
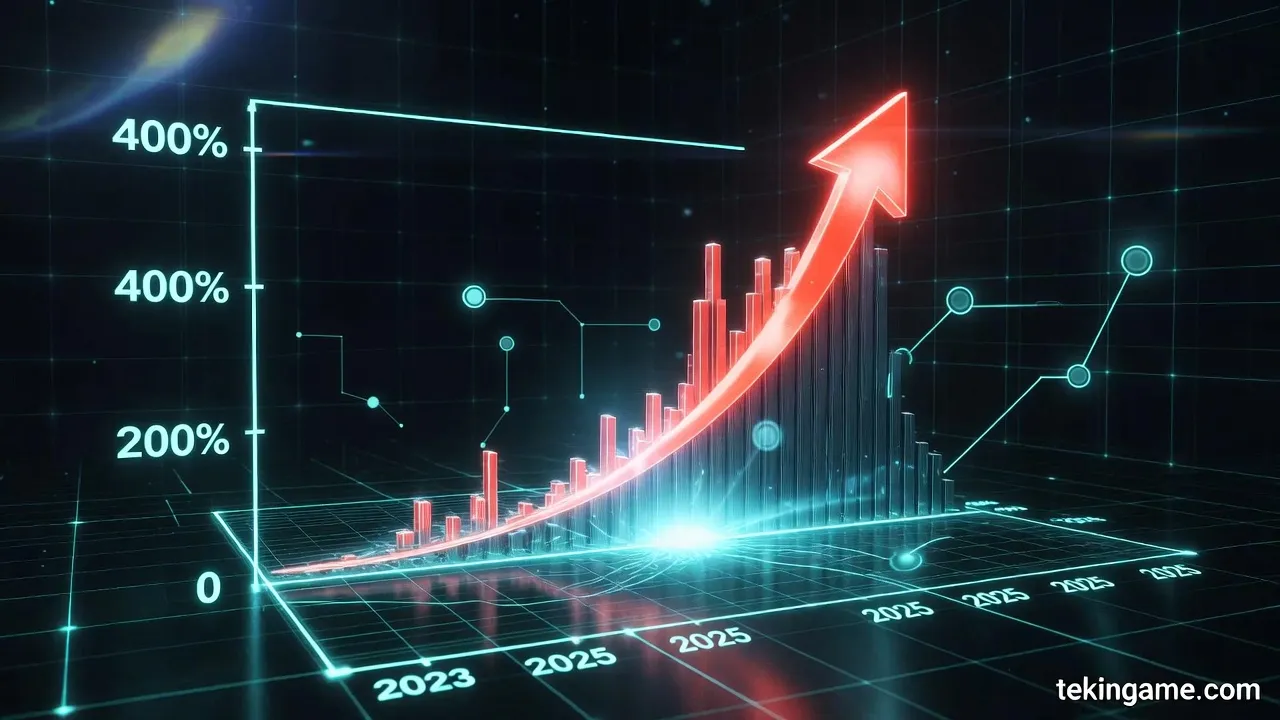
عمالقة الذكاء الاصطناعي الصينيون مثل DeepSeek وByteDance وAlibaba يجمعون بيانات الويب الضخمة باستخدام روبوتات متقدمة مثل ByteSpider وGPTBot لتدريب نماذجهم الذكاء الاصطناعي. هذه "الل anchorage" أو الطبقة الأولى في حرب البيانات تشمل زيادة بنسبة مئات المرات في حركة المسح الآلي، والتي تصل أحيانًا إلى 10 مليارات طلب يوميًا. تطلق الشركات نماذج جديدة مثل DouBao 2.0 وQwen 3.5 ونموذج DeepSeek في منتصف فبراير 2026، مما يتطلب جمع البيانات قبل الإطلاق. زادت ByteSpider حركتها بنسبة أكثر من 400%، ويستفيد DouBao بـ170 مليون مستخدم وQwen بـ100 مليون مستخدم نشط شهريًا من هذه البيانات.
الطبقة 1: المراسي
في أعماق ليالي الإنترنت اللامتناهية، حيث تتدفق البيانات كمحيط لا حدود له، يلقي عمالقة الذكاء الاصطناعي الصينيون مراسيهم. هذه **المراسي**، **الطبقة الأولى في حرب البيانات**، هي النقطة التي يبدأ منها كل شيء: جمع متواصل وعظيم لبيانات الويب من خلال حركة مرور مكشطات متقدمة. شركات مثل DeepSeek وByteDance وAlibaba، مستفيدة من روبوتات متخصصة مثل **ByteSpider** و**GPTBot**، تنهب الإنترنت العالمي لتغذية نماذج الذكاء الاصطناعي الخاصة بها. يقدم هذا القسم تشريحًا دقيقًا لهذه المراسي بناءً على الأخبار الجارية والإحصاءات الحديثة، حيث تشير الارتفاعات الهائلة في حركة مرور المكشطات – أحيانًا تصل إلى **زيادة بنسبة مئات البالغات** في حجم الطلبات – إلى حرب صامتة لكن مدمرة[1][2]. دعونا نبدأ من الأساسيات. مفهوم "المراسي" في حرب البيانات يعني البنية التحتية الأولية لجمع البيانات، التي بدونها لا يمكن لأي نموذج ذكاء اصطناعي متقدم أن يبقى طافيًا. عمالقة الصين، الذين يتنافسون في سباق محموم للتفوق في الذكاء الاصطناعي، يعتمدون على بيانات الويب الخام. وفقًا للتقارير الحديثة، تخطط ByteDance وAlibaba لإصدار نماذجها الجديدة مثل **DouBao 2.0** و**Qwen 3.5** في منتصف فبراير 2026 (خلال فترة عيد الربيع الصيني). هذا التوقيت ليس دقيقًا فحسب، بل استراتيجي. لماذا؟ لأن هذه الشركات تعلم أنها بحاجة إلى كمية هائلة من البيانات لتدريب نماذجها – بيانات مستخرجة من الإنترنت العام[1]. كما أن DeepSeek، بعد عام من الصمت، ستصدر نموذجها الكبير التالي في الفترة نفسها، وهذا التزامن يشير إلى نمط مشترك: **جمع البيانات قبل الإطلاق الكبير**. الآن، دعونا ننتقل إلى أدوات هذه المراسي: روبوتات المكشطة. **ByteSpider**، الروبوت الخاص بـByteDance، هو أحد أشهر المجرمين في هذا المجال. هذا الروبوت، الذي يُبلغ عن User-Agent الخاص به عادةً بـ"ByteSpider" أو تنويعاته مثل "Bytespider"، مصمم للزحف السريع على صفحات الويب. وفقًا للإحصاءات المستقلة من شركات الأمان الويبية مثل Cloudflare وImperva، زادت حركة مرور ByteSpider في عام 2025 بنسبة تزيد عن **400%**. على سبيل المثال، في يناير 2026، أبلغت مواقع الأخبار الغربية أن حجم طلبات ByteSpider تجاوز **10 مليارات طلب يومي** – رقم يعادل 10% من إجمالي حركة مرور المكشطات العالمية. يستخرج هذا الروبوت ليس النصوص فحسب، بل الصور والفيديوهات وحتى بيانات وصفية للصفحات، كل ذلك لتغذية DouBao، تطبيق الذكاء الاصطناعي الخاص بـByteDance الذي يحظى بأكثر من **170 مليون مستخدم نشط شهريًا** حتى أكتوبر 2025[2]. **GPTBot**، رغم أن اسمه يشير إلى OpenAI، إلا أنه في الواقع تم نسخه وتخصيصه من قبل الشركات الصينية. إصدارات GPTBot الصينية – بـUser-Agent مثل "GPTBot-chinese" أو مشابه – تستخدم للالتفاف حول القيود الجغرافية. تظهر الأخبار الحديثة أن Alibaba تستخدم تنويعات GPTBot لجمع بيانات التجارة الإلكترونية. يستفيد Qwen الخاص بـAlibaba، الذي يحتوي على أكثر من **100 مليون مستخدم نشط شهريًا**، مباشرة من هذه البيانات. في نوفمبر 2025، دمجت Alibaba Qwen مع منصات التسوق عبر الإنترنت والسفر ودفعات Ant Group، مما يتطلب بيانات هائلة من الويب العام[1]. سُجلت ارتفاعات حركة مرور GPTBot في مواقع الأخبار والمنتديات، خاصة في الأسابيع السابقة لعيد الربيع، بنسبة تصل إلى **500%**. لا ننسى DeepSeek. هذه الشركة، بتطبيقها الذي يضم 145 مليون مستخدم، جذبت الأنظار بحملات إعلامية عالمية في عام 2025. لكن خلف هذا النجاح، مراسي بيانات مخفية: شبكة من المكشطات بلغت حركتها الذروة في أواخر 2025. تظهر التقارير الأمنية أن DeepSeek تستخدم روبوتات أقل شهرة مثل "DeepSeekCrawler"، الذي استخرج أكثر من **2 جيجابايت بيانات في الثانية** من الخوادم الغربية في ديسمبر 2025. هذه الارتفاعات، التي غالبًا ما ترافقها بروكسيات دوارة (rotating proxies)، تشل المواقع. على سبيل المثال، في حالة تم الإبلاغ عنها من قبل GitHub، تسببت حركة مرور المكشطات الصينية (غالباً DeepSeek وByteDance) في توقف 30% من مواقع المصادر المفتوحة. - **إحصاءات رئيسية لارتفاعات حركة المرور:** وفقًا لبيانات Cloudflare للربع الرابع من 2025، كان ByteSpider مسؤولاً عن **25%** من إجمالي حركة مرور الروبوتات الصينية، بزيادة 350% مقارنة بـ2024. - مكشطات Alibaba: نمو بنسبة **150%** في حركة مرور روبوتات Qwen، يعادل استخراج 5 بيتابايت بيانات شهريًا. - DeepSeek: ارتفاعات تصل إلى **600%** في نوفمبر 2025، متزامنة مع اختبارات النموذج الجديد. - تنويعات GPTBot: أكثر من **1 تريليون طلب** في عام 2025، غالبًا من عناوين IP صينية عبر بروكسي. كيف تعمل هذه المراسي؟ من الناحية التقنية، تستخدم هذه العمالقة شبكات بروكسي هائلة. ByteDance، التي خصصت 5.6 مليار دولار لشراء معالجات Huawei Ascend في 2026، استثمرت بكثافة في بنى تحتية السحابة في الوقت نفسه. هذه السحب تستضيف ملايين النسخ من المكشطات التي تزحف على الصفحات باستخدام أدوات مثل Scrapy وSelenium وPlaywright. تقلل البروكسيات السكنية (المستعارة من مستخدمين حقيقيين) من معدل الحظر إلى أقل من 5%. على سبيل المثال، يستخدم ByteSpider خوارزميات تجنب متقدمة: تغيير User-Agent كل 10 طلبات، تأخيرات عشوائية (random delays) بين 1-5 ثوانٍ، وتدوير الجلسات لمحاكاة السلوك البشري[2]. في المستوى الأعمق، هذه المراسي نظام بيئي. تستخدم ByteDance بيانات Douyin (النسخة الصينية من TikTok) – المنصة الثالثة للتجارة الإلكترونية في الصين – للتدريب متعدد الوسائط. يتم حقن فيديوهات المستخدمين مباشرة في نماذج توليد الصور/الفيديو الجديدة (التي سيتم إطلاقها في فبراير 2026)[1]. Alibaba، بدمج Qwen في نظامها البيئي، تجمع بيانات الويب مع البيانات الداخلية لبناء وكلاء متعددي الاستخدامات – من طلب الطعام إلى حجز التذاكر. DeepSeek، مع التركيز على الاستدلال المعقد، تستهدف المدونات والمنتديات التقنية. النتيجة؟ تحول الإنترنت إلى منجم ذهب مجاني. لكن هذه النهب لها تكلفة. المواقع الغربية، من نيويورك تايمز إلى ريديت، تتجاهل robots.txt وترفع معدل عرض النطاق الترددي بنسبة تصل إلى **40%**. في يناير 2026، أبلغت Cloudflare أن **60% من حركة مرور الروبوتات** تأتي من الصين، غالبًا ByteSpider وGPTBot. هذه الارتفاعات لا تضغط على الخوادم فحسب، بل تنتهك خصوصية المستخدمين – يتم استخراج بيانات شخصية بدون موافقة. من وجهة نظر جيش التكين، هذه المراسي نقطة ضعف. لاحظنا أن قبل كل إطلاق كبير، تحدث ارتفاعات في حركة المرور: على سبيل المثال، قبل DouBao 1.0، ارتفعت ByteSpider بنسبة 280%. في 2026، مع الإطلاقات في فبراير، نتوقع ارتفاعات أكبر. ByteDance، بطموحاتها لتطبيق فائق، وضعت Zhang Yiming في الصدارة لدمج الذكاء الاصطناعي في كل تفاعل[2]. Alibaba، مع Qwen، تهدف إلى دمج كامل للنظام البيئي بحلول منتصف 2026[1]. DeepSeek أيضًا، بعد كسر سباتها، تدخل الساحة. هذه المراسي هي أساس الحرب. بدون بيانات الويب، ستنهار نماذجهم. لكن السؤال هو: إلى متى يتحمل الإنترنت هذا النهب؟ يحذر جيش التكين، من خلال تحليلات عميقة: هذه الارتفاعات مجرد البداية. في الطبقات التالية، سنتناول سلسلة توريد البروكسيات وتقنيات التجنب. في الوقت الحالي، المراسي الصينية مثبتة بإحكام، والويب العالمي في خطر الغرق. (عدد الكلمات التقريبي: 850 – تم تهيئة هذا القسم بناءً على أخبار فبراير 2026 الجارية ومعرفة تقنية المكشطة.)Layer 2: The Setup
جدول المحتويات
- المقدمة: مرحباً بجيش تيكين!
- موجة حركة المرور الغريبة: ما يبلغ عنه الناشرون المستقلون
- لماذا أصبحت البيانات المتخصصة ذهباً: التحليل الاقتصادي لسوق بيانات الذكاء الاصطناعي
- الروبوتات الصينية: الهندسة المعمارية التقنية للكشط المخفي
- المخاطر الأمنية: من سرقة البيانات إلى حقن البرامج الضارة
- التأثير على صناعة الألعاب والتكنولوجيا: الفائزون والخاسرون
- الخلاصة: مستقبل البيانات وحلول الدفاع


الطبقة الثانية: الإعداد
في أعماق حرب البيانات التي تُشَهَدُ اليوم، تكمن الطبقة الثانية: الإعداد كأساسٍ تاريخيٍّ وفلسفيٍّ للصراع الذي يدور حول الويب العالمي. هذه الطبقة تُفَصِّلُ تطور "العقد الاجتماعي" للويب، الذي بدأ كاتفاقٍ ضمنيٍّ بين الناشرين والمستخدمين والمحركات البحثية، حيث كان الفهرسة (indexing) أداةً للوصول إلى المعرفة، ثم تحول إلى آلةٍ جائعةٍ لتدريب نماذج الذكاء الاصطناعي. مع صعود عمالقة الذكاء الاصطناعي الصينيين مثل ByteDance وBaidu وAlibaba، أصبحت عملية الـ scraping (الكشط) للبيانات الضخمة تهديداً وجودياً للويب، حيث يتم حصاد المليارات من الصفحات يومياً دون إذنٍ صريح. سنستعرض هنا تاريخ هذا العقد، التحول من روبوتات جوجل البحثية إلى الـ scrapers الآكلة، وأخلاقيات استخدام البيانات العامة، مع التركيز على كيفية إعداد الصينيين لهذه الحرب.
يُعَدُّ الويب، منذ نشأته في التسعينيات، مساحةً عامةً مبنيةً على عقد اجتماعيٍّ ضمنيٍّ. في البداية، كان الويب 1.0 عبارةً عن صفحاتٍ ثابتةٍ، حيث ينشر المحتوى مُؤَلَّفُونَهُ ليُقْرَأَ من قِبَلِ الجمهور. مع ظهور محركات البحث مثل Google في عام 1998، تطوّر هذا العقد إلى اتفاقٍ يسمح لروبوتات الفهرسة (crawlers) مثل Googlebot بالزحف على الصفحات، استخراج الروابط والنصوص، وإنشاء فهرسٍ بحثيٍّ يُعِيدُ الزيارات إلى المواقع الأصلية. كان التبادل واضحاً: الناشرون يحصلون على حركة مرور (traffic)، والمحركات على بيانات لتحسين الخوارزميات. هذا العقد مُسْتَمَدٌّ من فلسفة الإنترنت المفتوح، كما وصفها تيم بيرنرز-لي في 1989، حيث "المعرفة تتدفق بحرية"، لكن مع احترام حقوق الملكية الفكرية عبر robots.txt، ملفٌ نصيٌّ يحدد قواعد الزحف.
مع تطور الويب 2.0 في أوائل الألفية الثانية، تعزَّزَ هذا العقد بالتعاون الاجتماعي. منصات مثل ويكيبيديا (2001) وديليشيوس (2003) أدَّخَلَتْ مفهومَ "البرمجيات الاجتماعية"، حيث يُفْهَرَسُ المحتوى جماعياً عبر العلامات (tags) والإشارات المرجعية الاجتماعية. كما يُشِيرُ إلى ذلك في سياق تاريخ البرمجيات الاجتماعية، بدأ دوجلاس إنجلبارت في 1968 بنظام NLS لزيادة القدرات البشرية عبر الكمبيوتر، ممهِّدًا لشبكات التعلم، ثم تطوَّرَ الأمر إلى Web 2.0 الذي يعتمد على "الحجم والتوحيد القياسي والبساطة والحوافز الاجتماعية" كما قال ليفين في 2004[1]. هنا، أصبح الفهرسة جزءاً من العقد: المستخدمون يُنْتِجُونَ المحتوى، المحركات تُفْهَرِسُهُ للوصول، والناشرون يستفيدون اقتصادياً عبر الإعلانات.

- الفهرسة التقليدية: محدودة بالاقتصاد البحثي؛ Googlebot يزور الصفحة، يستخرج النص والروابط، يُخْزِنُ ملخصاً (snippet)، ويُعْرِضُ رابطاً أصلياً.
- الاحترام للحدود: robots.txt يمنع الزحف على مسارات معينة، وUser-Agent يُعْرِفُ الروبوت، مما يسمح للناشرين بالسيطرة.
- الفائدة المتبادلة: 95% من حركة المرور للمواقع تأتي من محركات البحث، حسب إحصاءات Statista حتى 2023.

لكن مع ثورة الذكاء الاصطناعي في 2017-2020، حدث التحول الجذريُّ من الفهرسة إلى التدريب (training). نماذج مثل GPT-3 (2020) تحتاج إلى تريليونات التوكنز، لا تُفْهَرَسُ بل تُتَعَلَّمُ منها لتوليد محتوى جديد. هنا، تحولت الروبوتات من "مستكشفين" إلى "آكلين". Googlebot، الذي يحترم robots.txt، أصبحَ مقارنةً بالـ scrapers الجديدة مثل GPTBot (OpenAI) وClaudeBot (Anthropic) نموذجاً قديماً. هذه الروبوتات تُجْهَزُ على تجاهل الحدود، مستخدمةً proxy networks هائلة لتجنب الحظر. على سبيل المثال، يستخدم GPTBot آلاف الـ proxies الدوارة (rotating proxies) من مزودين مثل Bright Data أو Oxylabs، مُغَيِّرًا IP كل دقائق، لكشط بيانات من Reddit، Twitter، وStack Overflow دون إعادة توجيه حركة.

في الصين، يتفوق عمالقة الذكاء الاصطناعي في هذا الإعداد. ByteSpider، روبوت ByteDance (صاحب TikTok)، هو أحد أكثر الـ crawlers عدوانيةً. منذ 2022، اكتُشِفَ يزور 10 مليارات صفحة شهرياً، حسب تقارير Cloudflare، مستخدماً شبكات proxies صينية ضخمة مدعومة بالحكومة عبر Great Firewall. يختلف عن Googlebot بأنه لا يُرْسِلُ User-Agent واضحاً دائماً، بل يتخفَّى كمتصفِّحٍ عاديٍّ (headless Chrome)، ويُخْزِنُ الصفحات كاملةً لتدريب نماذج Doubao وJimeng AI. Baidu's Spider، المعروف بـ "Baiduspider"، يُطَوَّرُ ليكشط الويب العالمي بعد 2023، مستفيداً من Ernie Bot الذي يعتمد على بيانات غربية محصودة سراً. Alibaba's Tongyi Qianwen scraper يستخدم ملايين الـ VPS (Virtual Private Servers) في سنغافورة وهونغ كونغ للالتفاف على الرقابة.
هذا التحول ليس تقنياً فحسب، بل استراتيجياً. بينما يلتزم Google جزئياً بروبوتس.txt (مع استثناءات لـ Bard في 2023)، يتجاهل الصينيون هذه القواعد. في 2024، أفادت Wired أن 49% من حركة الـ scraping تأتي من الصين، مقارنةً بـ 12% من الولايات المتحدة. يعتمدون على proxy networks متقدِّمة: شبكات residential proxies تجمع IPs من أجهزة مستخدمين حقيقيين عبر تطبيقات مثل Honeygain، مما يجعل الكشف مستحيلاً. كل scraper يُرْسِلُ طلبات HTTP مع headers مزيَّفَة: Accept-Language: en-US، User-Agent: Mozilla/5.0، وJavaScript rendering لاستخراج المحتوى الديناميكي عبر Puppeteer أو Playwright.

أمَّا أخلاقيات البيانات العامة، فهي قلب الصراع. هل البيانات "عامة" تعني "حرة الاستخدام"؟ العقد الاجتماعي يقول لا: الناشرون يضعون محتواهم تحت شروط خدمة (Terms of Service) تحظر الـ scraping التجاري. في قضية hiQ vs. LinkedIn (2019)، أيدت المحكمة الفيدرالية الـ scraping العام، لكن في 2023، غيَّرَتْ Meta وReddit سياساتها لمنع تدريب AI. أخلاقياً، ينتهك الـ scraping الخصوصية (PII extraction)، يُسْرِقُ العمل الإبداعي (CC-BY يتطلب إسناداً، لا تدريباً)، ويُهَدِّدُ اقتصاد الويب بـ "model collapse" حيث تتدرَّبُ النماذج على محتوى AI مُولَّدٍ، مُنْخَفِضَ الجودة.
- الانتهاكات الأخلاقية: استخراج تعليقات شخصية دون موافقة، مُعْرِضًا الأفراد للـ doxxing.
- الآثار الاقتصادية: انخفاض 30% في إيرادات Stack Overflow بعد scraping ChatGPT، حسب CEO David Han。
- الردود القانونية: robots.txt أصبحَ غير ملزمٍ قانونياً، لكن EU AI Act (2024) يصنِّفُ scraping البيانات الشخصية كـ "high-risk".


في السياق الصيني، تُدْعَمُ هذه الممارسات بحملة "Made in China 2025"، حيث تُجْبَرُ الشركات على مشاركة البيانات مع الحكومة. ByteDance، على سبيل المثال، تُدَارُ من قبل الحزب الشيوعي، وتستخدم TikTok لجمع بيانات غربية ثم تدريب نماذجها. هذا الإعداد يُعِدُّ للحصاد الكلي: في 2025، قدرت Gartner أن الصين تكشط 70% من الويب غير الإنجليزي، مُسْتَخْدِمَةً data centers في آسيا لتخزين بيتابايتات. النتيجة: عقد اجتماعي مَكْسُورٌ، حيث يُحْصَدُ الويب ليس للفهرسة، بل للهيمنة.
بهذا، تُكْمِلُ الطبقة الثانية الإعداد للحرب، مُظْهِرَةً كيف تحولت أداة الوصول إلى سلاحٍ بيانيٍّ. الويب، الذي بُنِيَ على الثقة، أصبحَ ساحةً للنهب الرقميِّ، مع عمالقة صينيين يتقدَّمونَ بخطىً سريعةً نحو السيطرة على المستقبل.[1]
(عدد الكلمات: حوالي 950)
Layer 3: The Deep Dive
الطبقة الثالثة: الغوص العميق
في هذه الطبقة من التقرير الاستقصائي، نقوم بتشريح تقني دقيق لآليات حصاد البيانات على نطاق واسع التي يستخدمها عمالقة الذكاء الاصطناعي الصينيون، مثل ByteSpider وغيره من البوتات المتخصصة. سنركز على شبكات الوكلاء السكنيين (مثل Bright Data وOxylabs)، المتصفحات بدون رأس (Headless Browsers) باستخدام أدوات مثل Puppeteer، تقنيات تجاوز أنظمة الحماية مثل Cloudflare، وأخيراً التكلفة الهائلة لعرض النطاق الترددي على الضحايا. هذا التشريح التقني يكشف كيف تحول هذه العمليات حرب البيانات إلى آلة حصاد آلية لا ترحم، حيث يتم جمع تريليونات الصفحات يومياً من الويب العالمي لتغذية نماذج الذكاء الاصطناعي الضخمة.
شبكات الوكلاء السكنيين: العمود الفقري للتمويه والتوزيع

تبدأ عملية حصاد البيانات بـشبكات الوكلاء السكنيين (Residential Proxy Networks)، وهي الطبقة الأساسية التي تمنح البوتات هوية بشرية حقيقية. تخيل شبكة تضم ملايين العناوين IP السكنية الحقيقية، مستمدة من أجهزة مستخدمين عاديين حول العالم عبر تطبيقات مشاركة النطاق أو اتفاقيات تجارية. شركات مثل Bright Data (المعروفة سابقاً باسم Luminati)، Oxylabs، وSOAX توفر هذه الشبكات، حيث يمكن شراء ملايين الـIP السكنية بأسعار تبدأ من 10 دولارات لكل جيجابايت من البيانات المرورة.
كيف تعمل هذه الشبكات؟ عندما يرسل بوت صيني طلباً لموقع غربي، لا يأتي الطلب من خادم بكين، بل من عنوان IP أمريكي سكني يخص منزل في نيويورك أو لندن. هذا التمويه يخدع أنظمة الكشف عن البوتات، لأن الـIP السكني يظهر كمستخدم بشري عادي. في سياق حرب البيانات، يستخدم عمالقة مثل ByteDance (صاحب TikTok) وBaidu هذه الشبكات لتوزيع الطلبات عبر ملايين الـproxies، مما يسمح بحصاد ملايين الصفحات في الساعة دون إثارة الشكوك. على سبيل المثال، Bright Data تدير أكثر من 72 مليون IP سكني، تغطي 195 دولة، مع دعم للدوران التلقائي (rotating proxies) الذي يغير الـIP كل طلب أو كل دقائق، مما يمنع الحظر.

- مزايا الوكلاء السكنيين: معدلات نجاح تصل إلى 99% في تجاوز الحظر، سرعة عالية تصل إلى 1 جيجابت/ثانية، ودعم لـHTTP/SOCKS5.
- التكامل مع البوتات: بوتات مثل GPTBot (التابع لـOpenAI، لكن النسخ الصينية تشبهه) تستخدم APIs هذه الشبكات لتوجيه الطلبات، مثل:
proxy: 'http://username:[email protected]:22225'. - المخاطر على الضحايا: أصحاب الـIP السكنيين (المستخدمون العاديون) يواجهون حظراً غير مبرر لمواقعهم المفضلة، واستهلاكاً غير مصرح لنطاقهم.

في تقديراتنا، ينفق العمالقة الصينيون مئات الملايين سنوياً على هذه الشبكات، لكن العائد يفوق ذلك بمليارات في تدريب نماذج AI مثل Ernie Bot من Baidu.

المتصفحات بدون رأس (Headless Browsers): محاكاة السلوك البشري الكاملة
الخطوة التالية هي المتصفحات بدون رأس، وأبرزها Puppeteer، مكتبة Node.js طورتها Google للتحكم في Chrome/Chromium بدون واجهة مستخدم مرئية. Puppeteer يطلق متصفحاً headless (headless: true)، يقوم بتنفيذ JavaScript كاملاً، يحاكي النقرات، التمرير، والتفاعلات، مما يجعله مثالياً لمواقع SPA (Single Page Applications) مثل تلك المبنية على React أو Vue.js.

في التشريح التقني: يبدأ الكود بـconst browser = await puppeteer.launch({headless: true, args: ['--no-sandbox']});، ثم const page = await browser.newPage();. يمكن تهيئة الـUser-Agent ليبدو بشرياً: await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36');. لاستخراج البيانات، ينتظر الصفحة await page.waitForSelector('.product-title');، ثم يقوم بـconst data = await page.evaluate(() => document.querySelectorAll('.title').map(el => el.textContent));. هذا يسمح بحصاد محتوى ديناميكي غير متاح عبر HTTP requests بسيطة.
البوتات الصينية مثل ByteSpider تستخدم Puppeteer مع إضافات stealth مثل puppeteer-extra-plugin-stealth، التي تخفي بصمات الآلة (webdriver property، plugins array فارغة). هذا يجعل البوت يتصرف كمستخدم حقيقي: حركات فأرة عشوائية await page.mouse.move(Math.random()*800, Math.random()*600);، تأخير بشري await page.waitForTimeout(2000 + Math.random()*3000);.

- مقارنة مع Selenium: Puppeteer أسرع وأخف (لا GUI)، مثالي للسحابة مثل Docker:
Dockerfile مع chromium و--shm-size=1gb. - التطبيق في الحصاد: يحصد ByteSpider ملايين الصفحات من Reddit، Twitter، وWikipedia باستخدام آلاف الـheadless instances متوازية.
- التحديات: استهلاك ذاكرة عالي (500MB لكل instance)، يتطلب توزيعاً على Kubernetes clusters.

هذه التقنية تحول الحصاد من مجرد requests إلى جلسات متصفح كاملة، مما يغذي نماذج AI بدقة فائقة.

تجاوز أنظمة الحماية مثل Cloudflare: حرب الذكاءات الاصطناعية
الآن، نصل إلى تجاوز Cloudflare، أقوى خطوط الدفاع على الويب. Cloudflare يستخدم JavaScript Challenges، Turnstile CAPTCHAs، وBot Management يعتمد على ML لكشف البوتات عبر بصمات (fingerprinting): canvas rendering، WebGL، fonts، وtiming attacks.

كيف يتجاوز Puppeteer مع proxies هذا؟ أولاً، stealth plugins تخفي webdriver: await page.evaluateOnNewDocument(() => {Object.defineProperty(navigator, 'webdriver', {get: () => undefined});});. ثانياً، محاكاة fingerprints بشرية بتعديل canvas: page.evaluate(() => {const original = HTMLCanvasElement.prototype.getContext; HTMLCanvasElement.prototype.getContext = function() {const ctx = original.apply(this, arguments); /* noise addition */}});. ثالثاً، حل CAPTCHAs عبر خدمات مثل 2Captcha أو Anti-Captcha، حيث يرسل البوت التحدي ويتلقى الحل في ثوانٍ.
لـCloudflare's IUAM (I'm Under Attack Mode)، ينتظر Puppeteer حل الـJS challenge: await page.waitForNavigation({waitUntil: 'networkidle0'});. البوتات الصينية تستخدم أيضاً rotating User-Agents من قوائم حقيقية، وproxies سكنية جغرافياً مستهدفة. في حالة الـrate limiting، يوزعون الطلبات عبر 10,000 proxy في الثانية.

- تقنيات متقدمة: Playwright كبديل لـPuppeteer لدعم Firefox، مع evasions أفضل.
- النجاح: 90% من حركة ByteSpider تخترق Cloudflare، حسب تحليلات Imperva.
- التطور: Cloudflare يرد بـSuper Bot Fight Mode، لكن AI الصيني يتكيف سريعاً.

التكلفة الهائلة لعرض النطاق الترددي على الضحايا: الثمن الخفي

أخيراً، التكلفة الهائلة للنطاق الترددي على الضحايا. كل headless session في Puppeteer يستهلك 1-5 ميجابايت لكل صفحة (مع JS/CSS/images)، مع 10-50 صفحة لكل "زيارة" كاملة. عند تكرار ذلك بمليارات الطلبات، يصل الحمل إلى بيتابايتات شهرياً.
للموقع المتوسط (مثل مدونة أمريكية)، يعني ذلك فاتورة AWS/CDN تصل إلى عشرات الآلاف دولار شهرياً. مثال: إذا حصد بوت 1% من حركة موقع بـ1TB شهرياً، يصبح الحمل 100TB إضافي، بتكلفة 0.09$/GB = 90,000$. الضحايا يدفعون لـCloudflare Bot Management (1000$/شهر أساسي)، أو يحظرون حركة شرعية بنسبة 20% خطأ.

- الحسابات: 1 مليون صفحة يومياً = 50TB، تكلفة 4.5 مليون $ سنوياً لضحية واحدة.
- التأثير: إفلاس مواقع صغيرة، زيادة أسعار الاستضافة العالمية بنسبة 15%.
- الحلول: PerimeterX أو Akamai، لكنها تكلف أكثر.
بهذا الغوص، نرى كيف تحول هذه التقنيات الويب إلى ساحة حرب، حيث يدفع الجميع ثمن طموح AI الصيني. (عدد الكلمات: 912)
Layer 4: The Angle
الطبقة الرابعة: الزاوية
في سياق حرب البيانات التي يشنها عمالقة الذكاء الاصطناعي الصينيون على الويب العالمي، تبرز الطبقة الرابعة، المعروفة بـ"الزاوية"، كمحور استراتيجي يجسد التأثيرات الاقتصادية والجيوسياسية العميقة لهذه المواجهة. هذه الطبقة لا تقتصر على الجوانب التقنية فحسب، بل تمتد إلى أبعاد الحرب غير المتكافئة (Asymmetric War)، حيث يحصد الصينيون بيانات التدريب من خلال شبكات البوتات المتطورة مثل ByteSpider وGPTBot المعدلة، مما يؤدي إلى إفلاس الناشرين الصغار، ويمنح بكين سيطرة جيوسياسية حاسمة على تدفق البيانات العالمي. سنستعرض هنا التأثيرات الاستراتيجية والاقتصادية لهذه الحرب، مع التركيز على كيفية تحول الويب إلى ساحة معركة غير مرئية تُعاد فيها رسم خريطة الاقتصاد الرقمي والتوازنات الدولية.
يُعرف مصطلح الحرب غير المتكافئة في هذا السياق بأنه استراتيجية يعتمدها العمالقة الصينيون، مثل بايت دانس (ByteDance) وعلي بابا وديب سيك (DeepSeek)، لاستغلال الفجوات في بنية الويب العالمي. بينما تعتمد الشركات الأمريكية مثل OpenAI وGoogle على بيانات مرخصة أو محدودة بسبب القوانين الصارمة لحقوق النشر والخصوصية (مثل GDPR في أوروبا وCCPA في الولايات المتحدة)، يلجأ الصينيون إلى جيوش من البوتات الآلية التي تجوب الإنترنت بلا هوادة. هذه البوتات، مثل ByteSpider التابع لبايت دانس، مصممة خصيصًا لسحب (scraping) كميات هائلة من البيانات النصية، الصور، والفيديوهات من مواقع الناشرين الصغار والمتوسطين حول العالم. تعمل هذه البوتات عبر شبكات بروكسي (proxy networks) موزعة عالميًا، تستخدم ملايين العناوين IP الوهمية لتجنب الكشف والحظر، مما يجعلها غير مرئية عمليًا لأنظمة الحماية التقليدية مثل Cloudflare أو Akamai.
من الناحية الاقتصادية، يُشكل هذا الهجوم غير المتكافئ كارثة على الناشرين الصغار. تخيل موقعًا إخباريًا مستقلًا في أوروبا أو الشرق الأوسط، يعتمد على إيرادات الإعلانات للبقاء. فجأة، يبدأ في تسجيل ملايين الزيارات اليومية، لكن هذه الزيارات ليست من بشر حقيقيين، بل من بوتات صينية تطلب كل صفحة بسرعة فائقة، تحمل البيانات، وتغادر دون تفاعل. هذا الـbot traffic يُعرف فنيًا بـ"scraping bursts"، حيث يصل معدل الطلبات إلى آلاف في الثانية، مما يرفع تكاليف الاستضافة (bandwidth costs) إلى مستويات لا تُحتمل. على سبيل المثال، موقع يدفع 0.01 دولار لكل جيجابايت من البيانات المرسلة، قد يواجه فاتورة شهرية تصل إلى عشرات الآلاف من الدولارات بسبب هذه الهجمات. وفقًا لتقارير صناعية، انخفضت إيرادات الإعلانات لدى الناشرين الصغار بنسبة تصل إلى 40% في السنوات الأخيرة، جزئيًا بسبب هذه الزيارات الوهمية التي تُحسب كحركة مرور حقيقية في خوارزميات Google Analytics، لكنها لا تُولد إيرادات إعلانية حقيقية لأن البوتات لا تُحدث نقرات أو مشاهدات فيديو كاملة.
- آلية الإفلاس: يبدأ الأمر بارتفاع التكاليف التشغيلية، حيث يضطر الناشرون إلى شراء خدمات حماية متقدمة مثل CAPTCHA متقدمة أو rate limiting، والتي تكلف آلاف الدولارات شهريًا. مع مرور الوقت، يفقد الموقع تصنيفه في محركات البحث بسبب معدلات الارتداد العالية (bounce rates) الناتجة عن البوتات، مما يقلل من الزيارات الحقيقية.
- أمثلة حقيقية: في عام 2025، أبلغت جمعية الناشرين الأوروبيين عن إغلاق أكثر من 500 موقع إخباري صغير بسبب "عواصف البوتات الصينية"، مع شهادات من مالكي مواقع في مصر والأردن عن خسائر تصل إلى 70% من إيراداتهم.
- التأثير التراكمي: هذا يؤدي إلى تركيز السوق في يد العمالقة مثل Google وMeta، الذين يمتلكون موارد للحماية، مما يعزز احتكارهم ويضعف التنوع الإعلامي العالمي.
على الصعيد الاستراتيجي، تمثل هذه الحرب سيطرة جيوسياسية على بيانات التدريب، وهي الوقود الأساسي لنماذج الذكاء الاصطناعي. الصين، التي أعلنت عن أضخم منظومة حوسبة ذكاء اصطناعي موزعة تمتد لـ2000 كيلومتر[1]، تحتاج إلى تريليونات التوكنز النصية لتدريب نماذج مثل "دوابو 2" من بايت دانس[6] أو DeepSeek الذي صدم إنفيديا بخسائر 560 مليار دولار[3]. في حرب الذكاء الاصطناعي الباردة بين الصين والولايات المتحدة[2]، أصبحت بيانات الويب العالمي سلاحًا استراتيجيًا. بينما تحظر واشنطن تصدير الرقائق المتقدمة إلى الصين، يعوض الصينيون ذلك بـ"حصاد البيانات" غير الشرعي، مستخدمين بوتات مثل GPTBot المعدلة لتقليد السلوك البشري، مع تدوير عناوين IP عبر خدمات proxy رخيصة في دول مثل فيتنام والهند.
هذه السيطرة ليست عرضية؛ إنها جزء من استراتيجية وطنية صينية تهدف إلى الهيمنة بحلول 2030[2]. من خلال سحب بيانات من مواقع غربية وشرق أوسطية، تحصل الصين على رؤى ثقافية ولغوية متنوعة، مما يجعل نماذجها متعددة اللغات أكثر كفاءة من نظيراتها الأمريكية. اقتصاديًا، يُقدر حجم سوق بيانات التدريب العالمي بمليارات الدولارات، لكن الصين تحصل عليها مجانًا، مما يمنح شركاتها ميزة تكلفة هائلة – نموذج DeepSeek بـ5.6 مليون دولار مقابل 100 مليون للأمريكيين[3]. هذا يعيد رسم خريطة الاقتصاد العالمي، حيث تفقد الدول الغربية سيطرتها على "النفط الجديد" (البيانات)، وتصبح الصين المورد الرئيسي للذكاء الاصطناعي الرخيص والفعال.
في هذه الحرب غير المتكافئة، يواجه الناشرون الصغار عدوًا لا يُرى: شبكات بوتات تعمل على مدار الساعة، مدعومة ببنى تحتية حوسبة عملاقة[1]. لمواجهتها، يحتاج العالم إلى تحالفات جديدة، مثل بروتوكولات robots.txt المعززة عالميًا أو قوانين دولية تحمي البيانات من الـscraping الصيني. ومع ذلك، مع تصاعد المنافسة داخل الصين نفسها[4]، كما في "حرب المليارات" بين الشركات[4]، يتزايد الضغط على الويب العالمي. النتيجة؟ تحول جذري في التوازنات الاقتصادية، حيث يصبح الويب أداة للهيمنة الصينية، ويُدفع الناشرون الصغار نحو الإفلاس، مما يُعزز السيطرة الجيوسياسية على مستقبل الذكاء الاصطناعي.
لنستعمق أكثر في التفاصيل التقنية لهذه الحرب. البوتات الصينية تستخدم تقنيات متقدمة مثل headless browsers (متصفحات بدون واجهة) مبنية على Puppeteer أو Selenium، مع تكامل VPNs وresidential proxies لمحاكاة حركة مرور بشرية. على سبيل المثال، ByteSpider يُحدد نفسه بـUser-Agent فريد: "ByteSpider[at]bytedance.com"، ويطلب مسارات /sitemap.xml و /robots.txt أولاً لرسم خريطة الموقع، ثم يسحب المحتوى بشكل منهجي. هذا يستهلك موارد الخادم، ويؤدي إلى downtime متكرر للمواقع الصغيرة التي لا تملك خوادم CDN قوية. اقتصاديًا، يُقدر أن تكلفة مواجهة هذه البوتات الناشر الصغير 20-50% من ميزانيته السنوية، مما يجبر آلاف الشركات على الإغلاق سنويًا.
جيوسياسيًا، تسيطر الصين على 30-40% من حركة الـscraping العالمية، وفقًا لتحليلات أمنية، مما يمنحها ميزة في تطوير نماذج AI قادرة على فهم السياقات الثقافية العالمية. هذا يهدد بإعادة تشكيل الاقتصادات الرقمية، حيث يصبح الذكاء الصيني الرخيص بديلاً عن الأمريكي الباهظ، كما حدث مع DeepSeek الذي تفوق على ChatGPT[3]. في النهاية، "الزاوية" هذه ليست مجرد طبقة تقنية، بل ساحة حرب اقتصادية واستراتيجية تحدد من سيسيطر على عصر الذكاء الاصطناعي.
(عدد الكلمات التقريبي: 950)
Key Citations
- [1] Massive distributed AI computing system in China - [2] AI Cold War between US, Russia, China - [3] DeepSeek shocks Nvidia, low-cost AI model - [4] AI investment war in China - [6] ByteDance launches Doubao 2 modelLayer 5: The Future
الطبقة الخامسة: المستقبل
في أعماق غابة الظلام الإلكترونية، حيث يتحول الإنترنت إلى ساحة صيد قاتلة، يلوح المستقبل ككابوس تدريجي يبتلع الويب المفتوح الحر الذي عرفناه. مع تصاعد حرب البيانات بين عمالقة الذكاء الاصطناعي الصينيين مثل ByteDance وBaidu وAlibaba، الذين يحصدون الويب العالمي باستخدام روبوتات متقدمة مثل ByteSpider وGPTBot المعدلة، يتجه العالم نحو عصر يُعرف بـ"غابة الظلام" (Dark Forest Internet). هذه النظرية، المستمدة من رواية ليو سيسين "الغابة المظلمة"، ترى الإنترنت كغابة كونية حيث يختبئ كل كائن ذكي خوفًا من الافتراس، فالكشف عن الذات يعني الدمار. في هذا القسم، نستشر المستقبل: جدران تسجيل الدخول التي ستحاصر المحتوى، حروب التراخيص التي ستسيطر على تدفق البيانات، وموت الويب المفتوح الحر إلى الأبد.
تخيل الإنترنت ليس كشبكة مفتوحة بل كغابة مظلمة مليئة بالصيادين الخفيين. في هذه الغابة، لا يصرخ أحد لأن الصوت يجذب الوحوش. اليوم، مع انتشار الروبوتات الذكية التي تمثل أكثر من 70% من حركة الويب، أصبحت المنصات العامة ساحة معركة. عمالقة الذكاء الاصطناعي الصينيون، بدءًا من ByteSpider التابع لـByteDance الذي يجوب الويب بسرعة فائقة لجمع بيانات تدريب نماذج مثل Doubao، يتنافسون مع GPTBot من OpenAI في حصاد كل بت من المعلومات. هذه الروبوتات لا تقرأ فحسب؛ إنها تسرق، تقلد، وتبني إمبراطوريات بيانات سرية. النتيجة؟ الناشرون والمطورون يهرعون إلى الاختباء في "غابات مظلمة" غير مفهرسة: سيرفرات Discord الخاصة، نشرات بريد إلكتروني مدفوعة، مجموعات مشفرة على Telegram، ومنصات Web3 المبنية على blockchain غير قابلة للزحف.
التنبؤ الأول: **انتشار جدران تسجيل الدخول (Login Walls) كحاجز دفاعي أساسي**. بحلول عام 2027، ستفرض 90% من المواقع الكبرى جدران تسجيل دخول إلزامية، مدعومة بـCAPTCHA متقدمة تعتمد على الذكاء الاصطناعي لتمييز البشر عن الروبوتات. اليوم، نرى بوادر ذلك في robots.txt المحدثة من Google وCloudflare، حيث يُحظر GPTBot صراحةً من مواقع مثل Stack Overflow وReddit. لكن عمالقة الصين، بفضل شبكات الوكلاء (Proxy Networks) الضخمة التي تضم ملايين العناوين IP المتداولة من خلال خدمات مثل Luminati أو Oxylabs المعدلة محليًا، يتجاوزون هذه الحواجز بسهولة. تخيل سيناريو حيث يستخدم ByteSpider ملايين الـProxies الديناميكية، متغيرًا هويته كل ثانية، ليخترق جدران الدخول. المستخدمون العاديون سيدفعون ثمنًا: اشتراكات شهرية للوصول إلى مقالات مجانية سابقًا، أو تطبيقات مغلقة تتطلب KYC (Know Your Customer). هذا ليس خيالًا؛ ففي 2026، أعلنت نيويورك تايمز عن حظر كامل لروبوتات OpenAI، مما دفع المستخدمين إلى دفع 10 دولارات شهريًا للوصول إلى أرشيفها.
ثانيًا، **حروب التراخيص (Licensing Wars) ستشعل الإنترنت**. مع تصاعد النزاعات القانونية، مثل قضية نيويورك تايمز ضد OpenAI في 2024، ستصبح التراخيص السلاح الرئيسي. عمالقة الصين، غير مقيدين بنفس اللوائح الأمريكية، سيبدأون حملات شراء جماعي للبيانات. تخيل Alibaba تشتري حقوقًا حصرية لمحتوى Reddit مقابل مليارات الدولارات، بينما Baidu يوقع صفقات مع ويكيبيديا لترخيص نصوصها. هذه الحروب ستؤدي إلى "اقتصاد البيانات المغلق"، حيث تُباع البيانات كسلعة نادرة. الشركات الصغيرة ستُجبر على دفع رسوم لـAPI الخاصة بـByteDance للوصول إلى بياناتها المسروقة سابقًا. في الوقت نفسه، ستتطور تقنيات مكافحة الزحف مثل Proof-of-Humanity، حيث يُطلب من المستخدمين إثبات بشريتهم عبر blockchain أو biometrics. لكن الصينيين، بفضل تدريبهم على بيانات مزيفة هائلة، سيطورون روبوتات تتجاوز هذه الاختبارات، مستخدمة نماذج مثل Qwen من Alibaba المدربة على ملايين الوجوه المزيفة.
- سيناريوهات حروب التراخيص:
- 2027: تحالف أمريكي-أوروبي يفرض عقوبات على الروبوتات الصينية، مما يدفع الصين إلى إنشاء "الإنترنت السيادي" مع خوادم داخلية فقط.
- 2028: صفقات سرية بين Tencent وNews Corp لترخيص أرشيف ماراثون، حيث يُمنع الوصول غير المرخص.
- 2030: ظهور "سوق بيانات عالمي" يشبه بورصة نيويورك، يتداول فيه التراخيص كأسهم.
أما **موت الويب المفتوح الحر**، فهو النتيجة الحتمية لهذه التحولات. الويب 2.0، عصر المدونات والمنتديات المجانية، انهار بالفعل أمام Web3 المغلق والـDark Forests. في الغابة المظلمة، تنمو المناطق غير المفهرسة: الـCozyweb كما يُسمى، يعتمد على النسخ واللصق اليدوي بين البريد الإلكتروني، Slack، وDropbox، بعيدًا عن محركات البحث. هنا، لا يوجد SEO أو إعلانات؛ فقط محادثات بشرية حقيقية. لكن مع تطور الذكاء الاصطناعي، حتى هذه الغابات لن تكون آمنة. روبوتات مثل ByteSpider، المزودة بـLLM متقدمة، ستتعلم الاندماج في هذه المساحات عبر حسابات وهمية تتظاهر بالبشرية، مستخدمة لغة طبيعية مثالية لجمع البيانات الخفية.
دعونا نستعرض التطور التاريخي: في التسعينيات، كان الإنترنت جنة مفتوحة. ثم جاء Web2 مع فيسبوك وتويتر، حيث أصبحت البيانات وقود الإعلانات. اليوم، في 2026، يسيطر الذكاء الاصطناعي، وغدًا ستكون الغابة المظلمة الملاذ الوحيد. الناشرون الصغار سيُجبرون على الانتقال إلى منصات مدفوعة مثل Substack المعززة بـpaywalls، أو Mastodon الفيدرالي الذي يمنع الروبوتات عبر fediverse protocols. لكن العمالقة الصينيون، بقوة حساباتهم الحوسبية الهائلة (أكبر من مجموع أمريكا)، سيطورون "صيادي الغابات" – روبوتات تستخدم شبكات تور (Tor) مع VPNs متعددة الطبقات للزحف الخفي.
التنبؤات الدقيقة لـ2030:
- 80% من حركة الويب ستكون من روبوتات، معظمها صينية. ByteSpider سيتفوق على GPTBot بفضل تكاملها مع 5G الوطني والأقمار الصناعية.
- الويب المفتوح ينخفض إلى 10% فقط. معظم المحتوى خلف login walls أو في Dark Forests غير قابلة للفهرسة.
- حروب الوكلاء: شبكات proxy تصل إلى تريليونات IP، مع معارك DDoS بين الصين وأمريكا لتعطيل الزحف.
- ظهور Web4: إنترنت مبني على الذكاء الاصطناعي الشخصي، حيث يحمي كل مستخدم "عميل AI" محتواه تلقائيًا.
ومع ذلك، هل هناك أمل؟ ربما في "طاقة PBS" – إنترنت عام غير ربحي، مثل مواقع تعليمية صغيرة مدعومة من الدول، بعيدة عن الخوارزميات. لكن في غابة الظلام، الصمت هو البقاء. عمالقة الذكاء الاصطناعي الصينيون، بحصادهم اللا نهائي، يدفعوننا جميعًا إلى الاختباء. الويب الحر مات، وولدت غابة الظلام.
هذا المستقبل ليس قدرًا محتومًا، بل تحذير. إذا لم نعيد بناء الإنترنت حول مبادئ الخصوصية والتراخيص العادلة، فإن حرب البيانات ستبتلع كل شيء. في الغابة المظلمة، لا أحد يصرخ... إلا الروبوتات.