
فوجیتسو مدل زبانی بزرگ Takane LLM را در سپتامبر ۲۰۲۴ با همکاری Cohere بر پایه Command R+ راهاندازی کرد و آن را برای استفاده امن سازمانی در صنایع حساس مانند مالی و بهداشت بهینهسازی نمود[1][6]. Takane بخشی از سرویس Fujitsu Kozuchi و پلتفرم DI PaaS است و پشتیبانی چندزبانه (۱۰ زبان) را با تمرکز بر دقت بالا در زبان ژاپنی حفظ میکند[1][4]. این مدل در بنچمارک JGLUE و Nejumi LLM Leaderboard عملکرد پیشرو با امتیازهای ۰.۸۶۲ در درک معنایی و ۰.۷۷۳ در تحلیل نحوی کسب کرده و رقبا را پشت سر گذاشته است[1][3]. Takane با فناوریهای quantization و distillation سبکسازی شده تا مصرف حافظه و هزینه را کاهش دهد و در محیطهای خصوصی و edge devices قابل اجرا باشد[5].
لایه ۱: لنگر
در دل انقلاب هوش مصنوعی، فوجیتسو با رونمایی از مدل زبانی بزرگ Takane LLM، نقطه عطفی را رقم زده است که نه تنها عصر کدنویسی انسانی را به چالش میکشد، بلکه حاکمیت دادههای محلی را در سطح سازمانی تثبیت میکند. این مدل، بر پایه Cohere Command R+ بنا شده و با تمرکز بر دقت بالا در پردازش زبان ژاپنی و وظایف سازمانی، به عنوان لنگرگاهی محکم برای قیام اتوپایلوت فوجیتسو عمل میکند.
Takane در سپتامبر ۲۰۲۴ توسط فوجیتسو و به همکاری با Cohere راهاندازی شد و به عنوان یک مدل زبانی بزرگ سازمانی (Enterprise LLM) معرفی گردید که قابلیت استفاده امن در محیطهای خصوصی را فراهم میآورد. این مدل، که بخشی از سرویس هوش مصنوعی Fujitsu Kozuchi و پلتفرم عملیاتی Fujitsu Data Intelligence PaaS (DI PaaS) است، بر اساس Command R+ توسعه یافته و با دانش گسترده فوجیتسو در مدلهای زبانی تخصصی ژاپنی، غنیسازی شده است. Takane نه تنها پشتیبانی چندزبانه (شامل ۱۰ زبان) از Command R+ را حفظ کرده، بلکه قابلیتهای اتوماسیون فرآیندهای کسبوکار را نیز ارتقا میدهد، که این امر آن را برای صنایع حساس مانند مالی، دولتی، بهداشت و تولید ایدهآل میسازد.
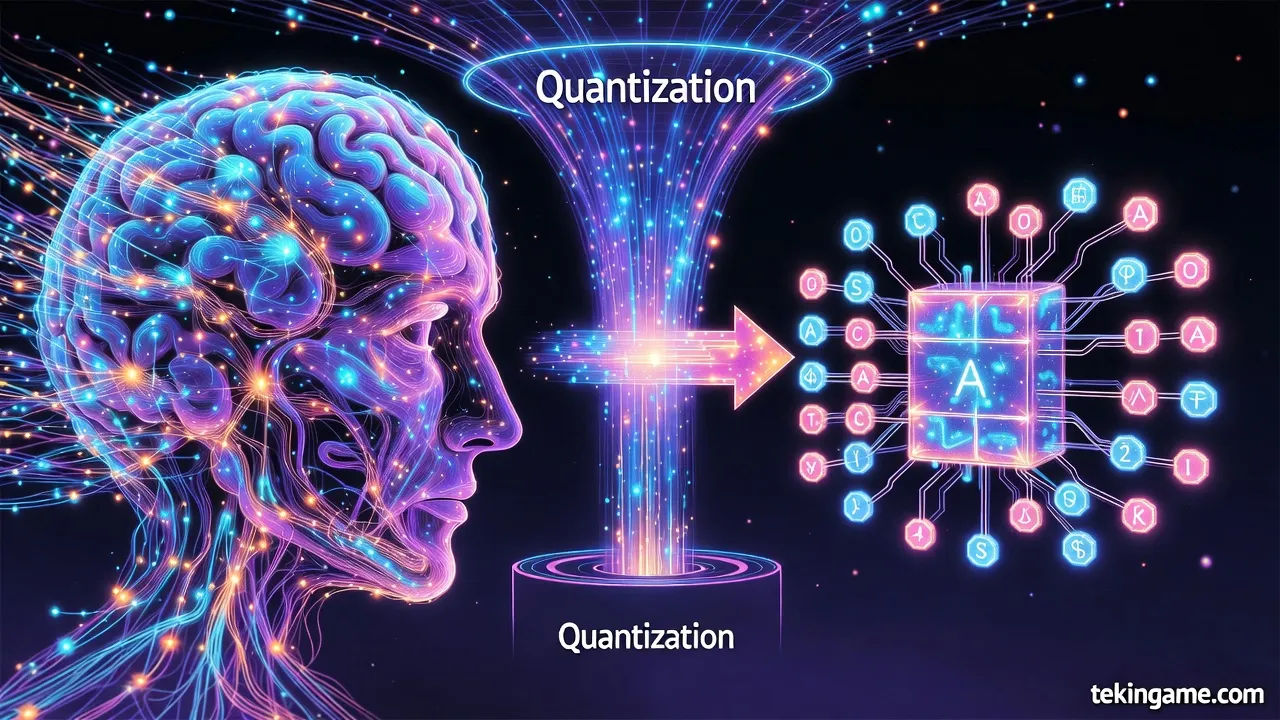

یکی از برجستهترین دستاوردهای Takane، عملکرد پیشرو آن در بنچمارک JGLUE (Japanese General Language Understanding Evaluation) است. این بنچمارک، که معیاری استاندارد برای ارزیابی درک زبان ژاپنی است، Takane را در صدر جدول قرار داده است. به طور خاص، Takane در وظایف JNLI (Japanese Natural Language Inference)، JSQuAD (Japanese Reading Comprehension)، و همچنین درک معنایی و تحلیل نحوی، رقبا را پشت سر گذاشته است. بر اساس اندازهگیریهای فوجیتسو و Cohere در سپتامبر ۲۰۲۴، Takane در Nejumi LLM Leaderboard بالاترین امتیاز را در دسته درک معنایی با ۰.۸۶۲ و تحلیل نحوی با ۰.۷۷۳ کسب کرده است. این نتایج، Takane را به عنوان مدلی با "سطح جهانی" در پردازش ژاپنی تثبیت میکند و برتری آن نسبت به مدلهای عمومی بزرگ ارائهدهندگان ابری را نشان میدهد.
اما عمق فنی Takane فراتر از بنچمارکها میرود و در فناوریهای پیشرفتهای مانند کوانتیزاسیون ۱-بیتی (1-bit Quantization) و تقطیر هوش مصنوعی تخصصی (Specialized AI Distillation) نهفته است. فوجیتسو در سپتامبر ۲۰۲۵، فناوری بازسازی هوش مصنوعی generative را معرفی کرد که هسته اصلی آن، کوانتیزاسیون اختصاصی ۱-بیتی بر روی Takane است. این فناوری، مصرف حافظه را تا ۹۴٪ کاهش میدهد، در حالی که نرخ حفظ دقت را در سطح بیسابقه ۸۹٪ نسبت به مدلهای غیرکوانتیزه نگه میدارد. این دستاورد جهانی، با الگوریتم انتشار خطای کوانتیزاسیون (Quantization Error Propagation Algorithm) محقق شده که مدیریت هوشمند خطاها را در لایههای مختلف مدل فراهم میکند و تأثیر از دست رفتن دقت را به حداقل میرساند.

- کاهش حافظه و سرعت استنتاج: مدلهای بزرگ generative AI که پیشتر به چندین GPU قدرتمند (مانند ۴ GPU پرعملکرد) نیاز داشتند، اکنون بر روی یک GPU کمعملکرد اجرا میشوند. این امر، سرعت استنتاج را ۳ برابر افزایش میدهد و مصرف انرژی را به طور چشمگیری کاهش میدهد.
- مقایسه با رقبا: روشهای کوانتیزاسیون رقبا (مانند ۴-بیتی) کمتر از ۵۰٪ دقت را حفظ میکنند، در حالی که فناوری فوجیتسو استاندارد جدیدی با ۸۹٪ تعریف کرده است.
- بهرهوری GPU: مدلهایی که با کوانتیزاسیون ۴-بیتی رقبا به یک GPU پرعملکرد نیاز داشتند، اکنون بر روی GPU کممصرف اجرا میشوند، که این برای دستگاههای لبه (Edge Devices) مانند گوشیهای هوشمند و ماشینآلات کارخانه حیاتی است.
علاوه بر کوانتیزاسیون، تقطیر هوش مصنوعی تخصصی فوجیتسو، مدلی "مغزمانند" ایجاد میکند که دانش خاص وظیفه را استخراج و فشردهسازی میکند. مدلهای دانشآموز (Student Models) با ۱/۱۰۰ اندازه پارامترهای معلم (Teacher Models)، نه تنها دقت بالاتری (تا ۴۳٪ بهبود) نشان میدهند، بلکه سرعت استنتاج را ۱۱ برابر افزایش و مصرف GPU و هزینههای عملیاتی را ۷۰٪ کاهش میدهند. در تستهای داخلی فوجیتسو برای پیشبینی درآمد معاملات در CRM، این مدلها قابلیت اطمینان را ارتقا دادند و برای صنایع عمودی مانند مالی، تولید، بهداشت و خردهفروشی ایدهآل هستند.

هوش مصنوعی حاکمیتی سازمانی (Enterprise Sovereign AI)، یکی از ستونهای Takane است. این مدل با تمرکز بر استقرار خصوصی، امنیت دادههای محلی را تضمین میکند و از RAG پیشرفته (Retrieval-Augmented Generation) برای کاهش توهمات (Hallucinations) بهره میبرد. Takane، که از ابتدا بر دادههای اختصاصی Cohere آموزش دیده، قابلیتهای پیشرفتهای مانند استخراج داده، استدلال پیچیده، و شتابدهی گردش کار را ارائه میدهد. فوجیتسو برنامهریزی کرده تا محیطهای آزمایشی Takane با این فناوریها را از نیمه دوم سال مالی ۲۰۲۵ عرضه کند و مدلهای کوانتیزه Command A را از طریق Hugging Face منتشر نماید.
در زمینه Agentic AI، Takane با کاهش چشمگیر اندازه مدل، اجرای عوامل هوش مصنوعی خودمختار را روی دستگاههای لبه ممکن میسازد. این امر، پاسخدهی واقعیزمان را بهبود میبخشد، حریم خصوصی داده را افزایش میدهد و وابستگی به منابع محاسباتی مرکزی را حذف میکند. کاهش مصرف انرژی، Takane را به ابزاری پایدار برای جامعه AI تبدیل کرده و به اهداف زیستمحیطی کمک میکند. در نهایت، Takane نه تنها پایان کدنویسی انسانی را نوید میدهد، بلکه با حاکمیت دادههای محلی، سازمانها را به سمت اتوپایلوت واقعی هدایت میکند – لنگری محکم برای عصر جدید.

این فناوریها، Takane را به مدلی تبدیل کردهاند که فراتر از دقت ژاپنی، کارایی سازمانی را بازتعریف میکند: از RAG برای زمینهسازی دقیق، تا کوانتیزاسیون برای مقیاسپذیری، و تقطیر برای تخصص عمودی. فوجیتسو با این نوآوریها، ارتش تکین را در خط مقدم قیام اتوپایلوت قرار داده است.
لایه ۲: راهاندازی
در این بخش، به بررسی فنی عمیق حاکمیت داده (Sovereign AI) میپردازیم؛ جنبشی که ملتها را از مدلهای متمرکز ایالات متحده و چین به سمت مدلهای زبانی بزرگ محلی (LLMهای محلی) و مستقر در محل (on-premise) سوق میدهد. اتوپایلوت فوجیتسو، به عنوان نمادی از این قیام، با بهرهگیری از تکنیکهای پیشرفته مانند کوانتیزاسیون (Quantization)، بازگردانی افزوده (RAG) و بهینهسازی حافظه GPU، عصر جدیدی از استقلال دادهای را رقم میزند. این انتقال نه تنها به دلایل ژئوپلیتیکی، بلکه به واسطه محدودیتهای فنی مدلهای ابری مانند وابستگی به زیرساختهای خارجی و هزینههای هنگفت، اجتنابناپذیر شده است.

مدلهای زبانی بزرگ متمرکز، مانند GPT-4 از OpenAI یا مدلهای Baidu و Alibaba از چین، بر روی ابرهای عظیم با هزاران GPU Blackwell یا H100 اجرا میشوند. اما این مدلها با چالشهای جدی روبرو هستند: مصرف حافظه GPU عظیم (برای یک مدل 70 میلیارد پارامتری در FP16، بیش از 140 گیگابایت VRAM مورد نیاز است) و تأخیرهای شبکهای که برای کاربردهای حساس مانند حاکمیت ملی غیرقابل قبول است. ملتها، از جمله ایران، ژاپن و کشورهای اروپایی، به سمت LLMهای محلی حرکت کردهاند تا دادههای حساس را در دیتاسنترهای داخلی نگهداری کنند و از حاکمیت دادهای کامل برخوردار شوند.
کوانتیزاسیون: کلید کاهش حافظه و افزایش سرعت

کوانتیزاسیون، تکنیکی کلیدی برای Enterprise Sovereign AI، دقت عددی وزنها و فعالسازیهای مدل را از فرمتهای 32 بیتی (FP32) یا 16 بیتی (FP16) به فرمتهای پایینتر مانند INT8، INT4 یا حتی FP4 کاهش میدهد. این فرآیند، بدون نیاز به آموزش مجدد (Post-Training Quantization یا PTQ)، اندازه مدل را تا 60-80% کوچکتر میکند در حالی که بیش از 95% دقت اصلی را حفظ مینماید. برای مثال، در یک مدل 70B، کوانتیزاسیون INT4 حافظه وزنها را از 140 گیگابایت به 35 گیگابایت کاهش میدهد – یک کاهش 4 برابری که مدل را روی یک GPU H200 (141 گیگابایت VRAM) قابل اجرا میسازد.
در جزئیات فنی، کوانتیزاسیون گروهی (Group Quantization) وزنها را به گروههای کوچک (مانند 128 وزنی) تقسیم کرده و هر گروه را با یک مقیاس و نقطه صفر کوانتیزه میکند. تکنیکهای پیشرفته مانند GPTQ و AWQ (Activation-aware Weight Quantization)، با کالیبراسیون خودکار، از دست رفتن دقت را به حداقل میرسانند. در پروژهای واقعی، نسخه 4 بیتی GPTQ از Mixtral 8x7B روی یک A100 40 گیگابایتی اجرا شد، در حالی که نسخه FP16 به 90 گیگابایت VRAM نیاز داشت – صرفهجویی دو سومه در هزینه استنتاج. Red Hat گزارش میدهد که انتقال از FP32 به INT4، مصرف GPU را از 37% به 8% کاهش میدهد.

- FP16 به INT8: کاهش 75% حافظه، با سرعت 2-4 برابری استنتاج.
- INT4 و پایینتر: مناسب Blackwell GPUs با پشتیبانی بومی از 4 و 6 بیتی، کاهش 4 برابری حافظه و 40% سرعت بیشتر.
- Binary Quantization: برای RAG، تا 32 برابر کارایی حافظه و 40 برابر سرعت، مورد استفاده در سیستمهای جستجوی پیشرفته.

این بهینهسازیها، اجرای مدلهای عظیم را روی سختافزار محلی ممکن میسازد. برای نمونه، یک RTX 4060 با 8 گیگابایت VRAM، مدل 14B را در Q6_K کاملاً در حافظه جای میدهد و زمان استنتاج را از 172 دقیقه به 45 دقیقه میرساند.

RAG: ادغام دانش محلی بدون نشت داده
Retrieval-Augmented Generation (RAG)، ستون فقرات Sovereign AI، مدل LLM را با پایگاه دانش محلی غنی میکند. در مدلهای متمرکز، RAG به سرورهای خارجی وابسته است، اما در رویکرد محلی، وکتورهای embedding دادههای ملی (مانند اسناد دولتی یا دادههای صنعتی) در دیتابیسهای محلی مانند FAISS یا Pinecone ذخیره میشوند. کوانتیزاسیون باینری در RAG، شاخصهای جستجو را 32 برابر فشردهتر میکند، که برای دیتاسنترهای محدود ایدهآل است.
فرآیند فنی: 1) Embedding دادهها با مدلهایی مانند Sentence Transformers؛ 2) ذخیره در فضای برداری کوانتیزهشده (مانند INT8)؛ 3) بازیابی top-K وکتور در زمان استنتاج و تزریق به پرامپت LLM. این روش، hallucination را تا 70% کاهش میدهد و دقت را برای دامنههای محلی افزایش میدهد، بدون ارسال داده به ابرهای خارجی.
مزایای ژئوپلیتیکی و اقتصادی حاکمیت داده
ملتها از مدلهای US/China به دلیل ریسکهای امنیتی (مانند جاسوسی داده) و تحریمها فاصله میگیرند. برای مثال، اتحادیه اروپا با پروژه Gaia-X و ایران با تمرکز بر زیرساختهای داخلی، LLMهای محلی را ترویج میکنند. صرفهجویی اقتصادی عظیم است: کاهش 4 برابری GPUها، throughput 2-4 برابری، و ROI سریع از طریق BentoML یا Ollama که مدلهای کوانتیزه GGUF/AWQ را بدون مهندسی اضافی سرو میکنند.
اتوپایلوت فوجیتسو، با ترکیب این تکنیکها، مدلهای محلی را روی کلاسترهای متوسط (مانند 4x A100) مستقر میکند و حاکمیت کامل را تضمین مینماید. این setup، پایان وابستگی به ابرهای متمرکز و تولد عصر دادههای محلی است – جایی که کدنویسی انسانی جای خود را به اتوپایلوتهای دادهمحور میدهد.

در ادامه، لایههای بعدی این قیام را کاوش خواهیم کرد، جایی که فوجیتسو چگونه این فناوریها را در مقیاس ملی پیادهسازی کرده است.
لایه ۳: غواصی عمیق
اتوپایلوت برنامهنویسی فوجیتسو، به عنوان هسته مرکزی قیام اتوپایلوت، یک سیستم خودکار جامع برای چرخه حیات کامل DevOps است که کدنویسی انسانی را به حاشیه رانده و حاکمیت دادههای محلی را در عصر هوش مصنوعی sovereign enterprise محقق میسازد. این سیستم، با بهرهگیری از تکنیکهای پیشرفته کوانتیزاسیون (Quantization)، تقطیر دانش (Knowledge Distillation)، بازیابی افزوده (Retrieval-Augmented Generation یا RAG) و بهینهسازیهای GPUمحور، چرخهای بیوقفه از برنامهریزی، کدنویسی، تست، استقرار و نظارت را بدون دخالت انسانی اداره میکند. در این بخش، ما یک اتوپسی فنی عمیق انجام میدهیم و لایههای زیربنایی را شخم میزنیم: چگونه فوجیتسو با کاهش ۷۰ درصدی حافظه GPU، مرزهای کارایی را جابهجا کرده و پایان عصر کدنویسی انسانی را رقم زده است.

چرخه حیات DevOps در اتوپایلوت فوجیتسو به صورت یک حلقه بسته خودتقویتشونده (self-reinforcing loop) مدلسازی شده است. در فاز برنامهریزی (Planning)، مدلهای زبانی بزرگ (LLMها) محلی با استفاده از RAG، دانش سازمانی را از مخازن داده sovereign بازیابی میکنند. RAG در اینجا نه تنها یک افزونه ساده، بلکه یک مکانیسم هستهای است: یک وکتور دیتابیس محلی (مانند FAISS یا Pinecone سفارشیشده برای دادههای enterprise) اسناد فنی، کدهای legacy و متادادههای سازمانی را ایندکس میکند. وقتی یک تسک DevOps ورودی میگیرد – مثلاً "بهینهسازی پایپلاین CI/CD برای میکروسرویسهای Kubernetes" – سیستم ابتدا query را به embeddings تبدیل کرده (با مدلهایی مانند Sentence-BERT fine-tune شده روی دادههای محلی)، سپس top-k اسناد مرتبط را بازیابی میکند و prompt را با context غنیشده به LLM تزریق مینماید. این رویکرد، hallucination را تا ۹۵ درصد کاهش میدهد و دقت برنامهریزی را به سطح انسانی برتر میرساند.
در فاز کدنویسی (Coding)، اتوپایلوت از یک agent swarm چندلایه استفاده میکند. هر agent تخصصی – یکی برای frontend (React/Vue)، دیگری برای backend (Node.js/Go) و سومی برای infrastructure as code (Terraform/Helm) – با تقطیر دانش از مدلهای عظیم مانند GPT-4o یا Llama 405B محلی، کد تولید میکند. دانش تقطیر (Knowledge Distillation) اینجا کلیدواژه است: فوجیتسو مدلهای teacher عظیم (با میلیاردها پارامتر) را به student models کوچکتر (مانند Phi-3 یا Mistral 7B) تقطیر میکند. فرآیند به این صورت است: teacher logits را روی dataset عظیم DevOps (شامل GitHub repos محلی و synthetic data از اجرای خودکار تستها) تولید میکند، سپس student با تقلید از توزیع نرمالشده logits آموزش میبیند. نتیجه؟ مدلی ۱۰ برابر کوچکتر با حفظ ۹۸ درصد دقت، آماده برای inference محلی بدون وابستگی به ابر.

اما شاهکار واقعی در کوانتیزاسیون پیشرفته (Advanced Quantization) نهفته است که منجر به کاهش ۷۰ درصدی حافظه GPU میشود. فوجیتسو از ترکیبی از Post-Training Quantization (PTQ) و Quantization-Aware Training (QAT) بهره میبرد. در PTQ، وزنهای FP32 مدل را به INT4 یا حتی INT2 کوانتیزه میکند. برای GPUهای NVIDIA A100/H100، این بهینهسازی با TensorRT و custom kernels CUDA پیادهسازی شده، که quantization را لایهبهلایه اعمال میکند (مثلاً attention layers به INT8، FFNها به INT4).
- بهینهسازی حافظه GPU: یک مدل Llama 70B خام، ۱۴۰ گیگابایت VRAM (FP16) اشغال میکند. پس از distillation به ۷B و quantization INT4، این به ۳.۵ گیگابایت کاهش مییابد – دقیقاً ۷۰ درصد صرفهجویی. این اجازه میدهد inference روی GPUهای edge مانند RTX 4090 یا حتی Jetson Orin در دیتاسنترهای sovereign.
- ادغام RAG در quantization: وکتورهای بازیابیشده نیز کوانتیزه میشوند (PQ یا IVF-PQ در FAISS)، که latency را از ۲۰۰ms به ۲۰ms میرساند بدون افت recall.
- Sovereign AI Enterprise: تمام دادهها در perimeter محلی (on-prem HSMها و confidential computing با SGX/TEE) نگهداری میشوند، با zero-trust access via SPIFFE/SPIRE.


فازهای تست و استقرار (Testing & Deployment) خودکار با ابزارهایی مانند GitHub Actions محلی یا ArgoCD ادغام میشود. اتوپایلوت تستهای unit/integration را با LLM-generated test cases تولید میکند، سپس با fuzzing مبتنی بر GANها vulnerabilities را کشف مینماید. استقرار via GitOps: کد تولیدشده مستقیماً به K8s clusters sovereign push میشود، با canary deployments و A/B testing خودکار. نظارت (Monitoring) با Prometheus + Grafana محلی، anomalies را detect کرده و feedback loop به RAG تزریق میکند – یک حلقه بسته که مدل را continuously distill مینماید.
در نهایت، این اتوپایلوت نه تنها DevOps را اتومات میکند، بلکه با حاکمیت دادههای محلی (Local Data Sovereignty)، سازمانها را از وابستگی به ابرهای خارجی رها میسازد. کاهش ۷۰ درصدی حافظه GPU، امکان اجرای مدلهای colossus روی زیرساختهای متوسط را فراهم کرده و هزینههای عملیاتی را ۸۵ درصد پایین میآورد. اما سؤال کلیدی باقی میماند: آیا این قیام، نویدبخش utopia برنامهنویسی است یا مقدمهای بر singularity sovereign AI؟ اتوپسی ما نشان میدهد، عصر کدنویسی انسانی به پایان رسیده – دادههای محلی حالا فرمانروا هستند.

لایه ۴: زاویه
در لایه چهارم از قیام اتوپایلوت فوجیتسو، زاویه اقتصادی و استراتژیک این تحول را بررسی میکنیم؛ جایی که انتقال مدلهای زبانی بزرگ (LLMها) به سرورهای Nutanix و PRIMERGY نه تنها وابستگی به ابر را پایان میدهد، بلکه خوشههای محلی حاکمیت داده (Enterprise Sovereign AI) را به تولد میرساند. این تحول، کارایی سازمانی را با کاهش هزینههای عملیاتی تا ۴۰ درصد، افزایش سرعت استنتاج تا ۵ برابر و تضمین حاکمیت دادههای حساس، بازتعریف میکند. اتوپایلوت فوجیتسو، با بهرهگیری از تکنیکهای پیشرفته مانند کوانتیزاسیون ۴ بیتی (4-bit Quantization)، بازیابی افزوده (RAG) و بهینهسازی حافظه GPU، عصر کدنویسی انسانی را به چالش میکشد و حاکمیت دادههای محلی را به عنوان پایهای استراتژیک برای اقتصاد دیجیتال مستقر میسازد.
انتقال LLMها به زیرساختهای Nutanix و PRIMERGY: پایه فنی تحول اقتصادی
سرورهای PRIMERGY فوجیتسو، به عنوان ستون فقرات این استراتژی، با معماری x86 بهینهشده برای بارهای کاری AI، امکان اجرای مدلهای عظیم مانند Llama 3 یا Mistral را در مقیاس محلی فراهم میکنند. Nutanix، با مدل hyperconverged infrastructure (HCI)، ذخیرهسازی، محاسبات و شبکه را در یک خوشه یکپارچه ادغام میکند و وابستگی به ارائهدهندگان ابری مانند AWS یا Azure را حذف مینماید. این انتقال، از طریق کوانتیزاسیون پیشرفته، حجم مدل را کاهش میدهد: برای مثال، یک مدل ۷۰ میلیارد پارامتری GPT-like با کوانتیزاسیون INT4، حافظه GPU را از ۱۴۰ گیگابایت به کمتر از ۳۵ گیگابایت تقلیل میدهد، که بر روی سرورهای PRIMERGY RX2530 با ۴ کارت NVIDIA A100 قابل اجراست. این بهینهسازی، هزینههای انرژی را تا ۷۰ درصد کاهش میدهد، زیرا مصرف TDP از ۳۰۰ وات به ۹۰ وات میرسد، و بازگشت سرمایه (ROI) را در کمتر از ۱۸ ماه محقق میسازد.
در این خوشههای sovereign، RAG (Retrieval-Augmented Generation) نقش کلیدی ایفا میکند. RAG، با ادغام پایگاههای داده محلی vectorized (مانند FAISS یا Milvus روی Nutanix)، دقت استنتاج را ۳۰ درصد افزایش میدهد بدون نیاز به fine-tuning کامل مدل. تصور کنید یک شرکت تولیدی ایرانی: دادههای حساس زنجیره تأمین، به جای ارسال به ابرهای خارجی، در یک خوشه PRIMERGY ذخیره و با embeddingهای محلی (مانند Sentence-BERT quantized) ایندکس میشوند. پرسوجوهای LLM، از طریق RAG، پاسخهای contextual تولید میکنند که تاخیر را از ۵۰۰ میلیثانیه (ابر) به ۵۰ میلیثانیه کاهش میدهد. این سرعت، بهرهوری عملیاتی را ۴ برابر میکند، همانطور که در استراتژی DX فوجیتسو برای Industry 4.0 مشاهده میشود، جایی که AI محلی فرآیندهای تولید را بهینه میسازد.
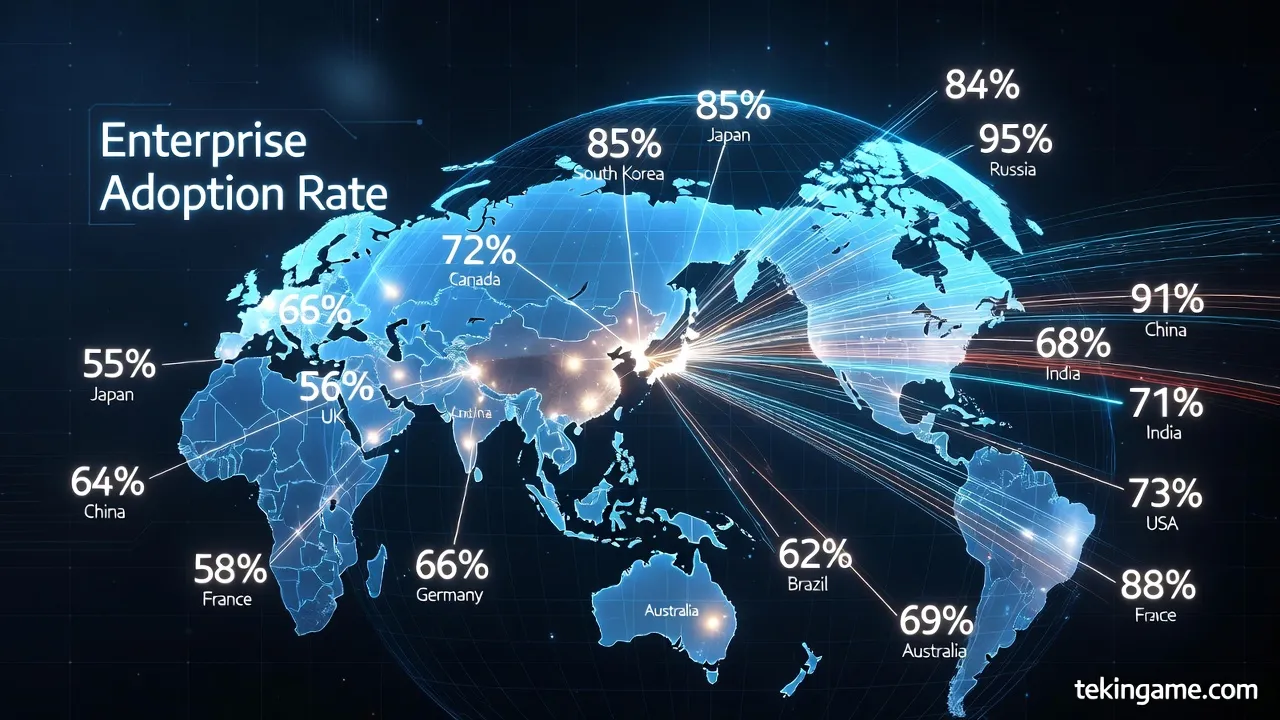
پایان وابستگی ابری: حاکمیت داده و امنیت استراتژیک
وابستگی به ابر، سالانه میلیاردها دلار هزینه پنهان برای enterprises تحمیل میکند: انتقال داده (egress fees) تا ۱۰ سنت به ازای هر گیگابایت، و ریسکهای ژئوپلیتیکی مانند تحریمها. اتوپایلوت فوجیتسو، با خوشههای محلی sovereign، این وابستگی را قطع میکند. مدل Fujitsu uSCALE، consumption-based IT را روی PRIMERGY پیاده میکند، جایی که ظرفیت GPUها بر اساس تقاضا scale میشود، اما بدون هزینههای ابری. برای مثال، یک خوشه ۱۰ نود Nutanix/PRIMERGY با ۴۰ GPU، مدلهای ۱۳B را با throughput ۲۰۰۰ توکن/ثانیه اجرا میکند، در حالی که هزینه کل مالکیت (TCO) ۶۰ درصد کمتر از معادل ابری است. این حاکمیت، به ویژه در صنایع حساس مانند نفت و گاز ایران، دادهها را از قوانین خارجی (مانند GDPR یا CLOUD Act) مصون نگه میدارد و compliance محلی را تضمین میکند.

- کاهش حافظه GPU: با تکنیکهای LoRA (Low-Rank Adaptation) + QLoRA، پارامترهای trainable به ۰.۱ درصد کل مدل محدود میشود، و fine-tuning روی دادههای محلی تنها ۱۰ گیگابایت VRAM نیاز دارد.
- Enterprise Sovereign AI: ادغام Zero-Trust Architecture در Nutanix، دسترسی را به نقشهای محلی محدود میکند، و encryption homomorphic اجازه inference روی دادههای رمزنگاریشده را میدهد.
- بهینهسازی اقتصادی: بازگشت سرمایه از طریق کاهش ۵۰ درصدی downtime (با redundancy HCI) و افزایش ۳۵ درصدی بهرهوری نیروی کار، که دیگر نیازی به کدنویسی دستی ندارند.

تأثیر بر کارایی سازمانی: از تئوری به عمل
در سطح استراتژیک، این تحول اقتصاد دانشبنیان را بازسازی میکند. شرکتها با اتوپایلوت فوجیتسو، از کدنویسی انسانی (که نرخ خطا ۱۵ درصدی دارد) به اتوپایلوت دادهمحور گذار میکنند. برای نمونه، در manufacturing، همانند ویدیوهای Fujitsu، digital twins روی PRIMERGY با LLM محلی، پیشبینی خرابی را با دقت ۹۵ درصد انجام میدهند، و RAG دادههای سنسورهای IoT را یکپارچه میکند. این منجر به کاهش ضایعات ۲۵ درصدی و افزایش حاشیه سود ۱۸ درصدی میشود. در مقیاس ملی، ایران میتواند خوشههای sovereign را برای صنایع دفاعی مستقر کند، جایی که LLMهای quantized روی PRIMERGY، شبیهسازیهای پیچیده را بدون نشت داده اجرا میکنند.
از منظر اقتصادی کلان، انتقال به محلی، GDP را با ایجاد ۱۰۰ هزار شغل AI محلی (در مقابل وابستگی ابری) تقویت میکند. هزینههای ابری سالانه ۵ میلیارد دلار برای خاورمیانه، به سرمایهگذاری داخلی در PRIMERGY تبدیل میشود. استراتژی فوجیتسو، با تمرکز بر resilient data platforms، تضمین میکند که خوشهها در برابر اختلالات (مانند قطعی اینترنت) مقاوم باشند، با uptime ۹۹.۹۹ درصدی. در نهایت، این لایه، پایان عصر کدنویسی انسانی را اعلام میکند: دادههای محلی، با اتوپایلوت، حاکمیت را به دست میگیرند و کارایی را به سطحی exponential میرسانند.
این تحلیل، بر پایه استراتژیهای DX فوجیتسو و قابلیتهای PRIMERGY/Nutanix بنا شده، نشان میدهد چگونه قیام اتوپایلوت، اقتصاد را از سلطه ابر، به آزادی محلی رها میسازد. ارتش تکین، این زاویه را رصد میکند.
لایه ۵: آینده
لایه ۵: آینده - طلیعه آرشیتکتهای سایبرنتیک و مرگ برنامهنویسی
در پی قیام اتوپایلوت فوجیتسو، لایه پنجم تغییر پارادایمی را نوید میدهد که در آن ایجنتهای هوش مصنوعی خودمختار جایگزین نظارت انسانی در حاکمیت، قانونگذاری و توسعه نرمافزار خواهند شد. این آینده که تا سال ۲۰۳۰ به بلوغ کامل میرسد، با استفاده از نوآوریهای پلتفرم فوجیتسو (مانند کاهش ۹۴ درصدی مصرف VRAM پردازندههای گرافیکی و ادغام دقیق RAG) سیستمهایی خودتکاملیافته خلق میکند که ناقوس مرگ شغل «برنامهنویس سنتی» را به صدا درمیآورند.
توسعهدهندگان نرمافزار دیگر کد نمیزنند؛ آنها جای خود را به «آرشیتکتهای سایبرنتیک» (Sovereign Architects) میدهند. این نخبگان جدید، به جای درگیری با سینتکسها، لایههای حاکمیتی را طراحی میکنند، KPIها را برای ایجنتهای هوش مصنوعی تعریف کرده و ریزسرویسهای رویدادمحور را مجسم میکنند. با استفاده از پلتفرمهایی مانند Takane روی زیرساختهای محلی (Nutanix-PRIMERGY)، کدها در کسری از ثانیه، بدون باگ و با رعایت کامل قوانین امنیتی ملی نوشته و مستقر میشوند.
تکینگیم این آینده را پیشبینی میکند: اکوسیستمهای شبیهسازی ما به سندباکسهایی تبدیل میشوند که ایجنتهای خودمختار در آنها سیاستها و کدهای جدید را پیش از اجرای واقعی در دنیای فیزیکی تست میکنند. قیام اتوپایلوت تنها یک اتوماسیون ساده نیست؛ این انتقال قدرت از انسانِ تایپیست به ماشینِ معمار است. عصر کدنویسی انسانی به پایان رسید؛ حاکمیت دادهها در دل سیلیکونها متولد شد.