدای موزیک گم نشود. از پریستهای "Voice Over" یا "Broadcast" در نرمافزارتان استفاده کنید.
۴. Reverb (طنین)
هیچکس در خلاء حرف نمیزند. یک ریورب بسیار ملایم (مثلاً ۵٪ Wet) با تنظیمات "Small Room" یا "Studio" به صدا اضافه کنید. این کار باعث میشود صدا طبیعیتر به نظر برسد و خشکی دیجیتالی آن از بین برود.
6. ⚠️ منطقه خطر: اخلاقیات و کپیرایت
تکنولوژی کلونینگ صدا قدرتمند است، اما میتواند خطرناک هم باشد. به عنوان یک خالق محتوای مسئولیتپذیر، باید این خطوط قرمز را بشناسید:
- جعل هویت: استفاده از صدای افراد مشهور برای گفتن حرفهایی که نزدهاند (مخصوصاً در سیاست یا کلاهبرداری) جرم سنگینی است. ElevenLabs و پلتفرمهای دیگر واترمارکهای دیجیتالی نامرئی روی صداها میگذارند که قابل ردیابی است.
- حق کپیرایت صدا: آیا میدانستید صدای یک گوینده بخشی از دارایی اوست؟ اگر برای پروژههای تجاری بزرگ کار میکنید، استفاده از صدای کلون شده یک بازیگر معروف بدون اجازه او میتواند منجر به شکایت حقوقی شود. برای پروژههای یوتیوبی شخصی معمولاً سختگیری کمتر است، اما همیشه محتاط باشید.
- شفافیت با مخاطب: همیشه (تاکید میکنم، همیشه) در توضیحات ویدیو بنویسید که "بخشی از نریشن این ویدیو با هوش مصنوعی تولید شده است". مخاطبان امروزی باهوش هستند و صداقت شما را تحسین میکنند. پنهانکاری فقط باعث بیاعتمادی میشود.
7. جمعبندی بازرس: کدام ابزار برای شماست؟
خب فرماندهان، به پایان این کلاس فشرده رسیدیم. بیایید یک جمعبندی نهایی داشته باشیم تا بدانید کدام مسیر را انتخاب کنید:
✅ مسیر اول: حرفهای و بیدردسر (ElevenLabs)
اگر بودجهای حدود ۵ تا ۲۰ دلار در ماه دارید و میخواهید بدون درگیری فنی، بهترین صدای فارسی ممکن را با احساسات دقیق و قابلیت Speech-to-Speech داشته باشید، شک نکنید. ElevenLabs پادشاه فعلی است و در وقت شما صرفهجویی میکند.
✅ مسیر دوم: خلاقانه و اقتصادی (OpenVoice / MyShell)
اگر نمیخواهید هزینه کنید، یا میخواهید روی تکنیکهای ترکیبی (استفاده از صدای مایکروسافت و تغییر رنگ آن) کار کنید، این مسیر برای شماست. این روش کمی وقتگیرتر است و نیاز به آزمون و خطا دارد، اما دستتان باز است تا صداهای منحصربهفردی خلق کنید که هیچکس دیگری ندارد.
🎬 اکشن پلن شما برای امروز
همین الان وارد ElevenLabs شوید (نسخه رایگان هم دارد!) و یک پاراگراف از آخرین مقالهای که خواندهاید را به آن بدهید. سعی کنید با گذاشتن (...) مکثهای دراماتیک ایجاد کنید.
به نظر شما کدام صدای ایرانی (دوبلور یا خواننده) بهترین گزینه برای کلون کردن به عنوان "راوی مستند" است؟
در کامنتها بنویسید تا شاید در آموزش بعدی، پروفایل تنظیمات آن را منتشر کنیم! 👇